KinD(Kubernetes in Docker)를 이용한 K8S 클러스터 구축
K8S를 실제 운영서버에 설정해보기 전에 K8S가 어떤 것인지 알아보며 로컬 환경에서 K8S를 구축해보려 한다. 로컬 환경에서 구축하는 방법 중 Minikube, KinD(Kubernetes in Docker), Docker Desktop 등을 이용해 로컬 환경에서 Kubernetes를 실행하는 방법이 있으며, 이 중 KinD를 이용해 K8S 클러스터를 구축해보려한다.
K8S(Kubernetes)란?
K8S는 컨테이너화된 애플리케이션을 자동으로 배포, 확장 및 관리하는 오픈소스 컨테이너 오케스트레이션 시스템이다.
핵심 기능 및 특징
- 컨테이너 오케스트레이션:
- 여러 호스트에 걸쳐 컨테이너를 자동으로 배포하고 관리합니다.
- 컨테이너의 생명주기를 관리하고, 필요한 경우 자동으로 재시작하거나 복제합니다.
- 자동 확장 및 복구:
- 트래픽 변화에 따라 컨테이너 수를 자동으로 확장하거나 축소합니다.
- 컨테이너나 호스트에 장애가 발생하면 자동으로 복구하여 애플리케이션의 가용성을 높입니다.
- 서비스 디스커버리 및 로드 밸런싱:
- 컨테이너 간의 통신을 위한 네트워크를 자동으로 구성합니다.
- 트래픽을 여러 컨테이너에 분산시켜 애플리케이션의 성능을 향상시킵니다.
- 스토리지 오케스트레이션:
- 컨테이너에 필요한 스토리지를 자동으로 프로비저닝하고 관리합니다.
- 다양한 스토리지 솔루션을 지원하여 유연한 스토리지 관리를 가능하게 합니다.
- 자동화된 롤아웃 및 롤백:
- 애플리케이션 업데이트를 안전하게 배포하고, 문제가 발생하면 이전 버전으로 롤백합니다.
- CI/CD 파이프라인과 통합하여 애플리케이션 배포를 자동화할 수 있습니다.
- 구성 관리:
- 애플리케이션의 설정을 중앙에서 관리하고, 변경 사항을 자동으로 배포합니다.
- ConfigMap과 Secret을 사용하여 중요한 설정 정보와 비밀 정보를 안전하게 관리합니다.
주요 구성 요소
- 컨트롤 플레인(Control Plane)
- 클러스터의 전반적인 상태를 관리하고, 워크로드를 스케줄링합니다.
- API 서버, 스케줄러, 컨트롤러 관리자, etcd 등의 구성 요소로 이루어져 있습니다.
- 노드(Node)
- 쿠버네티스 클러스터에서 워크로드를 실행하는 물리적 또는 가상 머신입니다.
- 마스터 노드와 워커 노드를 모두 포함하는 개념입니다.
- kubelet, kube-proxy, 컨테이너 런타임 등의 구성 요소로 이루어져 있습니다.
- 파드(Pod)
- 하나 이상의 컨테이너를 묶어서 관리하는 Kubernetes의 기본 배포 단위입니다.
- 서비스(Service)
- Pod 집합에 대한 단일 접근점을 제공하여 네트워크를 통해 접근할 수 있도록 합니다.
- 배포(Deployment)
- Pod의 복제본을 관리하고, 업데이트를 자동화합니다.
세부 구성 요소
- 마스터 노드(Master Node)
- Control Plane 구성 요소들이 실행되는 물리적 또는 가상 서버입니다.
- 하나 이상의 마스터 노드를 사용하여 Control Plane의 가용성을 높일 수 있습니다.
- 마스터 노드는 Control Plane 구성 요소들 외에도 다른 시스템 구성 요소들을 포함할 수 있습니다.
- 워커 노드(Worker Node)
- 실제로 애플리케이션 컨테이너(Pod)가 실행되는 노드입니다.
- 마스터 노드로부터 작업을 할당받아 수행하고, 클러스터의 마스터 노드에게 작업 결과를 보고하는 역할을 합니다.
장점
- 애플리케이션 개발 및 배포 속도 향상: 컨테이너 기반으로 개발, 배포 과정이 간편하고 빨라집니다.
- 리소스 효율성 향상: 필요에 따라 자동으로 리소스를 할당하고 회수하여 리소스 활용도를 높입니다.
- 애플리케이션 가용성 향상: 자동 복구 및 확장을 통해 애플리케이션의 안정성을 높입니다.
- 클라우드 환경에 대한 높은 이식성: 다양한 클라우드 환경에서 동일한 방식으로 애플리케이션을 실행할 수 있습니다.
단점
- 다양한 개념과 구성으로 러닝 커브가 가파르다.
- K8S 클러스터 운영에는 마스터 및 워커 노드에 대한 추가적인 리소스가 필요하여 추가적인 비용이 발생한다.
- 소규모 애플리케이션의 경우 리소스 오버헤드가 부담이 된다.
K8S CLI 도구
Kubelet
K8S에서 Kubelet은 워커 노드(Worker Node)에서 실행되는 에이전트이며 핵심 구성 요소이다. 워커 노드에서 실행되는 컨테이너(Pod)를 실행하고 관리하는 역할을 수행하며, kubelet이 없으면 워커 노드는 Pod를 실행할 수 없으며, 쿠버네티스 클러스터는 정상적으로 작동할 수 없다.
kubelet은 워커 노드의 상태를 마스터 노드에게 보고하여 클러스터의 안정성을 유지하는 데 중요한 역할을 한다.
- Pod 관리:
- kubelet은 마스터 노드(Control Plane)의 API 서버로부터 Pod 생성, 실행, 삭제 요청을 받아 해당 워커 노드에서 Pod를 관리합니다.
- Pod의 상태를 지속적으로 모니터링하고, 문제가 발생하면 자동으로 재시작하거나 복구합니다.
- 컨테이너 런타임과의 상호 작용:
- 컨테이너 런타임(예: Docker, containerd)과 통신하여 컨테이너를 생성하고 관리합니다.
- 컨테이너의 이미지 다운로드, 실행, 중지 등의 작업을 수행합니다.
- 노드 상태 보고:
- kubelet은 워커 노드의 상태(CPU, 메모리 사용량 등)를 마스터 노드에게 주기적으로 보고합니다.
- 이를 통해 마스터 노드는 클러스터의 전체적인 상태를 파악하고 스케줄링 결정을 내릴 수 있습니다.
- 볼륨 관리:
- Pod에 필요한 스토리지를 연결하고 관리합니다.
- Persistent Volume을 사용하여 데이터의 영속성을 보장합니다.
Kubectl
kubectl은 K8S 클러스터를 관리하는 CLI(Command line Interface) 도구이다. Kubernetes API 서버와 통신하여 클러스터 노드 파드(Pod) 서비스(Service) 등을 상태 확인, 배포, 삭제, 로그 확인 등을 확인할 수 있다.
기본 명령어
| 명령어 | 설명 |
|---|---|
| kubectl get nodes | 클러스터 내 노드 목록 |
| kubectl get pods -A | 모든 네임스페이스의 파드 목록 |
| kubectl get services | 서비스 목록 |
| kubectl describe pod | 특정 파드 상세 정보 확인 |
| kubectl logs | 특정 파드의 로그 확인 |
| kubectl exec -it | 파드 내부로 접속 |
| kubectl apply -f <파일명>.yaml | YAML 파일을 이용한 리소스 생성 |
| kubectl delete pod | 특정 파드 삭제 |
| kubectl delete -f <파일명>.yaml | YAML 파일을 이용한 리소스 삭제 |
Kubeadm
kubeadm은 K8S 클러스터 실행과 배포를 도와주는 CLI(Command line Interface) 도구이다. Kubernetes 공식에서 제공하는 방법 중 하나로, 마스터 노드 및 워커 노드를 빠르게 설정할 수 있습니다.
- 마스터 노드 초기화 (
kubeadm init)- API 서버, 컨트롤러 매니저, 스케줄러 및 etcd 설정
- TLS 인증서 및 kubeconfig 생성
- 워커 노드 추가 (
kubeadm join)- 마스터 노드의
kubeadm token을 사용하여 클러스터에 합류
- 마스터 노드의
- 클러스터 설정 검사 및 업그레이드 (
kubeadm upgrade)
Kubernetes의 클러스터 관리를 자동화하지만, 네트워크 플러그인(CNI) 설치는 별도로 필요.
컨테이너 런타임(Container Runtime)
컨테이너 런타임이란 컨테이너를 실행하고 관리하는 도구이며, 컨테이너의 생성, 실행, 중지, 삭제, 네트워크 연결, 리소스 관리(CPU, 메모리) 등의 역할을 갖는다. 컨테이너 자체를 만드는 저수준 런타임과 컨테이너를 논리적으로 실행하는 고수준의 런타임으로 나뉜다.
컨테이너 런타임 종류
저수준 런타임 (Open Container Initative, OCI)
- 컨테이너 실행을 담당하는 가장 기본적인 런타임
- OCI(Open Container Initative) 표준을 따른다.
- 예 :
runCgVisorKata Containers
고수준 런타임(Container Runtime Interface, CRI)
- 쿠버네티스에서 제공하는 컨테이너 런타임 추상화 계층
- Kubernetes 및 Docker 같은 오케스트레이션 툴과 통신
- 컨테이너 이미지 관리, 네트워크 설정 등 수행
- 예 :
containerdCRI-ODocker
고수준 런타임 이용을 목적으로 하며 containerd, CRI-O에 대해서 알아보자.
Containerd
containerd는 Docker에서 분리된 컨테이너 런타임이다. Docker의 핵심 컴포넌트 중 하나로 컨테이너 생애주기와 이미지 관리를 담당한다.
컨테이너 시작과 종료에 필요한 핵심 동작을 담당하며, Docker외 다른 컨테이너 관리 도구 K8S에도 이용할 수 있다.
K8S 이용시 도커 자체를 런타임으로 이용하는 것과 containerd를 이용하는 부분에서 차이가 있다고 한다.
K8S + containerd : containerd가 중지된 상태에서도 명령어를 통해 pods 확인, 생성, 삭제할 수 있다.
→ API 서버가 정상적으로 동작하게된다.
K8S + Docker : Docker를 중지하면 Pods 명령어를 이용하더라도 해당 API 서버가 Command를 받지 해 실행되지 않는다.
CRI-O
Kubernetes 전용 컨테이너 런타임이며, 컨테이너를 실행하고 관리하는 데 필요한 최소한의 기능만을 제공하며, Kubernetes의 CRI와 직접 통신합니다.
- Kubernetes 전용
- Docker와 달리 Kubernetes 환경에서만 최적화되어 사용됩니다.
- Kubernetes의 CRI(Container Runtime Interface) 표준을 따르며, Kubernetes와 직접 상호작용한다.
- 가벼운 런타임
- CRI-O는 불필요한 기능을 제거하고 Kubernetes에 필요한 기능만 제공하여 가볍고 빠른 실행을 목표로 합니다.
- 컨테이너 실행에 필요한 기본적인 기능만 제공
- CRI-O는 컨테이너 실행과 이미지를 다루는 데 필요한 최소한의 기능만 제공하며, Docker와 같은 추가적인 기능은 포함하지 않습니다.
- OCI(Open Container Initiative) 호환
- CRI-O는 OCI 표준을 따르는 런타임으로, 다양한 컨테이너 런타임(
runCgVisor등)과 호환됩니다.
- CRI-O는 OCI 표준을 따르는 런타임으로, 다양한 컨테이너 런타임(
Containerd와 CRI-O 차이
| containerd | CRI-O |
|---|---|
| 범용 컨테이너 런타임 (Kubernetes, Docker 등) | Kubernetes 전용 런타임 |
| 컨테이너 실행을 위한 다양한 기능을 제공 | Kubernetes와 통합을 목적으로 간소화된 기능 제공 |
| 컨테이너 빌드, 이미지 저장소, 네트워크 플러그인 등 추가 기능 제공 | Kubernetes에서 필요한 기본적인 기능만 제공 |
| 여러 기능을 포함한 더 복잡한 구성 요소 (예: 이미지 관리, 네트워크 설정) | Kubernetes CRI에 맞게 구성 |
| Kubernetes 및 다른 시스템(Docker 등)에도 사용 가능 | Kubernetes만 사용 가능 |
| 많은 기능을 제공하지만 상대적으로 더 무겁고 복잡함 | 가벼움, 빠름 |
Containerd와 CRI-O는 위와 같은 차이가 있다. K8S에 컨테이너 런타임이 있으며 처음에는 Docker를 이용해 진행해보려 했다. 하지만,이번에 학습 및 사용해보려는 컨테이너 런타임은 Containerd이다. 그 이유는 아래와 같다.
- K8S 공식 블로그에서 V1.28 이후로 dockershim을 통한 Docker를 지원하지 않는다고 한다. 이유는 dockershim의 추가적인 유지 및 관리를 필요로 하며 오류의 가능성이 높으며, 도커는 CRI를 준수하지 않기 때문이라고 한다.
참고 : https://kubernetes.io/blog/2020/12/02/dont-panic-kubernetes-and-docker/
- CRI-O는 Kubernetes를 위한 컨테이너 런타임으로 가볍고 빠르다는 이점이 있다. 다만, 이전부터 도커를 이용하면서 배운 지식을 이번 기회로 조금 더 심화 학습과정을 거칠 수 있다고 생각하며, containerd에서의 유연한 기능을 이용을 목표로 한다.
KinD(Kubernetes in Docker)란?
Docker 컨테이너 내부에서 Kubernetes 클러스터를 실행할 수 있도록 해주는 경량 Kubernetes 솔루션이며, VM 없이 로컬에서 간편하게 K8S 클러스터를 실행할 수 있는 도구이다.
핵심 개념
- Docker 컨테이너 기반의 Kubernetes 클러스터
- KinD는 Kubernetes 노드를 Docker 컨테이너로 실행하며, 각 노드는 실제 머신이 아니라 하나의 Docker 컨테이너이다.
- 예를 들어, 1개의 Control Plane과 2개의 Worker 노드를 갖춘 클러스터를 만들면 Docker 컨테이너 3개가 생성된다.
- 빠른 테스트 및 개발 환경 구축 가능
- 로컬 환경에서 Kubernetes 클러스터를 실행할 때 Minikube처럼 VM 없이 가볍게 실행 가능
- CI/CD 환경에서도 유용 (GitHub Actions, Jenkins 등에서 Kubernetes 테스트 가능)
- Production 환경에서는 사용하지 않음 (로컬 개발 및 테스트 목적)
- 멀티 노드 클러스터 지원
- 기본적으로 싱글 노드(1개 컨테이너) 클러스터를 실행하지만, 여러 개의 노드를 포함하는 멀티 노드 클러스터도 설정 가능하다.
KinD를 이용해 K8S 클러스터 구축
KinD 설치 (MacOS - Homebrew)
1
2
$ brew update # homebrew 업데이트
$ brew install kind
클러스터 생성
단일 노드 클러스터 생성
1
kind create cluster --name {클러스터 명}

커스텀 클러스터 생성
단일 클러스터 생성시에는 마스터 노드 역할인 control-plane노드만 생성된다. Worker Node 추가는 Yaml을 통해 커스텀으로 가능하다.
1
2
3
4
5
6
7
8
9
10
# kind-cluster.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
networking:
apiServerAddress: "127.0.0.1"
apiServerPort: 6443
1
kind create cluster --name {클러스터 명} --config kind-cluster.yaml
Docker의 MySQL 이용시 네트워크 설정
1
2
$ docker network connect {mysql-network} {control-plane 컨테이너명}
$ docker network connect {mysql-network} {worker 컨테이너명}
Node 확인
1
$ kubectl get nodes

전체 정보 확인
1
$ kubectl get all -A
도커 이미지 로드
로컬에서의 도커 이미지를 이용하기 위해 클러스터에 이미지를 가져온다.
1
$ kind load docker-image {repository-name}/{image-name}:{tag} --name {cluster-name}
설정 및 배포 테스트
ConfigMap을 통해 배포에 필요한 환경 변수 정보를 설정하여 이용할 수 있다.
ConfigMap 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
# tp-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: tp-config
data:
DB_URL: "{mysql-docker-container-name}"
DB_PORT: "{mysql-port}"
DB_NAME: "{mysql-db-name}"
DB_USER: "{mysql-username}"
DB_PWD: "{mysql-password}"
SPRING_PROFILES_ACTIVE: "{project-profiles}"
Deployment 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# travel-planner-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: travel-planner-app
spec:
replicas: 1
selector:
matchLabels:
app: travel-planner
template:
metadata:
labels:
app: travel-planner
spec:
hostPID: true # 호스트의 PID 네임스페이스 사용
containers:
- name: travel-planner-app
image: {docker-repository-name}/{docker-container-name}:${tag}
ports:
- containerPort: 8080 # 컨테이너에서 열리는 포트 (예: 8080)
env:
- name: DB_URL
valueFrom:
configMapKeyRef:
name: tp-config
key: DB_URL
- name: DB_PORT
valueFrom:
configMapKeyRef:
name: tp-config
key: DB_PORT
- name: DB_NAME
valueFrom:
configMapKeyRef:
name: tp-config
key: DB_NAME
- name: DB_USER
valueFrom:
configMapKeyRef:
name: tp-config
key: DB_USER
- name: DB_PWD
valueFrom:
configMapKeyRef:
name: tp-config
key: DB_PWD
- name: SPRING_PROFILES_ACTIVE
valueFrom:
configMapKeyRef:
name: tp-config
key: SPRING_PROFILES_ACTIVE
resources:
requests:
cpu: "2000m" # CPU 2 Core
memory: "1024Mi" # Memory 1GiB
limits:
cpu: "4000m" # CPU 4 Core Limit
memory: "2048Mi" # Memory 2GiB Limit
- hostPID : 각각의 독립적인 PID를 이용하는 Pod가 호스트 노드의 PID 네임스페이스를 공유하여 Pod 내에서 실행되는 프로세스가 호스트 노드의 모든 프로세스를 볼 수 있다.
- 컨테이너에서
ps aux,top,kill명령어 등을 실행하면 호스트의 모든 프로세스를 관리 가능하며시스템 모니터링,컨테이너가 호스트의 특정 프로세스를 제어,네트워크 및 보안 툴사용 가능하다.
- 컨테이너에서
Service 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
# travel-planner-service.yaml
apiVersion: v1
kind: Service
metadata:
name: travel-planner-service
spec:
selector:
app: travel-planner
ports:
- protocol: TCP
port: 8080 # 서비스 내에서 사용할 포트
targetPort: 8080 # 컨테이너에서 사용할 포트
리소스(ConfigMap, Service, Deployment) 생성
1
2
3
$ kubectl apply -f tp-config.yaml
$ kubectl apply -f travel-planner-service.yaml
$ kubectl apply -f travel-planner-deployment.yaml
Pods 세부 정보
1
$ kubectl get pods -o wide
서비스의 엔드포인트 정보
1
$ kubectl get endpoints
- 서비스가 라우팅하는 Pod의 내부 IP 및 포트 확인을 할 수 있다.
서비스 Port Forward
아래 명령어를 이용해 로컬에서 8080 포트로 서비스를 요청할 수 있다.
1
$ kubectl port-forward service/travel-planner-service 8080:8080

NodePort를 통한 서비스 접근
kind-cluster.yaml로 다시 돌아가 로컬 Host OS에서 접속할 worker에 extraPortMappings 설정을 추가해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# kind-cluster.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
extraPortMappings:
- containerPort: 30080 # 클러스터 내 서비스의 노드포트
hostPort: 30080 # 외부에서 요청할 포트
protocol: TCP
networking:
apiServerAddress: "127.0.0.1"
apiServerPort: 6443
cluster 재시작 이후 Docker의 MySQL 이용시 네트워크 설정, 클러스터 도커 로컬이미지 로드 작업을 진행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# travel-planner-service.yaml
apiVersion: v1
kind: Service
metadata:
name: travel-planner-service
spec:
selector:
app: travel-planner
ports:
- protocol: TCP
port: 8080 # 서비스 내에서 사용할 포트
targetPort: 8080 # 컨테이너에서 사용할 포트
nodePort: 30080 # 외부에서 접근할 노드 포트
type: NodePort # NodePort 서비스 타입
- 서비스 구성에서
nodePort와type: NodePort를 설정 후 service를 다시 적용한다.
이후 아래 명령어를 통해 PORT(S)에 8080 내부 포트가 30080 외부포트로 설정된 것을 볼 수 있다.
1
$ kubectl get svc travel-planner-service

Pod의 Node 설정
NodePort를 이용할 경우 Worker 노드가 2개 이상일 때 각 노드에 대해서 외부 포트를 지정해야한다. 이럴 때 각 노드의 외부 포트를 30080, 30081로 설정하면 Pod는 랜덤으로 두 노드 중 하나가 지정될 것이며, 서비스 이용에 포트 또한 바뀌어야한다. 이에 아래와 같이 간단하게 Pod의 Node를 설정해줄 수 있다.
1
2
3
4
5
6
7
8
9
10
# travel-planner-deployment.yaml
apiVersion: apps/v1
...
spec:
hostPID: true
nodeSelector:
kubernetes.io/hostname: {Worker 노드 이름}
containers:
...

롤링 업데이트(Rolling Update)
K8S에서 롤링 업데이트(Rolling Update)는 기존 Pod를 하나씩 새로운 버전으로 교체하는 방식으로 무중단 배포를 지원한다. 즉, 애플리케이션을 배포할 때 전체 서비스를 중단하지 않고 순차적으로 새로운 버전으로 업데이트하는 방식이다.
롤링 업데이트 동작 방식
- 새로운 버전의 애플리케이션을 포함한 새로운 Pod를 생성
- 기존 Pod를 하나씩 제거하면서 새로운 Pod로 교체
- 모든 Pod가 새로운 버전으로 변경될 때까지 위 과정을 반복
롤링 업데이트 설정
Deployment의 spec.strategy에서 RollingUpdate 전략을 사용하면 자동으로 롤링 업데이트가 수행됩니다. Service는 기존 설정에서 변경 사항이 없으며 Deployment에 strategy를 설정해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# travel-planner-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: travel-planner-app
spec:
replicas: 2 # 2개의 Pod 운영
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # 업데이트 중 최대 1개의 Pod만 Down
maxSurge: 1 # 새로운 Pod를 추가하면서 배포 진행
selector:
matchLabels:
app: travel-planner
template:
metadata:
labels:
app: travel-planner
spec:
hostPID: true
nodeSelector:
kubernetes.io/hostname: {Worker 노드 이름} # worker 노드의 이름
terminationGracePeriodSeconds: 20 # 종료시 Gracefull Down 시간 설정
containers:
- name: travel-planner-app
...
readinessProbe: # Pod가 정상적으로 준비될 때까지 트래픽을 받지 않도록 설정
httpGet:
path: /actuator/health/readiness # Healthy Check Path
port: 8080
initialDelaySeconds: 3 # 초기 딜레이 시간
periodSeconds: 5 # 반복 주기
livenessProbe: # 컨테이너가 정상 동작하는지 확인
httpGet:
path: /actuator/health/liveness # Healthy Check Path
port: 8080
initialDelaySeconds: 5 # 초기 딜레이 시간
periodSeconds: 10 # 반복 주기
successThreshold: 3 # 설정된 횟수만큼 실패가 반복되면 Pod가 재시작
failureThreshold: 5 # 설정된 횟수만큼 성공한 후 Pod가 정상으로 간주
Health Check를 위한 Spring Boot Actuator 설정
Spring Boot Actuator 의존성 추가 후 아래 설정 추가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# application.yaml
...
management:
endpoints:
web:
exposure:
include: health, info, metrics
endpoint:
health:
enabled: true
show-components: ALWAYS
show-details: NEVER # 세부 정보가 출력되기에 미사용
metrics:
enabled: true
health:
db:
enabled: true
diskspace:
enabled: true # 디스크 공간 체크 활성화
threshold: 1073741824 # 1GB 이하이면 DOWN 처리
ping:
enabled: true # Ping 체크
http://127.0.0.1:8080/actuator/health로 접속하여 서비스 상태 확인할 수 있다.

show-details: ALWAYS 설정 후 출력 결과
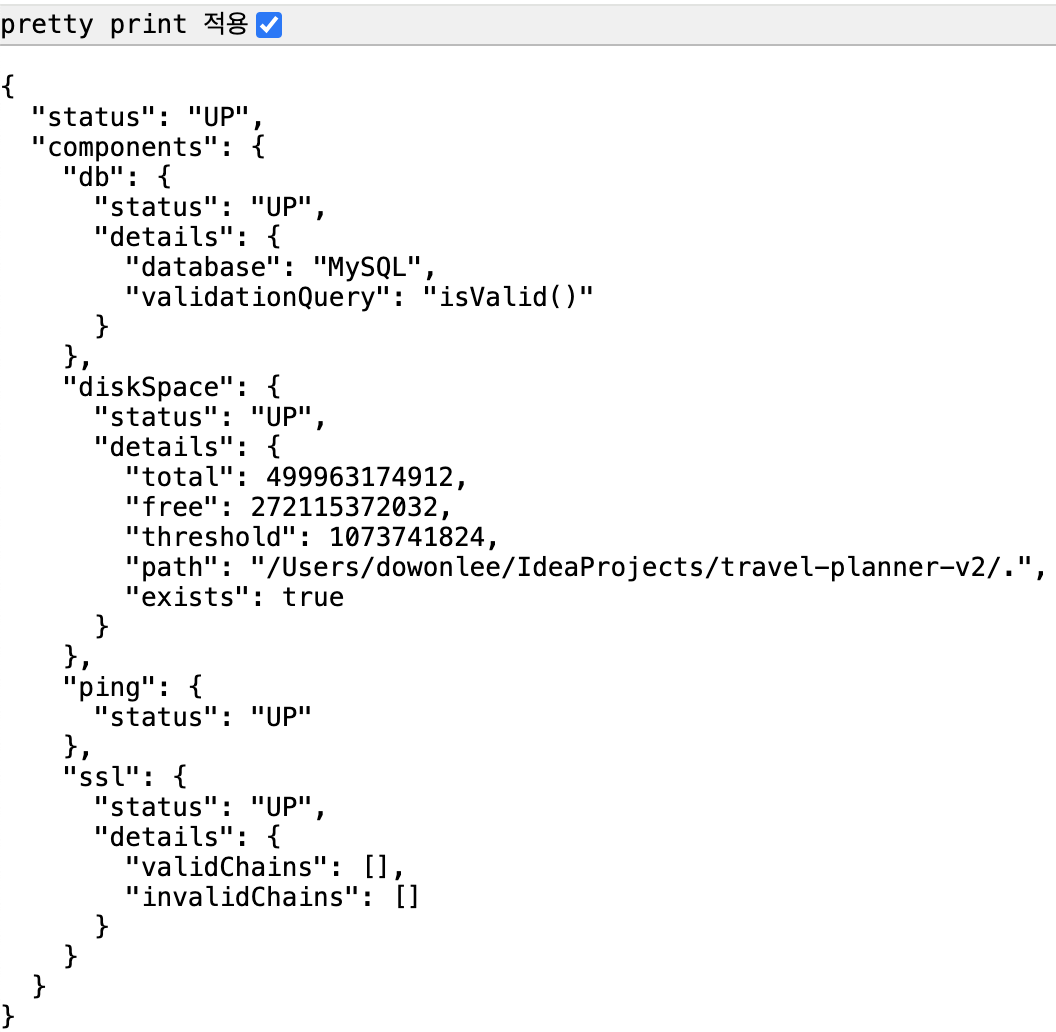
이미지 및 롤링 업데이트
K8S에 이미 실행중인 Deployment의 컨테이너 이미지 업데이트에 사용한다. 이를 통해 애플리케이션의 버전 업그레이드나 수정된 코드 배포를 쉽게 처리할 수 있다. 해당 명령어의 경우 롤링 업데이트가 바로 진행된다.
이미지 업데이트를 통한 재배포
1
$ kubectl set image deployment {deployment-name} {deployment-name}={deployment-name}:{new-tag}
롤링 업데이트 재배포
1
$ kubectl rollout restart deployment {deployment-name}

총 2개의 Pod에서 기존 Replica 1개 Pod가 종료되고 신규로 Pod가 2개 추가되며 신규 Pod들이 정상 상태가 되면 남은 Pod 1개 또한 종료된다.
롤링 업데이트 과정에 대한 의문점
rolling update 설정에서 1개씩 파드를 종료하고 배포하는 방식으로 설정했는데 왜 동시에 2개의 파드가 올라올까?
쿠버네티스가
availableReplicas수를 계산할 때 종료 중인(terminating) 파드는 포함하지 않으며, 이 수는replicas - maxUnavailable와replicas + maxSurge사이에 존재한다. 그 결과, 롤아웃 중에는 파드의 수가 예상보다 많을 수 있으며, 종료 중인 파드의terminationGracePeriodSeconds가 만료될 때까지는 디플로이먼트가 소비하는 총 리소스가replicas + maxSurge이상일 수 있다. 참고 : https://kubernetes.io/ko/docs/concepts/workloads/controllers/deployment
롤백 방법
신규 버전을 배포 후 이슈 발생시 롤백을 해야할 필요가 있다. 이 경우 아래 명령어를 통해 롤백을 할 수 있다.
1
2
# 이전 버전으로 롤백
$ kubectl rollout undo deployment my-app
1
2
3
4
5
# 버전 리비전 확인
$ kubectl rollout history deployment {deployment-name}
# 특정 버전으로 롤백
$ kubectl rollout undo deployment {deployment-name} --to-revision={버전}
K8S 대시보드
K8S 대시보드 설치
1
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
서비스 계정 생성 및 Cluster 바인딩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# k8s-account-binding.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
1
$ kubectl apply -f k8s-account-binding.yaml
Proxy 서버 실행
1
kubectl proxy
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
토큰 생성
1
$ kubectl -n kubernetes-dashboard create token admin-user
대시보드 화면
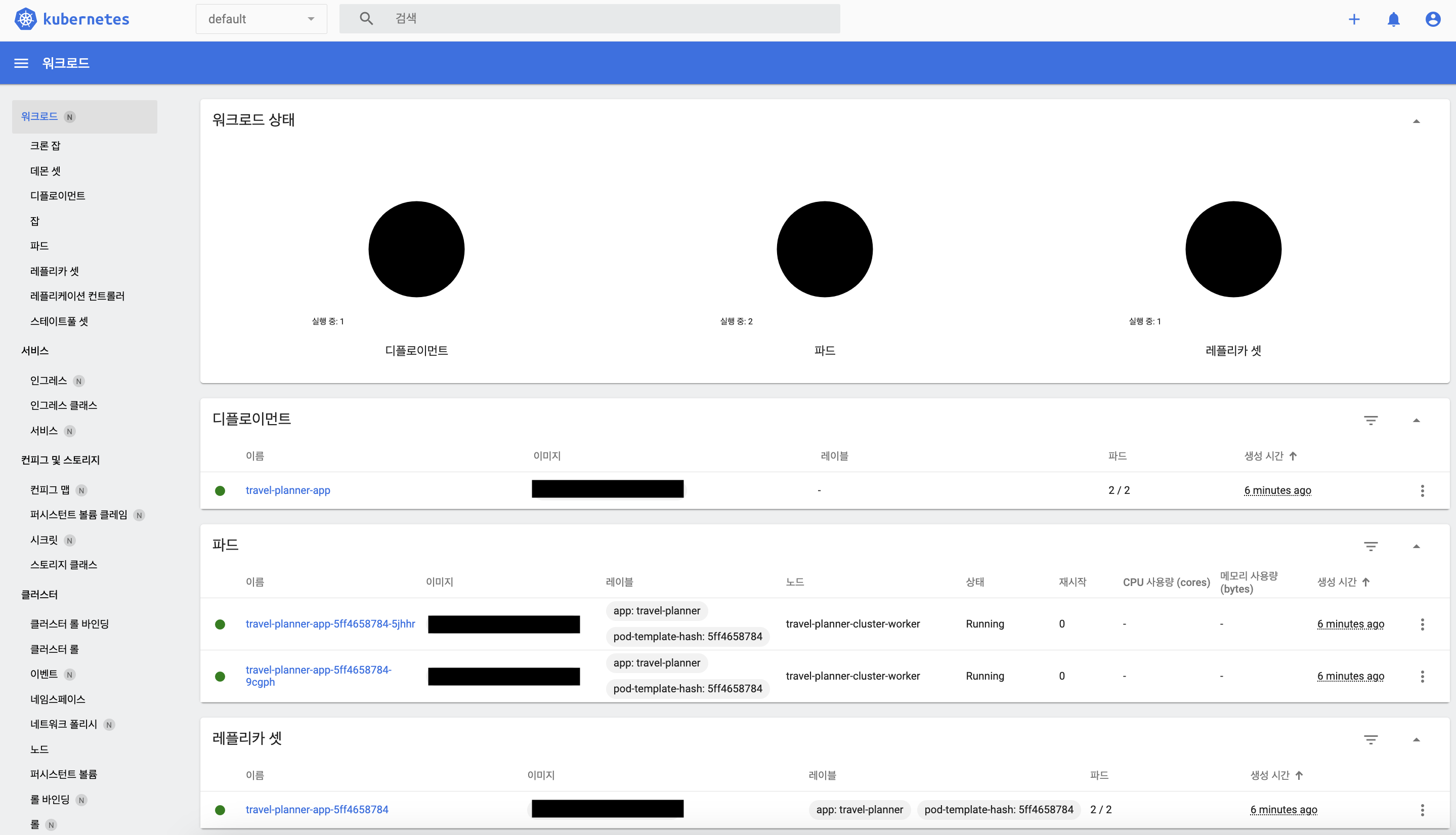
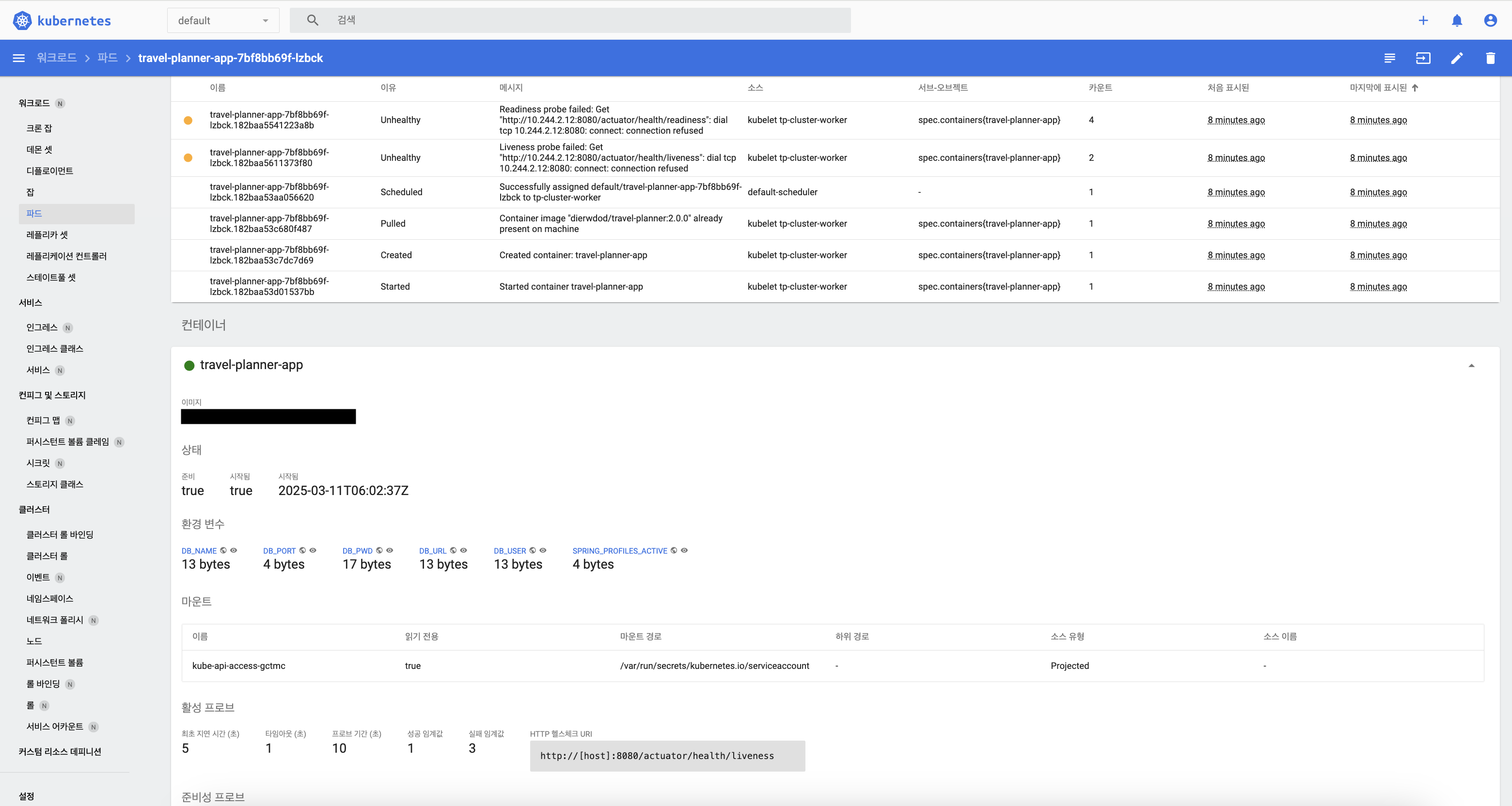
트러블 슈팅
문제 발생
Spring Acturator 설정 이후 아래 Metric 빈 생성이 계속해서 실패하는 원인이 발생
org.springframework.beans.factory.BeanCreationException: Error creating bean with name ‘processorMetrics’ … Caused by: java.lang.NullPointerException: Cannot invoke “jdk.internal.platform.CgroupInfo.getMountPoint()” because “anyController” is null
원인 분석
JDK 17 이슈 : JDK 17에서 Cgroup V2(컨테이너 리소스 제한 관련)의 경우 K8S, Docker와 같은 컨테이너 환경에서 Cgroup 정보를 읽지 못하는 경우가 발생할 수 있으며, 특히 jdk 17 버전에서 자주 발생한다고 한다.
JVM이
/proc/self/mountinfo에서/sys/fs/cgroup혹은 파일이 없거나 권한 문제로 접근이 불가능할 때 발생
실제 Docker 컨테이너 내부에 접속하여 /sys/fs/cgroup 를 확인해보았을 때 내부 관련 파일들은 있었다. 그렇다면, 파일들에 대한 접근 권한의 문제로 이슈가 발생하는 것으로 생각하게 되어 해결방법을 찾아보았다.
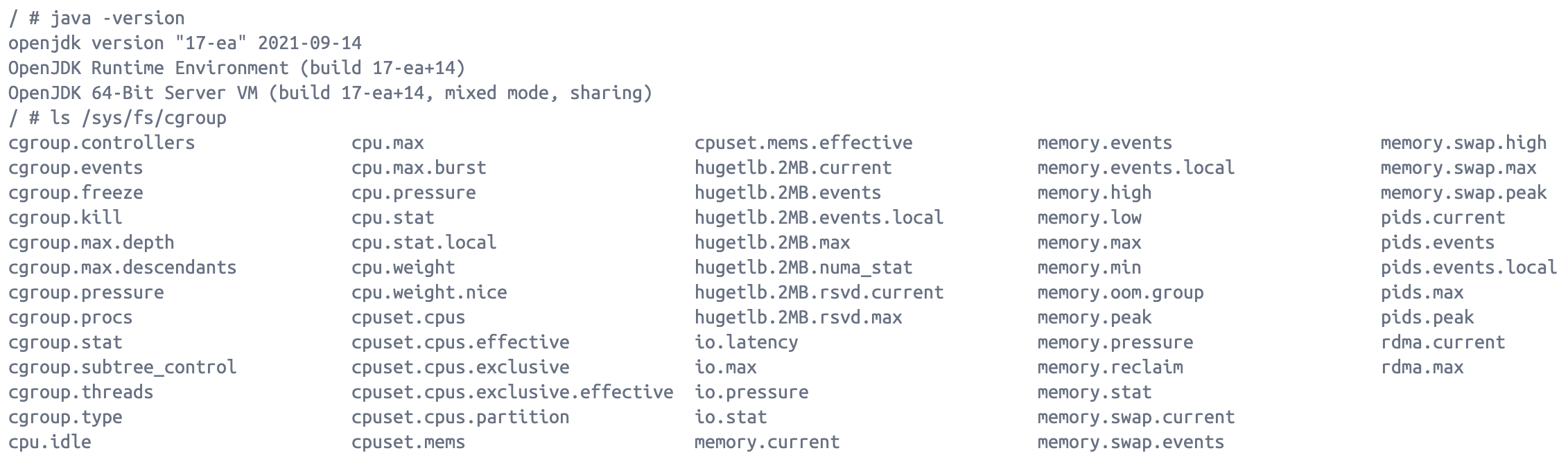
해결방안
- JVM 옵션으로 Cgroup 감지 비활성화 (
JAVA_OPTS : "-XX:-UseContainerSupport”)- 모니터링을 위해 리소스 정보를 확인할 필요가 있어 보이기에 활성화 필요
- JDK 버전을 17.0.9 이상으로 변경 필요
- 현재 JDK : openjdk:17-alpine (JDK 버전 : 17-ea)
- 변경 JDK : bellsoft/liberica-openjdk-alpine:17.0.9 (JDK 버전 : 17.0.9)
결과
JDK 버전 변경 이후 Cgroup 내부 파일을 확인과 K8S에 정상적인 배포가 이루어진 것으로 보아 파일 접근 권한이 원인인 것으로 이슈를 해결할 수 있었다.

K8S 리소스 설정과 HPA(Horizontal Pod Autoscaler)
K8S의 기본적인 설정과 배포를 진행해보았다. K8S에 핵심 기능으로서 컨테이너 오케스트레이션 및 수평적 확장에 대한 설정을 해보고자 한다.
네임스페이스(Namespace)
K8S에서 네임스페이스는 클러스터 내 리소스 그룹 격리 메커니즘을 제공한다. 리소스 이름은 네임스페이스에서 유일해야하며 네임스페이스간에는 유일할 필요는 없다. 네임스페이스 기반 스코핑은 네임스페이스 기반 오브젝트 (예: 디플로이먼트, 서비스 등) 에만 적용 가능하며 클러스터 범위의 오브젝트 (예: 스토리지클래스, 노드, 퍼시스턴트볼륨 등) 에는 적용 불가능하다.
클러스터를 만들게 되면 초기 네임스페이스는 아래와 같이 default, kube-node-lease, kube-public, kube-system 4개가 있다.

- default: 네임스페이스를 생성하지 않고도 default에서 새 클러스터를 사용할 수 있다.
- kube-node-lease: 각 노드와 연관된
리스오브젝트를 갖는다. 노드 리스는 kubelet이하트비트를 보내서 컨트롤 플레인이 노드의 장애를 탐지할 수 있게 한다.- 리스: 분산 시스템에는 종종 공유 리소스를 잠그고 노드 간의 활동을 조정하는 메커니즘을 제공함에 있어 리스가 필요하다.
coordination.k8s.ioAPI 그룹에 있는Lease오브젝트로 표현되며, 노드 하트비트 및 컴포넌트 수준의 리더 선출과 같은 시스템 핵심 기능에서 사용된다. - 하트비트: 클러스터가 개별 노드가 가용한지를 판단할 수 있도록 도움을 주고, 장애가 발견된 경우 조치를 할 수 있게한다.
- 리스: 분산 시스템에는 종종 공유 리소스를 잠그고 노드 간의 활동을 조정하는 메커니즘을 제공함에 있어 리스가 필요하다.
- kube-public: 모든 클라이언트(인증되지 않은 클라이언트 포함)가 읽기 권한으로 접근할 수 있다. 주로 전체 클러스터 중에 공개적으로 드러나서 읽을 수 있는 리소스를 위해 예약되어 있으나, 공개적인 성격은 단지 관례이지 요구 사항은 아니다.
- kube-system: 쿠버네티스 시스템에서 생성한 오브젝트를 위한 네임스페이스이다.
kube-접두사로 시작하는 네임스페이스는 쿠버네티스 시스템용으로 예약되어 있으므로, 사용자는 이러한 네임스페이스를 생성하지 않는다.
Namespace 리소스 생성
1
2
3
4
5
6
7
8
# tp-namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: {네임스페이스명}
labels:
environment: dev
1
$ kubectl apply -f tp-namespace.yaml
현재 네임스페이스 변경
현재 Context를 기본(default) 네임스페이스에서 사용할 네임스페이스로 변경해준다.
1
$ kubectl config set-context --current --namespace={네임스페이스명}
주의 : 네임스페이스를 삭제하면 그 안의 모든 리소스(Pod, Deployment, Service 등)도 함께 삭제된다.
Service, Deployment 리소스 네임스페이스 설정
1
2
3
4
5
6
7
8
# travel-planner-service.yaml
apiVersion: v1
kind: Service
metadata:
name: travel-planner-service
namespace: {네임스페이스명}
...
1
2
3
4
5
6
7
8
# travel-planner-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: travel-planner-app
namespace: {네임스페이스명}
...
네임스페이스 리소스 제한 설정(ResourceQuota / LimitRange)
ResourceQuota와 LimitRange
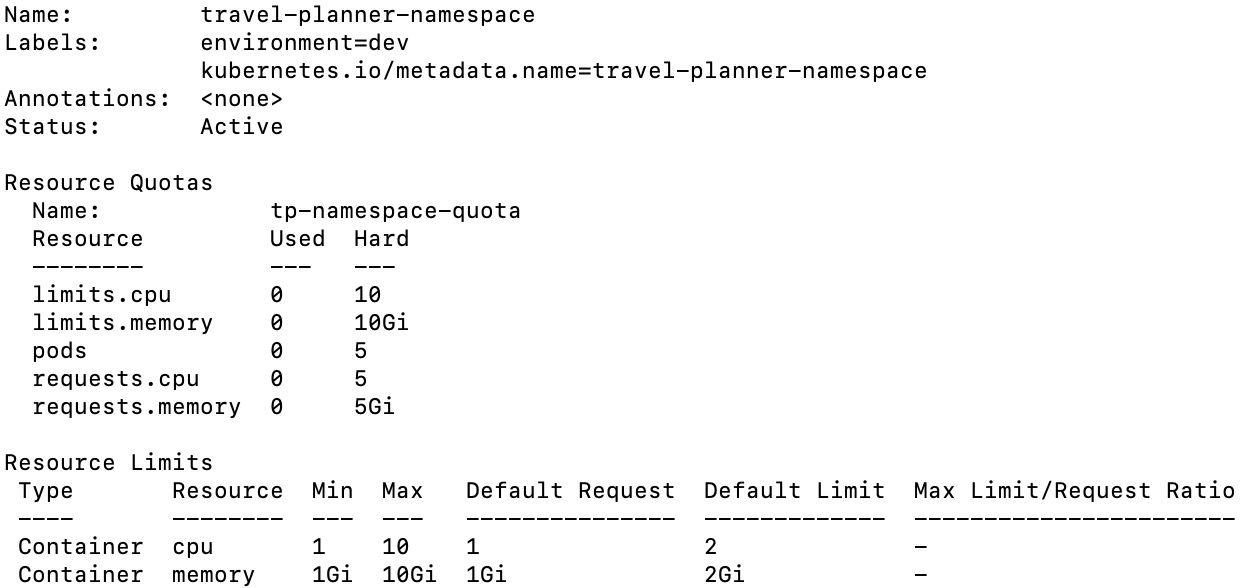
ResourceQuota는 특정 네임스페이스가 사용할 수 있는 전체 리소스의 최대치를 제한한다. 이를 통해 한 네임스페이스가 과도한 리소스를 사용하여 다른 네임스페이스를 방해하는 것을 방지할 수 있다.
LimitRange는 네임스페이스 내에서 각 컨테이너가 요청할 수 있는 리소스의 최소/최대값을 강제한다. 이를 통해 비효율적인 리소스 요청을 하지 못하도록 제한할 수 있습니다.
ResourceQuota 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# tp-resource-quota.yml
apiVersion: v1
kind: ResourceQuota
metadata:
name: tp-resource-quota
namespace: {네임스페이스명}
spec:
hard:
pods: "5" # 네임스페이스 내 최대 Pod 허용
requests.cpu: "5" # 네임스페이스 내 요청 CPU
requests.memory: "5Gi" # 네임스페이스 내 요청 메모리
limits.cpu: "10" # 네임스페이스 내 제한 CPU
limits.memory: "10Gi" # 네임스페이스 내 제한 메모리
이 네임스페이스는 최대 5개 Pod가 허용 CPU는 5 ~ 10개까지 이용 가능 메모리는 5 ~ 10Gib까지 허용한다.
LimitRange 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# tp-limit-range.yml
apiVersion: v1
kind: LimitRange
metadata:
name: tp-limit-range
namespace: {네임스페이스명}
spec:
limits:
- type: Container
max: # 컨테이너당 최대 CPU/Memory
cpu: "10"
memory: "10Gi"
min: # 컨테이너당 최소 CPU/Memory
cpu: "1"
memory: "1Gi"
default: # 명시적으로 요청하지 않은 경우 기본 요청 값
cpu: "2"
memory: "2Gi"
defaultRequest: # 컨테이너가 요청하는 기본 CPU/Memory
cpu: "1"
memory: "1Gi"
- default: 컨테이너가 리소스 요청을 하지 않았을 경우 자동으로 할당되는 최대 리소스이다.
- defaultRequest: 컨테이너가 리소스를 요청하지 않았을 경우 자동으로 예약되는 최소 리소스이다.
리소스 확인
1
$ kubectl describe namespace {네임스페이스명}
Deployment 리소스 변경사항
위 LimitRange를 설정하게되면 기존의 Deployment에 resources.requests resources.limits설정에 대해서 아래 내용에 따라서 달라지게 된다.
Deployment에 resources (requests, limits)미설정
- requests는 LimitRange에 설정한 defaultRequest 값이 적용됨
- limits는 LimitRange에 설정한 default 값이 적용됨
리소스 제한을 초과하게 되면 Pod 스케줄링이 되지 않음
HPA(Horizontal Pod Autoscaler)
HPA는 워크로드에 따라 Pod의 수평 확장/축소를 담당한다. 주로 CPU, 메모리 사용량, 또는 사용자 정의 메트릭을 기반으로 스케일링을 하며 기능을 정의하면 아래와 같다.
- 자동 스케일링: 클러스터의 리소스를 효율적으로 사용하기 위해, Pod 수를 자동으로 늘리거나 줄입니다.
- 부하에 따라 조정: HPA는 애플리케이션의 부하를 감지하고, 부하가 증가하면 더 많은 Pod을 생성하고, 부하가 감소하면 Pod 수를 줄여 리소스를 최적화합니다.
- CPU, 메모리 또는 메트릭 기반 스케일링: 기본적으로 CPU 사용량, 메모리 사용량을 기준으로 스케일링을 진행하며, 사용자 정의 메트릭으로도 스케일링할 수 있습니다.
HPA 리소스 설정 (수평적 확장)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# tp-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: tp-hpa
namespace: {네임스페이스명}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {deployment의 metadata.name}
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu # 확장 기준 리소스
target:
type: Utilization
averageUtilization: 60 # Pod 확장 기준 사용률
Deployment 변경
- HPA에 의한 수평적 Pod AutoScaling을 위한 replicas 삭제
- LimitRange에서 리소스 관리를 위해 resources 삭제
Metrics Server 구성
HPA 모니터링을 위해 Metric Server 리소스를 적용해준다.
1
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.5.0/components.yaml
1
$ kubectl get pods -n kube-system | grep metrics-server
1
$ kubectl logs <metrics-server-pod-name> -n kube-system
Metrics Server Kubectl 인증서 오류
처음 Metrics Server 설정 후 아래와 같은 오류가 발생할 수 있다.
“Get "https://172.28.0.2:10250/stats/summary?only_cpu_and_memory=true": x509: cannot validate certificate for 172.28.0.2 because it doesn’t contain any IP SANs” node=”travel-planner-cluster-control-plane”
원인은 Kubelet API 서버의 인증서에 IP SAN (Subject Alternative Name) 항목이 없기 때문에 발생한다.
Kubelet 인증서를 사용하고 있지 않다면 아래와 같이 설정 후 리소스를 변경해준다.
1
2
3
# Metrics Server Deployment 수정
$ kubectl edit deployment metrics-server -n kube-system
1
2
3
4
5
6
7
...
spec:
containers:
- name: metrics-server
args:
- --kubelet-insecure-tls # 추가
- ...
1
$ kubectl rollout restart deployment metrics-server -n kube-system
HPA 테스트
특정 API를 10000번 호출하는 방식으로 진행하여 테스트해보았다.
1
$ kubectl get hpa -n {네임스페이스명}
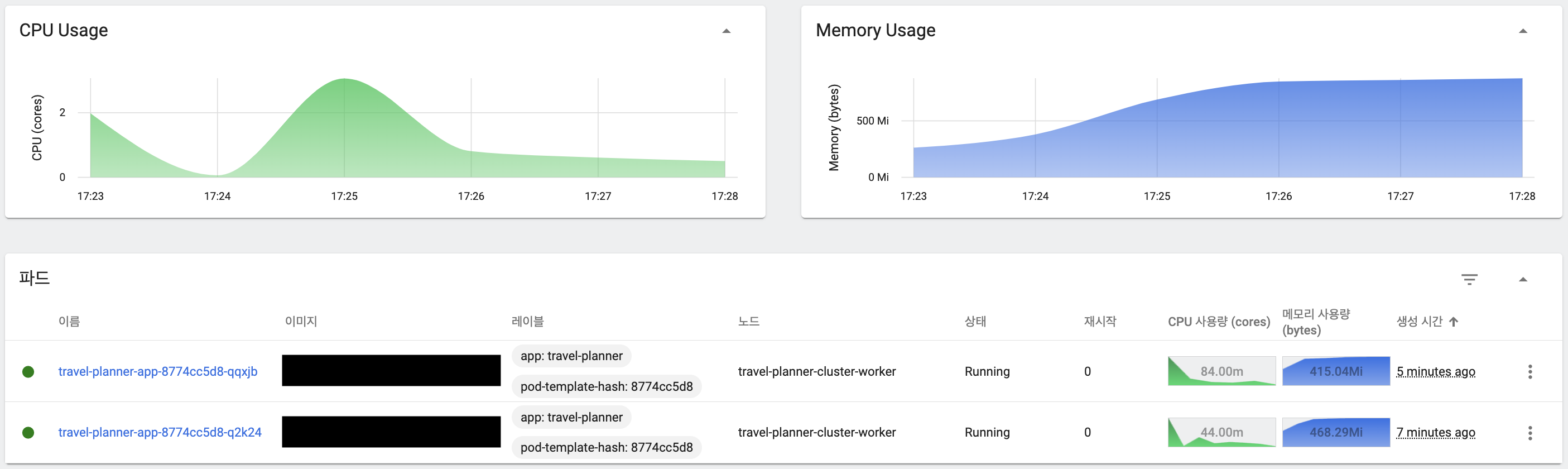
CPU 제한 사용률 초과로 인한 Scale Out
CPU 사용률이 60%가 넘어가면서 신규 Pod 생성으로 Scale Out 발생

Pod 확장 후 리소스 안정화 결과
신규 Pod가 Healthy 상태가 되면서 CPU 사용률 안정화

테스트 종료 이후 신규 Pod 중단
API 호출이 모두 완료된 후 CPU 사용률이 안정화되면서 Replica Pod가 중단되었으며, 이벤트에서 Pod 생성부터 중단까지 세부적인 과정 확인
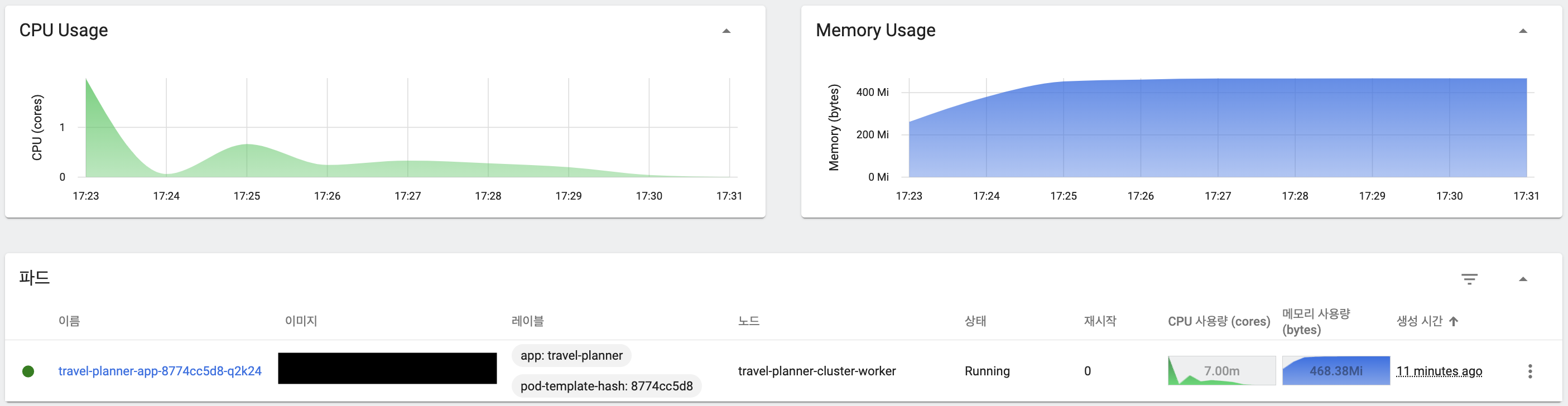
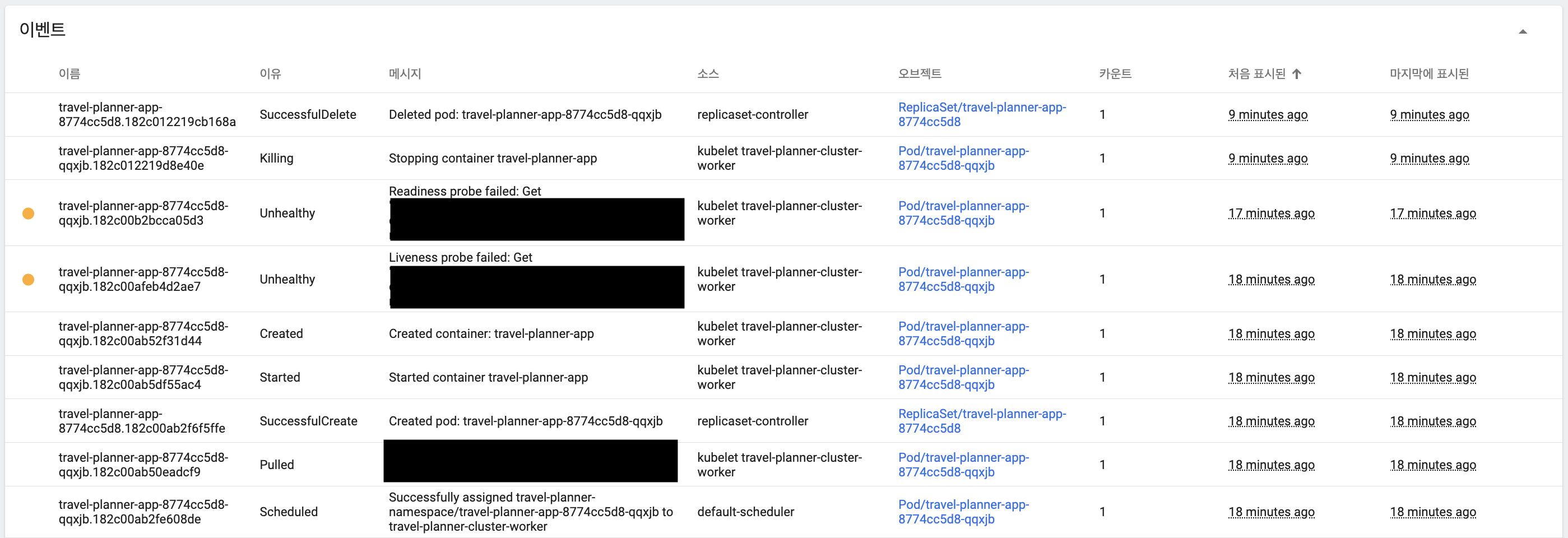
HPA 안정화를 위한 확장/축소 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# tp-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: tp-hpa
namespace: {네임스페이스명}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {deployment의 metadata.name}
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu # 확장 기준 리소스
target:
type: Utilization
averageUtilization: 60 # Pod 확장 기준 사용률
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 1
periodSeconds: 15
selectPolicy: Max
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp(확장 설정)- stabilizationWindowSeconds: 0: 확장 적용 시간을 설정하며
0으로 설정하면 지연 없이 확장을 즉시 적용한다. - policies
- 첫 번째 정책: type: Percent
- value: 현재 Pod 개수 기준으로 확장할 파드 수의 비율을 설정한다.
- 현재 10개 실행 중 → 10개(100%) 추가 가능 (10 → 20)
- periodSeconds: 설정한 시간마다 평가한다.
- value: 현재 Pod 개수 기준으로 확장할 파드 수의 비율을 설정한다.
- 두 번째 정책: type: Pods
- value: 한 번에 확장할 파드의 수를 설정한다.
- periodSeconds: 설정한 시간마다 평가한다.
- 첫 번째 정책: type: Percent
- selectPolicy: Max: Percent와 Pods 정책이 동시에 적용될 경우, 더 큰 값을 적용한다.
- 예) Percent(100%) vs Pods(4개) 중 더 많은 Pod을 추가하는 정책을 선택
- stabilizationWindowSeconds: 0: 확장 적용 시간을 설정하며
scaleDown(축소 설정)- stabilizationWindowSeconds
- Pod을 줄이기 전에 설정한 시간만큼 대기한 후 축소 여부를 결정하여 불필요한 축소를 방지한다.
- policies
- type: Percent: 백분율(%) 기준으로 축소할 때 적용한다.
- value: 한 번의 조정에서 현재 Pod의 100%까지 축소 가능하다.
- 100% 설정 시 기존 Pod의 절반까지 줄일 수 있다.
- periodSeconds: 설정한 시간마다 평가한다.
- stabilizationWindowSeconds
이 behavor 설정을 통해 HPA의 스케줄링을 더 안정적으로 관리하고, 과도한 스케일링으로 인한 자원 낭비를 방지할 수 있다.