JPA + Spring Data JPA + Querydsl 사용해보기(2)

이전 게시물에서 Querydsl이 무엇이고 사용방법에 대해 내용을 정리해보았습니다.
이번에는 Querydsl에서 Paging, Dynamic Query, MySQLDialect를 통한 Full-text Index를 이용한 검색에 대해 정리해보고자 합니다.
프로젝트는 Spring Data JPA + Querydsl 사용해보기(1)와 동일한 환경으로 진행하겠습니다.
Paging
Querydsl Paging 코드 추가
BoardRepositoryCustom.java 페이징 코드 추가
1
2
3
4
5
6
7
public interface BoardRepositoryCustom {
...
Page<BoardResponseDto> getSearchBoards(final String keyword, final Pageable pageable);
}
BoardRepositoryImpl.java 페이징 구현 코드 추가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
@RequiredArgsConstructor
public class BoardRepositoryImpl implements BoardRepositoryCustom {
private final JPAQueryFactory queryFactory;
...
@Override
public Page<BoardResponseDto> getSearchBoards(final String keyword, final Pageable pageable) {
List<BoardResponseDto> content = getPagingBoards(keyword, pageable);
JPAQuery<Long> countQuery = getBoardCount(keyword);
//return PageableExecutionUtils.getPage(content, pageable, countQuery::fetchOne);
return new PageImpl<>(content, pageable, countQuery.fetchOne());
}
private List<BoardResponseDto> getPagingBoards(String keyword, Pageable pageable){
QBoard board = new QBoard("board");
return queryFactory
.select(
new QBoardResponseDto(
board.id, board.title, board.contents,
board.writeDate, board.modifyDate
)
)
.from(board)
.orderBy(board.id.asc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}
private JPAQuery<Long> getBoardCount(String keyword){
QBoard board = new QBoard("board");
return queryFactory
.select(board.id.count())
.from(board);
}
}
Paging 테스트
테스트 코드
1
2
3
4
5
6
7
8
9
10
11
12
@Test
@DisplayName("Querydsl 검색 및 페이징 테스트")
public void testToQuerydslSearchBoards(){
Pageable pageable = PageRequest.of(0, 5);
Page<BoardResponseDto> boards = boardRepository.getSearchBoards(null, pageable);
System.out.println("전체 데이터 개수(getTotalElements): " + boards.getTotalElements());
System.out.println("전체 페이지(getTotalPages): " + boards.getTotalPages());
System.out.println("현재 페이지(getNumber): " + boards.getNumber());
System.out.println("페이지 레코드 개수(getSize): " + boards.getSize());
System.out.println("이전 페이지 여부(hasPrevious): " + boards.hasPrevious());
System.out.println("다음 페이지 여부(hasNext): " + boards.hasNext());
}
테스트 결과 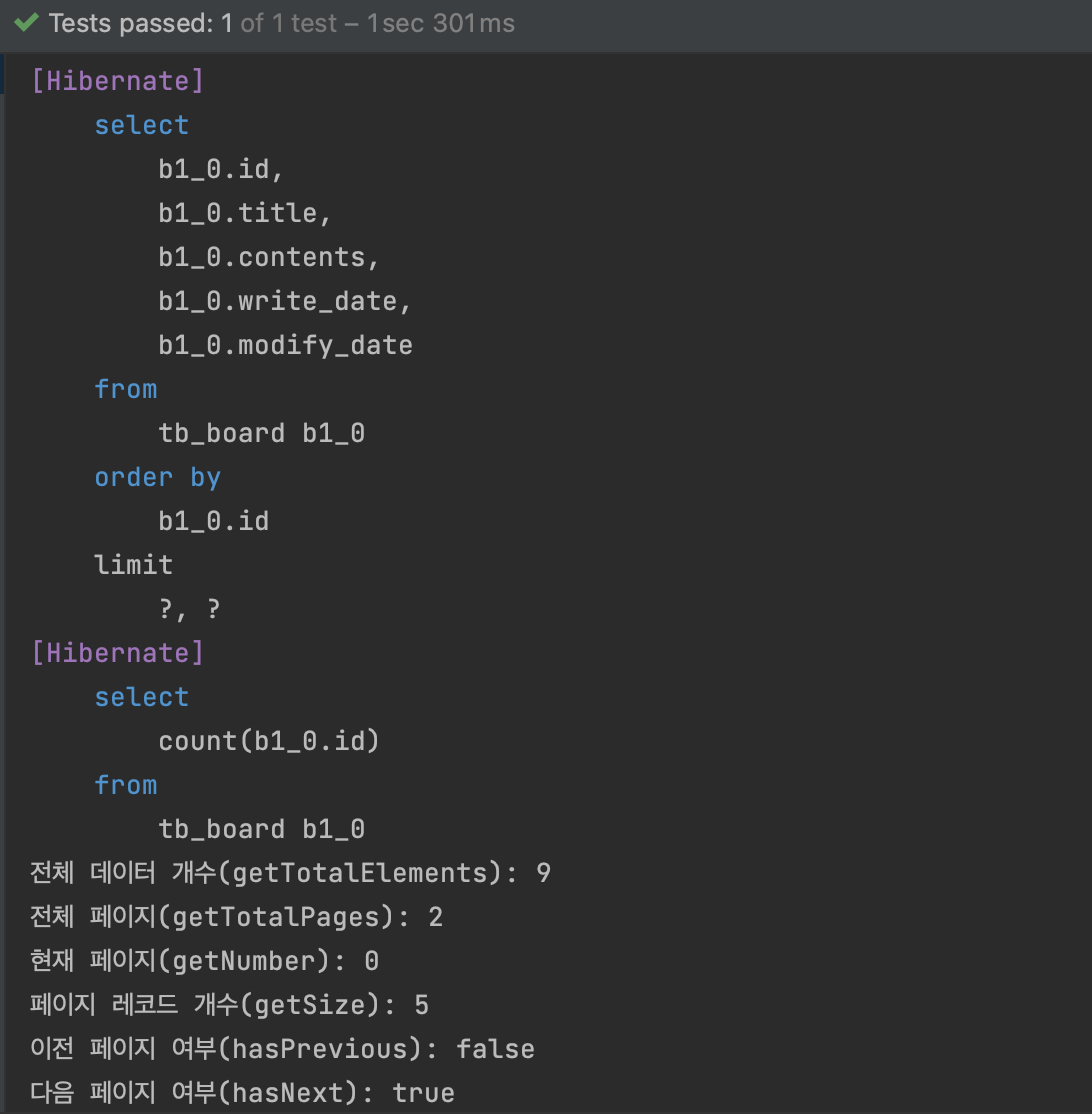 Page 인터페이스로 반환 할 경우 페이징에 필요한 값들을 가져올 수 있다.
Page 인터페이스로 반환 할 경우 페이징에 필요한 값들을 가져올 수 있다.
- getTotalElements : 페이징과 관계없이 모든 데이터 개수를 가져온다.
- getTotalPages : 페이징 레코드 사이즈 기준 전체 페이지 개수
- getNumber : 현재 페이지 번호
- getSize : 페이지 레코드 개수
- hasPrevious : 이전 페이지 여부
- hasNext : 다음 페이지 여부
PageImpl vs PageableExecutionUtils
BoardRepositoryImpl.java 의 페이징 구현부에 Page 인터페이스 구현체인 PageImpl, 페이징 유틸의 역할을 하는 PageableExecutionUtils를 이용해 반환하는 코드가 있다. 두 방법의 차이는 아래와 같다.
- PageImpl 반환 : 전체 개수를 구하는 쿼리를 무조건 실행한다.
- PageableExecutionUtils.getPage 반환 : 전체 개수를 구하는 쿼리를 필요에 따라 실행한다.
테스트 코드에서는 PageImpl 객체를 반환함으로써 전체 개수를 가져오는 쿼리가 실행되는 것을 볼 수 있다.
PageableExecutionUtils 주석을 풀고 PageImpl을 주석한 후에 페이지 사이즈를 20으로 늘려보자 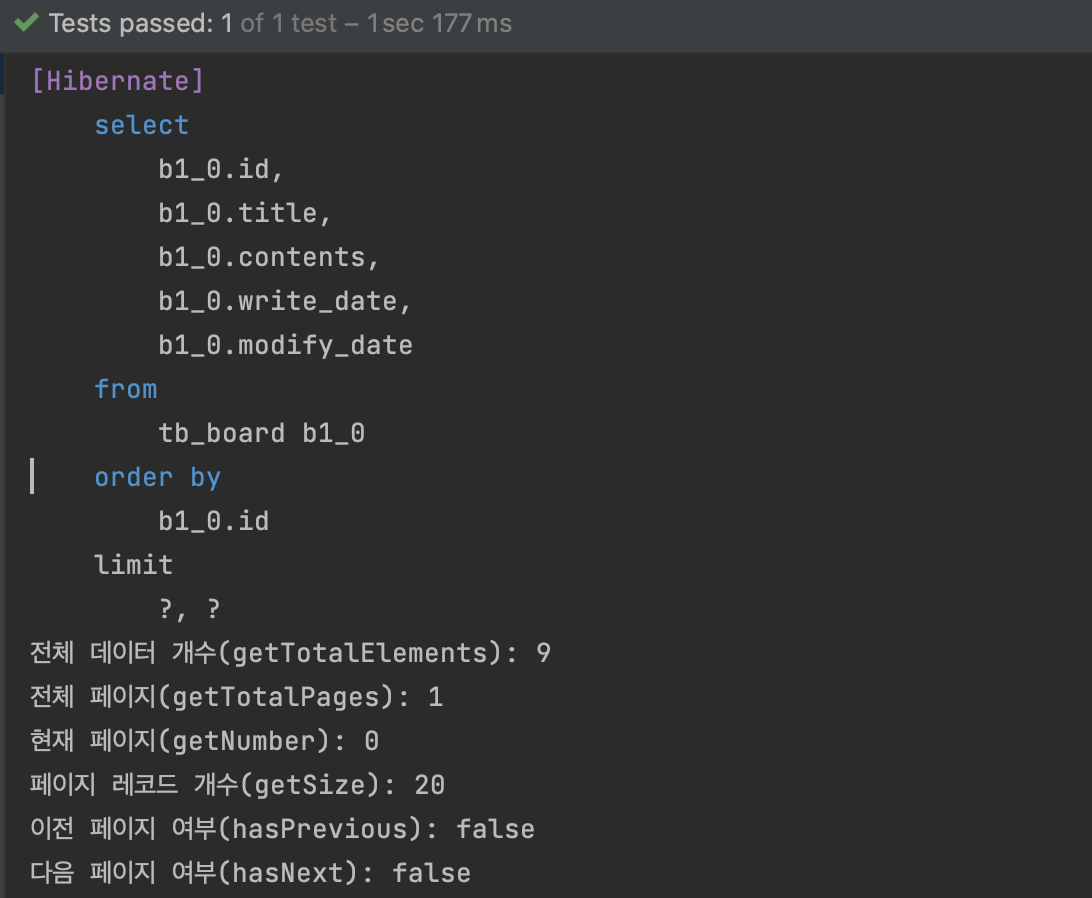 Page 구현체와 다르게 카운트 쿼리가 실행되지 않았다. 아래 PageableExecutionUtils.getPage 메서드 내용을 보면 PageImpl 객체를 생성하여 반환한다.
Page 구현체와 다르게 카운트 쿼리가 실행되지 않았다. 아래 PageableExecutionUtils.getPage 메서드 내용을 보면 PageImpl 객체를 생성하여 반환한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public static <T> Page<T> getPage(List<T> content, Pageable pageable, LongSupplier totalSupplier) {
Assert.notNull(content, "Content must not be null");
Assert.notNull(pageable, "Pageable must not be null");
Assert.notNull(totalSupplier, "TotalSupplier must not be null");
if (pageable.isUnpaged() || pageable.getOffset() == 0) {
if (pageable.isUnpaged() || pageable.getPageSize() > content.size()) {
return new PageImpl<>(content, pageable, content.size());
}
return new PageImpl<>(content, pageable, totalSupplier.getAsLong());
}
if (content.size() != 0 && pageable.getPageSize() > content.size()) {
return new PageImpl<>(content, pageable, pageable.getOffset() + content.size());
}
return new PageImpl<>(content, pageable, totalSupplier.getAsLong());
}
pageable.getOffset() == 0&&pageable.getPageSize() > content.size()시작페이지이고 페이지 사이즈가 content 사이즈보다 클 때content.size() != 0 && pageable.getPageSize() > content.size()마지막페이지일 때
호출 시점을 지연시켜 불필요한 count 쿼리 실행 없이 성능 최적화하고 있다.
Dynamic Query
검색 조건으로 Querydsl에서 동적 쿼리를 어떻게 처리하는지 알아보겠습니다. Paging Querydsl 코드에 제목, 내용을 구분하여 검색할 수 있는 기능을 추가하겠습니다.
BoardRepositoryImpl.java 코드 추가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
private List<BoardResponseDto> getPagingBoards(String keyword, Pageable pageable){
QBoard board = new QBoard("board");
return queryFactory
.select(
new QBoardResponseDto(
board.id, board.title, board.contents,
board.writeDate, board.modifyDate
)
)
.from(board)
.where(
expressionTrue()
.or(titleLike(board, keyword))
.or(contentsLike(board, keyword))
) // => 추가
.orderBy(board.id.asc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}
private JPAQuery<Long> getBoardCount(String keyword){
QBoard board = new QBoard("board");
return queryFactory
.select(board.id.count())
.from(board)
.where(
expressionTrue()
.or(titleLike(board, keyword))
.or(contentsLike(board, keyword))
); // => 추가
}
private BooleanExpression expressionTrue(){
return Expressions.asNumber(1).eq(1);
}
private BooleanExpression titleLike(QBoard board, String keyword){
return keyword != null ? board.title.like("%"+keyword+"%") : null;
}
private BooleanExpression contentsLike(QBoard board, String keyword){
return keyword != null ? board.contents.like("%"+keyword+"%") : null;
}
조건문 쿼리를 반환하는 메소드를 볼 수 있다. BooleanExpression은 Java의 Boolean 타입을 Querydsl만의 타입으로 표현한 클래스이다.
- expressionTrue() : 항상 true를 반환한다는 용도 (WHERE 1 = 1), Fluent API에서의 NullPointerException 발생을 막기위해 추가할 필요가 있다.
키워드 검색에서 검색 유형을 선택하는 기능이 있다면 유형 검색 파라미터 추가 후 아래와 같은 방식으로 조건에 맞는 유형의 메서드를 호출해 사용할 수 있다.
Fluent API
메소드 체이닝에 기반한 객체지향 API 설계 메소드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private BooleanExpression titleContentsTypeLike(QBoard board, String keywordKind, String keyword){
BooleanExpression expression = expressionTrue();
if(ObjectUtils.isEmpty(keywordKind)){
expression
.or(titleLike(board, keyword))
.or(contentsLike(board, keyword));
}
else if(keywordKind.equals("title")){
expression = titleLike(board, keyword);
}
else if(keywordKind.equals("contents")){
expression = contentsLike(board, keyword);
}
return expression;
}
테스트 코드
1
2
3
4
5
6
7
8
9
10
11
12
@Test
@DisplayName("Querydsl 검색 및 페이징 테스트")
public void testToQuerydslSearchBoards(){
Pageable pageable = PageRequest.of(0, 5);
Page<BoardResponseDto> boards = boardRepository.getSearchBoards("제목", pageable); // => '제목'을 검색
System.out.println("전체 데이터 개수(getTotalElements): " + boards.getTotalElements());
System.out.println("전체 페이지(getTotalPages): " + boards.getTotalPages());
System.out.println("현재 페이지(getNumber): " + boards.getNumber());
System.out.println("페이지 레코드 개수(getSize): " + boards.getSize());
System.out.println("이전 페이지 여부(hasPrevious): " + boards.hasPrevious());
System.out.println("다음 페이지 여부(hasNext): " + boards.hasNext());
}
테스트 결과 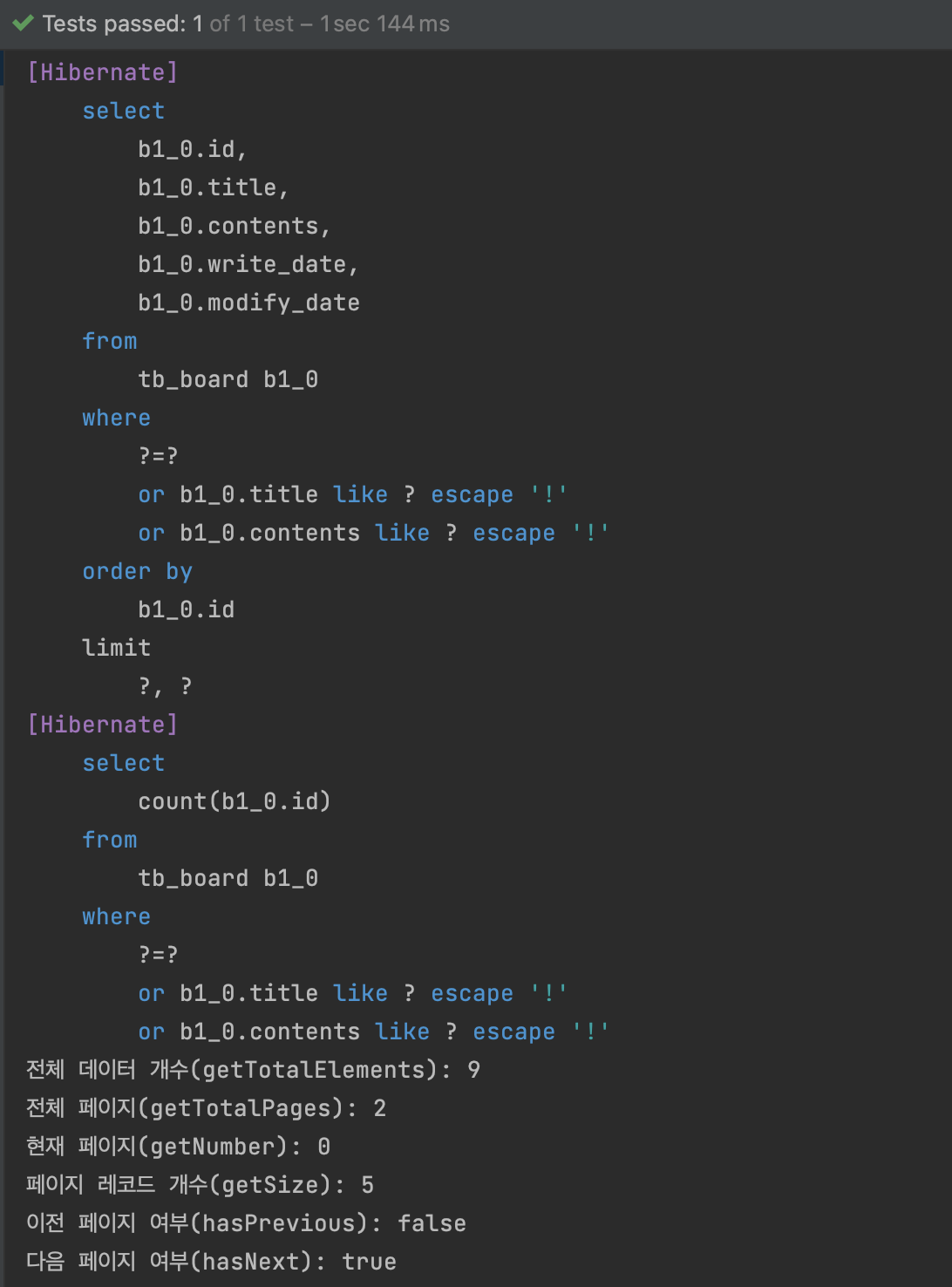
MySQL Full Text Search (Ngram, Boolean Search)
Ngram
Ngram은 토큰의 크기에 따라 검색 결과가 달라진다. 토큰의 크기가 2인 경우 “전자제품 게시판 제목” 문자열의 검색 다생 텍스트는 아래와 같다. (공백은 무시한 상태로 나누어짐)
1
2
set global innodb_ft_aux_table = 'DB명/테이블명';
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;
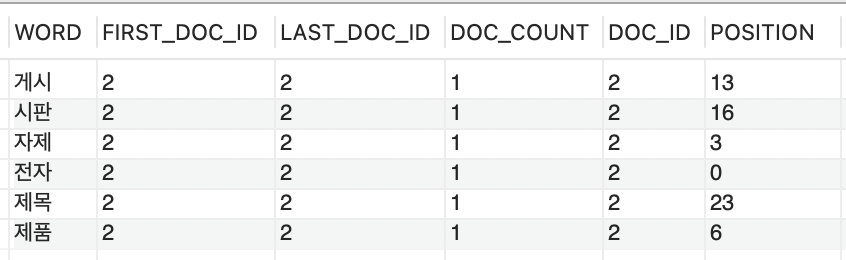
만약, 토큰의 크기가 4이면 ‘전자제품’ 1개 만 검색단어로 지정된다.
불린 모드 검색(Boolean Search)
불린 모드는 검색하고자 하는 키워드가 존재하는지에 대한 여부(true/false)를 수행해 최종 일치 여부를 반환하는 방식이다. 1개의 단어만으로도 가능하지만 키워드에 여러 단어가 주어진 경우 연산자를 통해서 검색을 할 수 있다.
- + 연산자 : 키워드 앞에 + 연산자는 AND을 의미한다.
- - 연산자 : 키워드 앞에 - 연산자는 NOT을 의미한다.
- 연산자 없음 : 키워드 앞에 연산자가 없다면 OR을 의미한다.
Ngram Full Text Index 추가
1
CREATE FULLTEXT INDEX tb_board ON board_ft_idx (title, contents) WITH PARSER ngram;
MySQL에서 Full-text Index는 InnoDB, MyISAM 엔진에만 가능하며 설정전에 확인이 필요합니다.
MySQL Ngram 토큰 사이즈 조회
1
SHOW GLOBAL VARIABLES LIKE "ngram_token_size";
- MySQL의 ngram_token_size 기본 크기는 ‘2’입니다.
FunctionContributor 설정
제가 공부했던 버전에서는 Dialect를 통해 Full Text Search Function을 설정할 수 있었으나, Hibernate 6.4를 사용하면서 Dialect의 registerFunction 메서드가 없어졌다. Hibernate 6 버전 내용을 찾다보니 6.3버전에 FunctionContributor를 통해 사용할 수 있다고 해서 FunctionContributor를 이용해 설정하겠습니다.
CustomFunctionContributor.java 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
public class CustomFunctionContributor implements FunctionContributor {
@Override
public void contributeFunctions(final FunctionContributions functionContributions) {
functionContributions
.getFunctionRegistry()
.registerPattern(
"match_against",
"match (?1, ?2) against (?3 in boolean mode)",
functionContributions.getTypeConfiguration().getBasicTypeRegistry().resolve(StandardBasicTypes.DOUBLE)
);
}
}
- 실제 동작하는 쿼리는
match (?1, ?2) against (?3 in boolean mode)이며 명칭은 match_against이다.
org.hibernate.boot.model.FunctionContributor 파일 생성
- src > main > resources > META-INF > services 경로에 org.hibernate.boot.model.FunctionContributor 파일을 생성해줍니다.
- org.hibernate.boot.model.FunctionContributor 파일 내용에 CustomFunctionController의 패키지명과 클래스명 모두 포함해서 작성한다.
BoardRepositoryImpl.java Full Text Search 쿼리 추가
1
2
3
4
5
6
7
8
private BooleanExpression titleContentsFullText(QBoard board, final String keyword) {
return ObjectUtils.isEmpty(keyword) ? null :
Expressions.numberTemplate(
Double.class,
"function('match_against',{0},{1},{2})",
board.title, board.contents, keyword
).gt(0);
}
{0}, {1}, {2}는 각각 board.title, board.contents, keyword를 의미하며 이 파라미터가 match (?1, ?2) against (?3 in boolean mode) 의 ?1, ?2, ?3에 매핑된다.
테스트전 MySQL Profiling 설정
1
2
SELECT @@profiling;
SET profiling=1;
- SELECT @@profiling : 실행하면 0(디폴트)로 출력되어있는데 off 상태이다.
- SET profiling=1 : on 상태로 변경한다.
테스트
1
SHOW profiles;
- 테스트하고자 하는 쿼리를 먼저 실행한 후 위 SQL을 실행하면 실행속도 및 쿼리를 확인할 수 있다.
테스트 결과 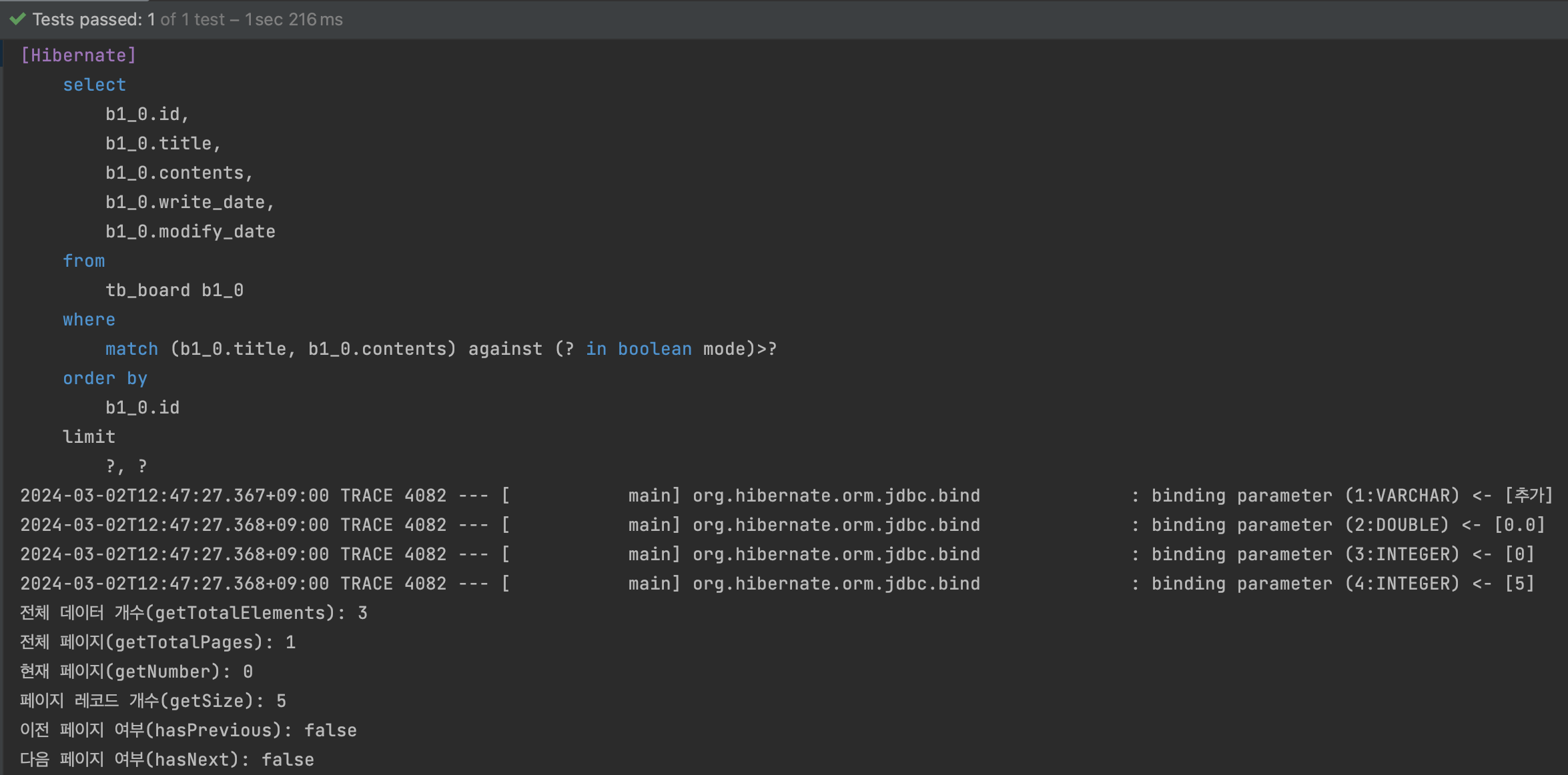
- 조건절에 FunctionContributor에 설정한 match … against 쿼리가 포함되어 실행된다.
Like Search, Full Text Search 비교
테스트 데이터는 약 70만개로 제목 및 내용 검색을 비교했습니다.
Like Search
1
2
3
4
5
6
7
8
9
select
b1_0.id, b1_0.title, b1_0.contents,
b1_0.write_date, b1_0.modify_date
from
tb_board b1_0
where (
b1_0.title like '%영화%'
or b1_0.contents like '%영화%'
);
Full Text Search
1
2
3
4
5
6
7
8
select
b1_0.id, b1_0.title, b1_0.contents,
b1_0.write_date, b1_0.modify_date
from
tb_board b1_0
where
match (b1_0.title, b1_0.contents)
against ('영화' in boolean mode) > 0;
테스트 결과 
- 첫 행의 결과가 Like Search, 두번째 행은 Full Text Search 결과이다.
DB의 스팩마다 결과 수치는 다르겠지만, 결과적으로는 Full Text Search가 약 10배 이상 빠르게 나왔다. 이것만 보면 “미리 인덱스를 지정하고 모든 기능의 검색을 Full Text Search를 사용하는게 좋지 않을까?” 라고 생각할 수 있지만 그렇지만은 않다. 1만 건만 테스트 했을 때 오히려 Like를 이용한 검색이 더 빠른 것을 볼 수 있었고 1000건 단위로 페이징만 추가했을 때도 Like 검색이 더 빠른 것을 확인했다.
Full Text Search는 데이터양 그리고 검색 조건 등 상황에 따라 적용해야할지 말지를 결정해야할 것으로 보인다. 전 회사에서는 Oracle을 사용하면서 문자열 검색으로 인한 별도 설정을 할 필요가 없었다. MySQL 사용 경험은 있지만, 기본적인 내용만 알고 있었다. 이번 기회에 실무에 필요한 내용을 공부하면서 Full Text Search에 대해 정리해보았습니다.