대용량 트래픽 정리 - 코드 개선 및 성능 향상 정리
대용량 트래픽 개인 프로젝트를 진행하면서 부하 테스트 과정에서 성능 향상을 위한 코드 개선과 부가적으로 테스트했던 내용을 정리해보았다.
코드 및 성능 개선
- Mapping
- Sort
- Pagination
- Spring Data JPA & Querydsl
- Auto Commit 설정
Mapping (List)
API 개발 시 List로 가장 많이 이용했던 것은 List Entity를 DTO 로 매핑하는 코드였다. 매핑 과정에서 이용할 수 있는 코드를 개선하기위해서 테스트했던 내용을 적어보았다.
아래는 각 매핑 방식에 대해서 50만건부터 200만건의 데이터를 10회에 걸쳐 테스트한 평균 값의 결과이다.
| 구분 | 50만건(ms) | 100만건(ms) | 150만건(ms) | 200만건(ms) |
|---|---|---|---|---|
| Loop-Based | 51.2 | 63.5 | 228.5 | 208.8 |
| Stream Collector Mutable List | 34.5 | 86.2 | 95.4 | 288.2 |
| Stream Immutable List | 32 | 97.5 | 100.9 | 134.4 |
| ModelMapper Collector Mutable List | 3,045.2 | 5,856.3 | 8,135.8 | 11,224.8 |
| ModelMapper Immutable List | 2,265.4 | 4,491.5 | 6,890.6 | 9,290.7 |
| MapStruct | 17.9 | 36 | 47.3 | 91.8 |
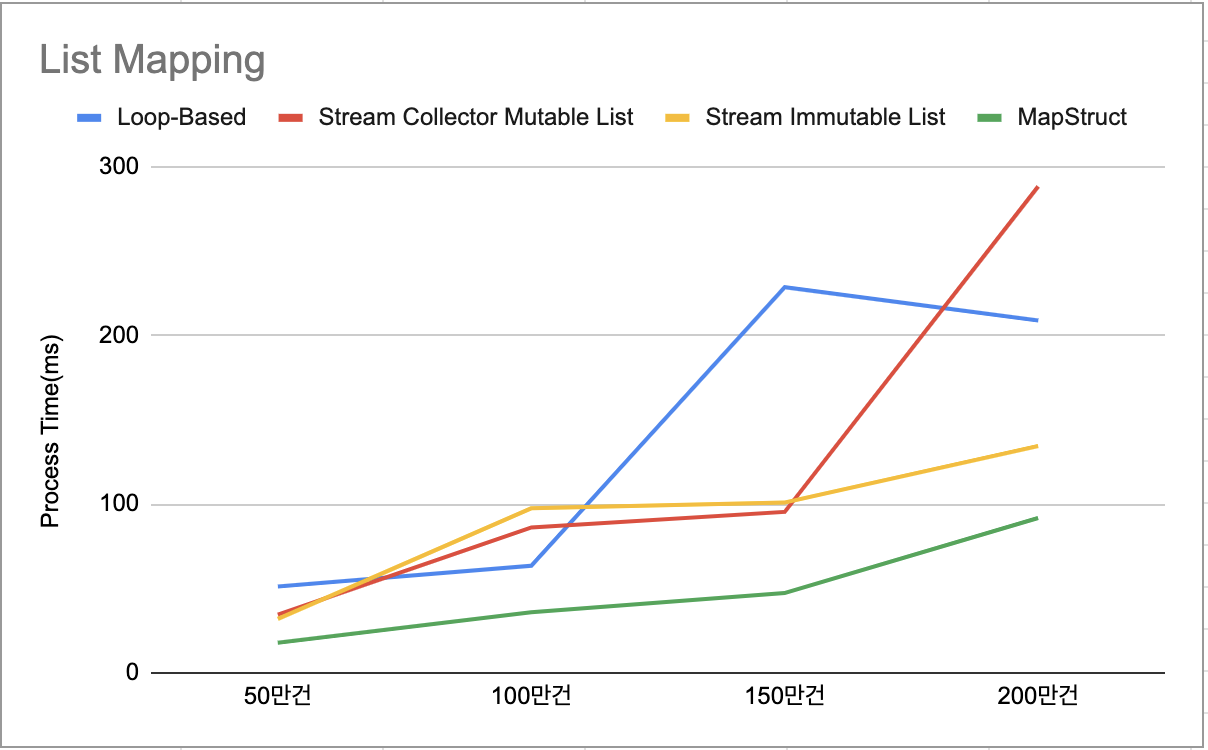
결과 분석
Loop-Based: 가장 기본적인 방식으로 ModelMapper를 제외했을 때 느린 성능을 보이고 있으며, 구현 과정에서 필드가 증가하게되면 그만큼 코드가 증가하는 단점이 있다.Stream Based: 변경 가능 리스트(Mutable List)와 불변 리스트(Immutable List)로 매핑하는 방식이 있으며, 기본 Java 8, 11과 비교했을 때 JIT 컴파일러 최적화 이후에는 더 나은 성능을 보였다.불변 리스트는 Java 16 이상 부터 가능
1 2
data.stream().map(ResponseDto::new).collect(Collectors.toList()); data.stream().map(ResponseDto::new).toList(); // 불변 리스트 반환
ModelMapper: 코드가 간단해져 간편하게 매핑을 할 수 있으나, 런타임시 매번 매핑의 전체 과정을 처리하기에 성능에 큰 이슈가 발생할 수 있다. → Reflection API 이용과 매핑 당시에 모델 구조를 분석하기에 구조가 복잡해질 수 록 성능에 이슈가 있다.MapStruct: ModelMapper과 다르게 컴파일 타임 기반에서 컴파일 단계에서 최적화 코드가 생성되어 성능 이슈 발생 가능성이 낮은 이점이 있다. 하지만, 모델이 복잡해지거나 특정 타입에 대해서는 조건부 매핑 과정이 필요하여 작업 비용이 증가하게 된다.
코드 개선 내용
구조가 복잡하지 않은 모델에 대해서는 Loop-Based 방식으로 Mapping을 진행했지만, 이후 구조가 점점 복잡해질 수 있는 가능성으로 Stream 기반 Mapping으로 코드를 개선하였다.
성능 향상을 위해 MapStruct를 이용하는게 낫지 않나 싶은 생각이 들었지만, 두 Mapping 방식이 차이가 날 정도의 데이터를 다루는 API가 없는데, 코드베이스를 확장시키면서까지 MapStruct를 사용해야하는 이점이 없기에 Stream으로 Mapping하였다.
Sort
시스템 성능 개선 내용에 가능한 비즈니스 로직에서 정렬을 하여 DB 서버의 부하을 줄여 성능을 개선하였다. 이 과정에서 커스텀 객체의 Sort 방법과 성능 테스트를 했던 내용을 적어보았다.
Application Side Sort
개발에 대한 편의성으로 대부분의 API 로직의 정렬의 경우 DB에서 처리하였다. 테스트 중에 자연스럽게 DB 서버에 부하가 발생했으며, 성능 개선을 목적으로 테스트를 진행했다.

실제 API의 결과 데이터 건수는 10 ~ 20건이며 이 기준으로 1만건까지 테스트했을 때 1만건 밑으로는 Application Side에서의 정렬이 빠른 것을 볼 수 있었다.
서버의 스팩에 따라 다르지만, 적은 수의 데이터인 경우 Application Side에서의 정렬이 빠른 것을 볼 수 있으며 데이터가 많아질 수록 차이는 줄어들어 특정 건수부터는 DB에서의 정렬이 더 빨라지게 된다.
개발의 편리성에 의존하지말고 상황에 맞게 구현하자…
Sort (Type & Inteface)
성능 개선 이후 추가적으로 타입, 인터페이스별 테스트를 진행했으며, 타입 정렬에 대한 테스트 케이스는 Number, String, Date 그리고 Comparable과 Comparator 인터페이스 테스트와 Comparator의 경우 정적 객체를 추가로 선언하여 테스트를 진행하였다.
1
2
3
4
5
6
7
//Static Comparator 설정
public class SortDto {
public static final Comparator<SortDto> BY_DATE_ASC = Comparator.comparing(SortDto::getDate);
public static final Comparator<SortDto> BY_NAME_ASC = Comparator.comparing(SortDto::getName);
public static final Comparator<SortDto> BY_ID_ASC = Comparator.comparingLong(SortDto::getId);
...
}
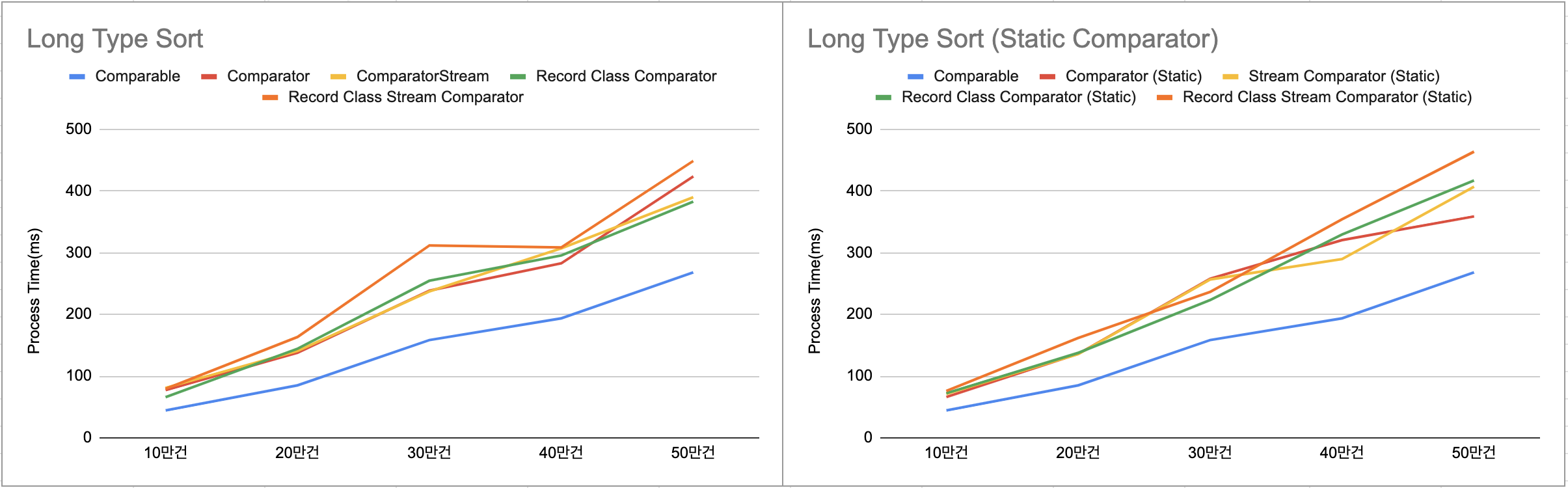
Long 타입 정렬
| 구분 | 10만건(ms) | 20만건(ms) | 30만건(ms) | 40만건(ms) | 50만건(ms) |
|---|---|---|---|---|---|
| Comparable | 44.4 | 85 | 158.4 | 193.6 | 268.1 |
| Comparator | 77.4 | 137.8 | 238.5 | 282.7 | 423.6 |
| Comparator Stream | 81 | 140.7 | 237.1 | 307.1 | 389.8 |
| Record Class Comparator | 66 | 144.3 | 254.6 | 295.4 | 382.7 |
| Record Class Stream Comparator | 79.4 | 163.4 | 311.7 | 308.5 | 448.6 |
| Comparator (Static) | 66.2 | 136.1 | 257.7 | 320.4 | 358.7 |
| Comparator Stream (Static) | 71.3 | 135.7 | 256.6 | 289.6 | 406.8 |
| Record Class Comparator (Static) | 72.3 | 137.7 | 223.2 | 329.5 | 417 |
| Record Class Stream Comparator (Static) | 75.9 | 161.9 | 236.3 | 354.1 | 463.6 |
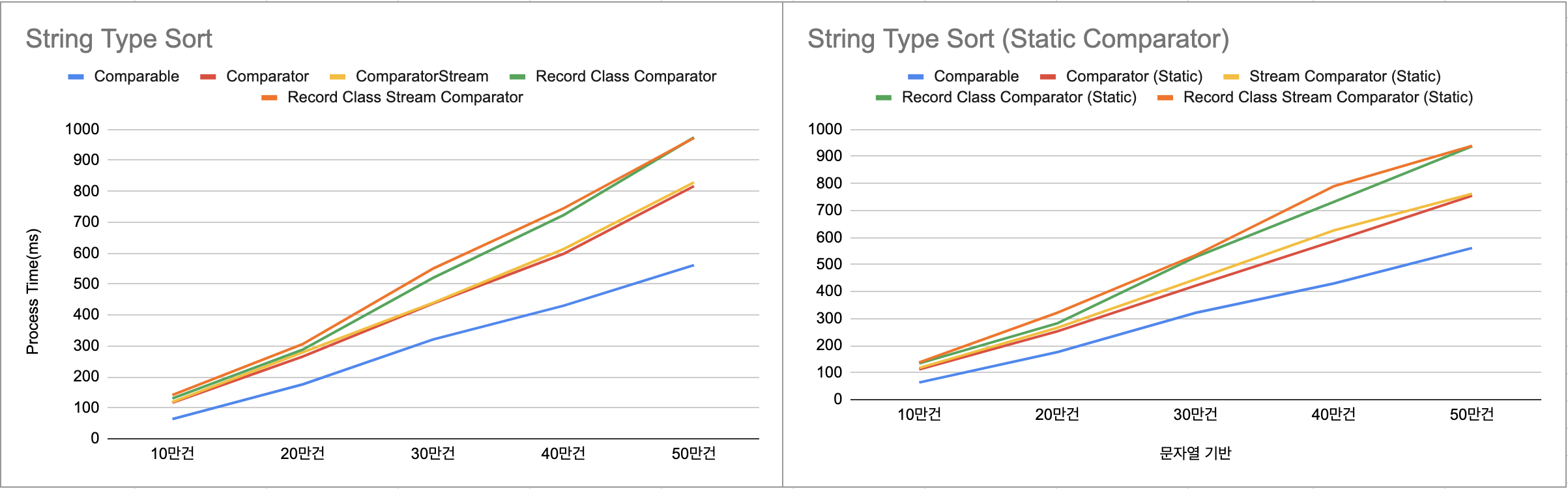
String 타입 정렬
| 구분 | 10만건(ms) | 20만건(ms) | 30만건(ms) | 40만건(ms) | 50만건(ms) |
|---|---|---|---|---|---|
| Comparable | 63.5 | 175.8 | 321.2 | 430.1 | 561.3 |
| Comparator | 116.8 | 265.8 | 437.5 | 597.8 | 816.9 |
| Comparator Stream | 118.8 | 279.2 | 439.6 | 613 | 828.7 |
| Record Class Comparator | 130.1 | 288.1 | 520.2 | 723.2 | 974.2 |
| Record Class Stream Comparator | 141.1 | 306.3 | 550.3 | 744.9 | 972.6 |
| Comparator (Static) | 112.1 | 252.8 | 421.7 | 587.3 | 754.8 |
| Comparator Stream (Static) | 117 | 266 | 445.1 | 626.5 | 762.1 |
| Record Class Comparator (Static) | 134.1 | 282.5 | 528 | 732.1 | 937.8 |
| Record Class Stream Comparator (Static) | 137.5 | 321.8 | 535 | 789.7 | 939.7 |
Date 타입 정렬
| 구분 | 10만건(ms) | 20만건(ms) | 30만건(ms) | 40만건(ms) | 50만건(ms) |
|---|---|---|---|---|---|
| Comparable | 72.8 | 133.2 | 244.8 | 293.5 | 356.5 |
| Comparator | 101.9 | 193.5 | 354.1 | 445.8 | 555.3 |
| Comparator Stream | 116.4 | 207.5 | 339.2 | 525.2 | 525.8 |
| Record Class Comparator | 100.6 | 208.3 | 334.9 | 458 | 587.7 |
| Record Class Stream Comparator | 98.1 | 208.6 | 361.1 | 511.5 | 634.1 |
| Comparator (Static) | 97.2 | 198.8 | 373.8 | 423 | 526.5 |
| Comparator Stream (Static) | 93.4 | 202.3 | 325.7 | 473.5 | 581.9 |
| Record Class Comparator (Static) | 122.1 | 228.2 | 376.3 | 499.7 | 606.2 |
| Record Class Stream Comparator (Static) | 107.4 | 221.3 | 322 | 473.8 | 617.2 |
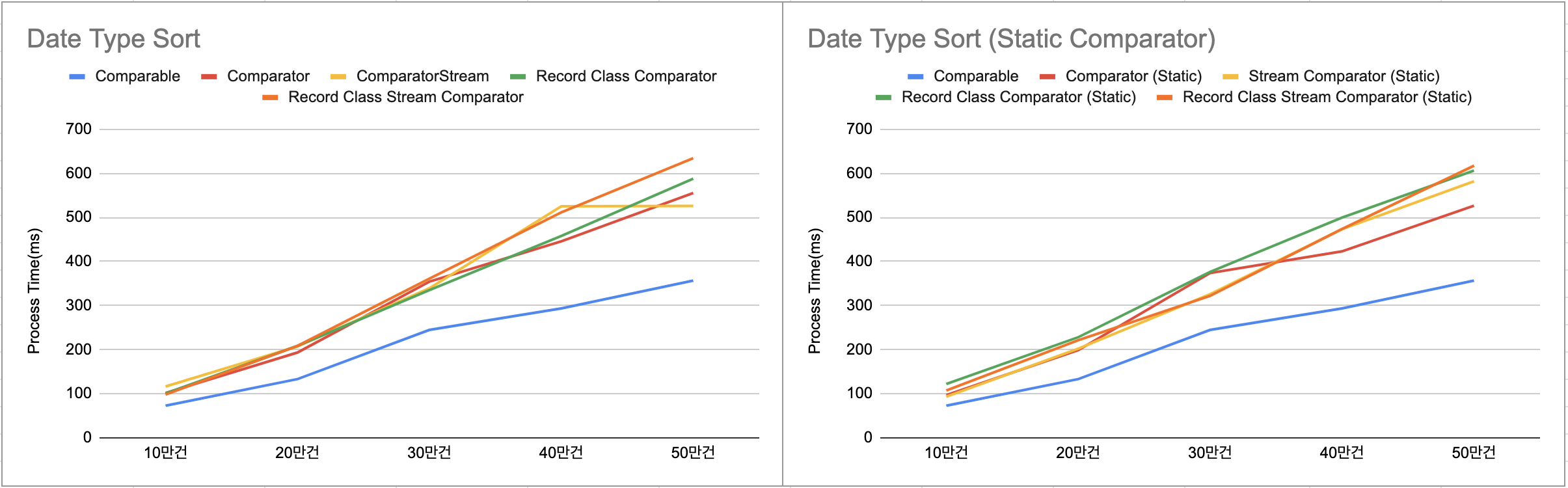
결과 분석
정렬 데이터가 어떻게 구성되어있는지에 따라 성능이 다를수 있다. 여러 케이스에서 테스트해서 확인했을 때 결과는 아래와 같다.
타입별 성능 순서- Long(숫자) > Date(날짜) > String(문자열)
정렬 인터페이스별 성능 순서- Comparable > Comparator(Stream 포함) ≈ Record Class Comparator(Stream 포함)
Record Class: Java 16부터 사용 가능하며 불변(Immutable) 객체 관리용 클래스이다.- 정렬에 대해서는 일반 클래스와 Record 클래스의 성능 차이는 없는 수준이다.
Static Comparator: 프로그램 전체에서 재사용성이 좋으며, 유지보수에 대한 이점이 있다.- Comparator를 직접 사용하는 방법과 정적 필드를 이용하는 방식에서 성능 차이는 없는 수준이다.
타입별 정렬의 경우 단순한 타입일수록 성능이 높은 것을 확인할 수 있다. 인터페이스의 경우 Comparable이 가장 좋은 성능을 보이고, 이 외의 인터페이스는 서로 비슷한 성능을 보인다.
코드 개선 내용
Comparable인터페이스의 경우 처리속도가 좋다. 그렇지만, 동적 정렬에 어려움, 다중 필드에 대한 코드 복잡성 그리고 유연성이 낮은 단점으로 변경이 없고 간단한 정렬이 필요한 로직의 경우 적용- 정적 필드 사용 여부에 대한 성능의 차이는 크게 없는 것으로 보이며, 동적 필드에 대한 유연성과 유지보수 및 재사용성에 대한 이점을 위해
Static Comparator을 이용해 로직 구현으로 코드 개선
Pagination
Offset Based Pagination과 Cursor Based Pagination
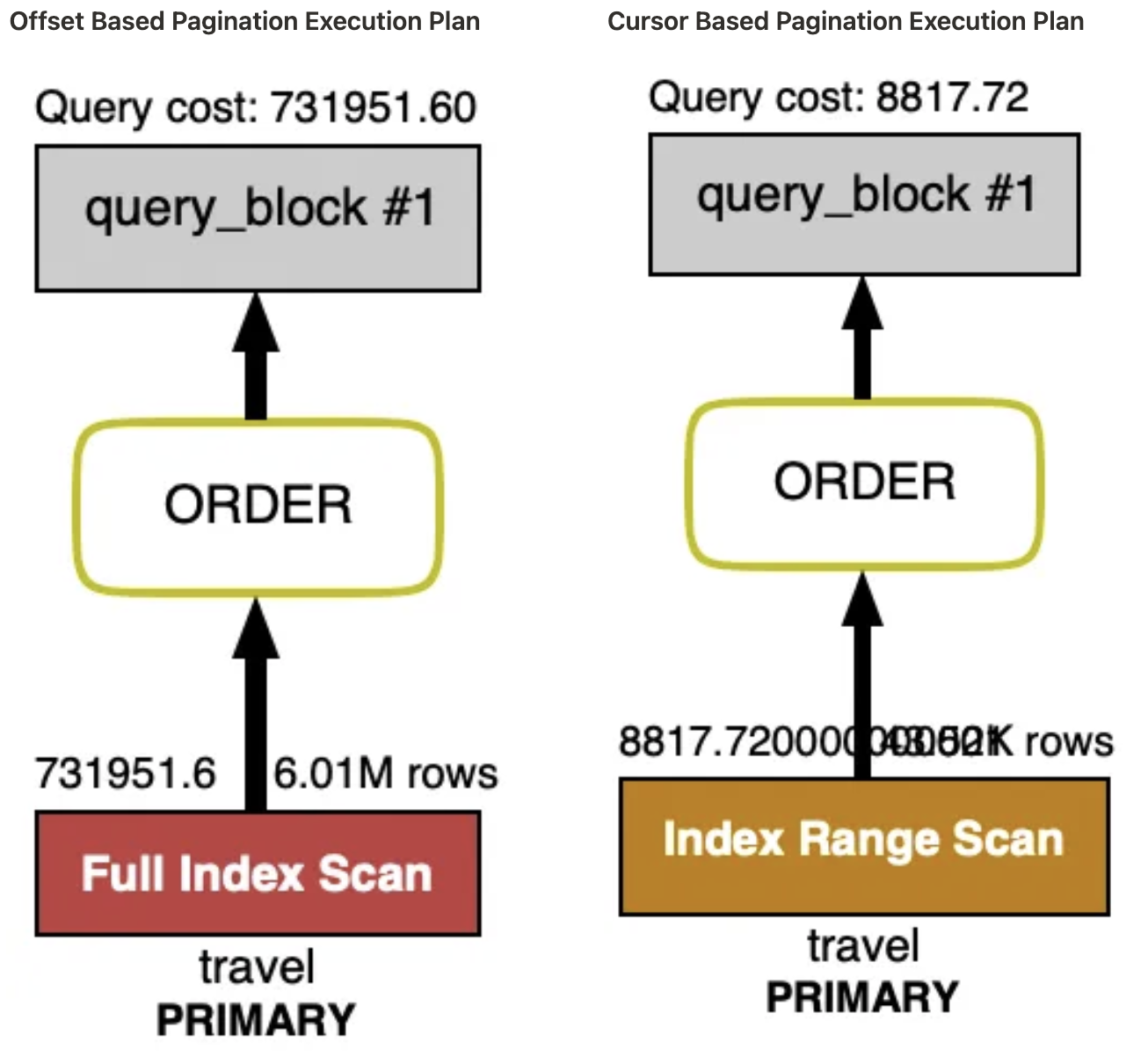
Offset Based Pagination은 Offset으로 데이터를 찾아야할 때 그 만큼의 Row를 조회하고 버리는 과정을 거쳐 해당 Offset에서 데이터를 조회하게 된다. 결국 처음부터 원하는 위치까지 찾는 과정이 발생하여 Full Table Scan이 발생하게 된다.
예로, 약 5천만건의 샘플 데이터를 추가하고 구현한 API를 테스트 했을 때 정렬 이후 Offset이 큰 데이터를 조회할 수록 실행시간이 급격하게 증가하여 성능 이슈가 발생했다.

Cursor Based Pagination은 특정 기준의 데이터의 다음의 데이터를 조회하는 페이징 처리이다. Cursor는 응답해준 마지막 데이터의 식별자 값이다. Offset처럼 처음부터 찾는 방식이 아니라 식별자 값을 기반으로 찾는 방식이기 때문에 성능 향상을 볼 수 있다. 그렇지만, 고려해야할 부분으로 Cursor는 PK와 같은 유니크한 식별자여야 한다.

Cursor Based Pagination 이용시 고려해야할 점
Cursor 기반 페이징 처리로 구현하는 과정에서 고려해야할 부분이 많이 있었다. 유니크 식별자를 생각했을 때 세부적인 구성의 어려움이 있다. 구현 과정에서 여행정보 현황을 여행 시작일시 기준 내림차순으로 사용자에게 보여져야할 때 마주친 이슈는 아래와 같다.
여행 정보 PK가 Cursor일 때→ 신규 여행정보를 입력했는데 기존 여행정보보다 시작일시가 빠른 데이터가 추가될 경우에 값 중복 이슈 발생예) 1,2,4,3 순으로 조회되며, 3을 Cursor 값으로 넘기게되어 다음 페이징에서 4가 중복 조회됨
정렬 필드가 Cursor일 때→ 요구사항에서 다른 정보에 대한 정렬 필요한 경우정렬 필드에 대한 Cursor 설정 가능성 (유니크 식별자)
정렬 필드가 더 생길 경우 해당 필드에 대한 Index 설정이 필요
인덱스가 많아지며 Write 성능 감소, Storage 사용량 증가 이슈가 발생할 수 있음
중첩 검색 조건이 발생할 때→ 요구사항에 여행 시작일과 종료일 검색 조건이 필요하며, 여행 시작일과 종료일이 내림차순으로 정렬되어야 하는 경우여행 종료일에 대한 Cursor 설정 가능성 (유니크 식별자)
여행 시작일과 종료일의 인덱스 설정
여행 시작일 필드가 여러 인덱스로 구성되어 Write 성능 감소 및 Optimizer에서의 적절한 인덱스 선정 이슈
Cursor 정의에 대해서 두 경우에 대해서 고려해보았을 때 이러한 이슈 혹은 고려해야할 사항이 있다. 정리하면, 정렬에 대한 필드를 Cursor로 두며, 요구사항과 성능 이슈 여부를 확인하여 조절해야한다.
Offset Based Pagination 개선
Cursor Based Pagination을 이용하면 성능 향상에 이점이 크지만, 과도한 검색 조건 및 복잡한 로직으로 인해서 불가능할 경우가 있다.
별도 InMemoryDB를 사용이 불가능하거나, 대안이 없는 경우 Offset Based Pagination을 적용해야할 수도 있다. 이때 개선 방안으로 커버링 인덱스(Covering Index)를 이용할 수 있다.
1
2
3
4
5
6
7
8
9
10
SELECT a.*
from travel a
JOIN (
select travel_id
from travel
where member_id = 6000
order by start_date desc
limit 400000, 15
) b
on a.travel_id = b.travel_id
travel_id는 PK이며 member_id와 start_date 필드에 인덱스를 생성
커버링 인덱스 방식은 조건절+정렬+페이징을 JOIN의 쿼리로 구성하여 대상 테이블과 JOIN하는 방식이다. 커버링 인덱스 사용 여부에 대해 성능을 비교했을 때 10배 이상 차이가 났다.

처음에 위 설정에 대해서 이미 페이징 처리를 하는 쿼리가 있는데 왜? JOIN을 하는게 빠를까? 라고 생각이 들었다. 이 의문에 대해서 실행계획을 확인해보았을 때 인덱스 적용 여부에 대해서 알게되었다.

JOIN 구문에 있는 쿼리에서 전체 필드 조회를 했을 때 실행계획을 보면, 적용 가능한 인덱스를 확인할 수 있다. 그런데, 실제 인덱스가 사용되지 않는 것을 볼 수 있다. Extra = NULL
반면에, 커버링 인덱스의 실행 계획을 보면 JOIN에 사용된 테이블(DERIVED 테이블)에서 인덱스가 사용(Using index)된 것을 확인할 수 있다.

단순 Offset 방식에서는 인덱스가 포함되지 않은 필드들을 포함하게 되어 인덱스가 사용되지 않는다. 그래서 4만번의 Offset을 건너뛰어 조회하게 된다.
커버링 인덱스의 JOIN의 쿼리는 쿼리에서 필요한 인덱스 컬럼으로만 이루어져있어 테이블 접근 없이 인덱스 내부에서 쿼리 결과를 반환하게 된다. 이에 인덱스 적용을 통해 15건의 PK를 반환하고 반환한 PK로 Offset 이용 없이 15건의 데이터를 반환하게 되면서 성능이 차이가 나게 된다.
조금 더 상세히보면 전체 필드를 조회하는 쿼리와 인덱스가 포함된 필드만을 조회하는 쿼리의 속도 또한 10배 이상 차이 나는 것을 볼 수 있다.

Spring Data JPA에서 Covering Index 구현 방법
Spring Data JPA에서 일반적으로 사용하는 방식으로 Covering Index 구현은 불가능하다. 이유는 인덱스가 포함된 필드가 아닌 전체 필드를 조회하기 때문이다.
JPQL 또는 Querydsl을 이용해 가능하나 두 방법에도 차이가 있다.
JPQL: 한 번의 DB Connection으로 Covering Index 사용이 가능하다.Querydsl: 두 번의 DB Connection으로 Convering Index 사용이 가능하다.
JPQL의 방식은 앞에서 정리한 방식과 같이 직접 SQL을 작성으로 가능하나, 타입 안정성에 대한 이슈가 발생할 수 있다. 이러한 점에서 Querydsl을 이용할 수 있는데, Querydsl에서는 서브쿼리 Join 방식을 지원하지 않는다. 그렇다보니 2번의 DB 엑세스로 Convering Index를 구현해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public List<TravelResponseDto> getTravels(Long memberId, Integer page, long pageSize) {
//Index 적용 결과 조회
List<Long> travelIds = queryFactory
.select(travel.travelId)
.from(travel)
.where(travel.memberId.eq(memberId))
.orderBy(travel.startDate.desc())
.offset(page)
.limit(pageSize)
.fetch();
//Index 적용 결과를 조건으로 결과 조회
List<TravelResponseDto> travels = queryFactory
.select(
new QTravelResponseDto(travel.travelId, travel.travelName, travel.startDate, travel.endDate)
)
.from(travel)
.where(travel.travelId.in(travelIds))
.orderBy(travel.startDate.desc())
.fetch();
}
Join을 하는 방식이 아닌 서브쿼리 JOIN 결과를 먼저 조회하고 이 결과 조건으로 실제 필요한 결과를 조회하는 방식으로 Querydsl에서의 Convering Index를 이용할 수 있다.
결과 분석
Offset Based Pagination, Covering Index, Cursor Based Pagination 비교

| Covering Index | Cursor Based Pagination |
|---|---|
| - Offset과 약 10배 차이 | - Offset과 약 1000배 차이 - Covering과 약 100배 차이 |
SQL 개선 내용
유니크 식별자로 Cursor를 구분하여 구현할 수 있다면 Cursor Based Pagination를 이용
Cursor Based Pagination이 불가능한 경우 Offset Based Pagination을 사용하되 Covering Index를 활용
복잡한 SQL의 경우 JPQL로 Convering Index 이용 → 타입 안정성을 보장할 수 없음
단순한 SQL의 경우 Querydsl를 이용해 Covering Index 로직 구현 → 추가적인 DB 엑세스가 발생
Spring Data JPA & Querydsl
Spring Boot에 대해 공부하고 Hibernate & JPA, Spring Data JPA, QueryDSL에 대해서 간단하게 정리했을 때 Hibernate & JPA, Spring Data JPA의 경우 영속성 컨텍스트(1차 캐시) 활용이 있고, Querydsl는 타입 안정성과 필요한 필드를 조회할 수 있다는 점에서 네트워크 및 메모리 사용률 감소의 이점이 있다고 생각했다.
영속성 컨텍스트에 대한 이점이 있지만, 대부분의 비즈니스 로직을 Querydsl로 구현했다. 이유는, 모든 API가 Self Data Access이며 동일한 요청이 병렬로 실행될 수 없어 영속성 컨텍스트에 대한 이점을 살리지 못할 것 같는 생각이였다.
그렇지만, Querydsl 위주의 로직은 구현했을 때 아래와 같은 단점이 있었다.
- 코드베이스 확장
- SQL 변경 시 매번 Build를 통해 QClass 파일 갱신
코드베이스 확장의 경우 Spring Data JPA를 비교했을 때 프로젝트 파일과 전체 코드양에 많아지는 현상이 있다. 그 예는 아래와 같다.
Querydsl
1
2
3
4
5
6
7
8
9
10
@Transactional(readOnly = true)
public void findTravel(final Long travelId, final Long memberId){
//1. 내 여행 정보 조회
Travel travel = travelRepository.findByTravelIdAndMemberId(travelId, memberId)
.orElseThrow(() -> new CommonException(ResponseCode.TRAVEL_NOT_FOUND));
//2. 여행 지역 현황 조회
List<TravelRegionResponseDto> travelRegion = travelRegionRepository.getTravelRegions(travelId);
}
1
2
3
4
//TravelRegionRepositoryCustom Interface
public interface TravelRegionRepositoryCustom {
List<TravelRegionResponseDto> getTravelRegions(final Long travelId);
}
1
2
3
4
5
6
7
//TravelRegionRepositoryImpl Classs
public Class TravelRegionRepositoryCustom {
public List<TravelRegionResponseDto> getTravelRegions(final Long travelId){
//구현부
...
}
}
Spring Data JPA
1
2
3
4
5
6
7
8
9
10
11
12
13
@Transactional(readOnly = true)
public void findTravel(final Long travelId, final Long memberId){
//1. 내 여행 정보 조회
Travel travel = travelRepository.findByTravelIdAndMemberId(travelId, memberId)
.orElseThrow(() -> new CommonException(ResponseCode.TRAVEL_NOT_FOUND));
//2. 여행 지역 현황 조회
List<TravelRegion> travelRegion = travel.getTravelRegions(travelId);
//Entity to ResponseDto로 변환
...
}
위 2가지 케이스를 확인했을 때 Querydsl의 경우 2개 파일이 추가적으로 필요하며 인터페이스에는 선언 그리고 클래스에는 구현부를 작성해주어야했다. 반면에, Spring Data JPA의 경우 여행 정보 조회 후 엔티티 연관 관계를 통해 단순히 TravelRegions 필드를 호출만 하면 된다.
비교했을 때 코드 라인수가 최소 5배의 차이를 보일때가 있다. 이러한 부분에서 코드베이스가 확장되어 프로젝트가 커지는 현상이 있었다. 큰 규모의 프로젝트는 아니지만 규모가 점점 커질 수록 프로젝트 관리가 어려워질 수 있으며 이에 전반적으로 코드 개선작업을 아래와 같은 규칙으로 진행했다.
코드 개선 내용
Querydsl
Text, Clob와 같은 데이터 크기가 큰 필드가 있는 엔티티 참조를 피해야할 때
검색 필터가 많고 다양한 조합이 필요한 동적 쿼리가 필요할 때
스칼라 서브쿼리 혹은 서브쿼리가 필요할 때
Spring Data JPA의 메서드 네이밍 쿼리의 한계 발생할 때
Spring Data JPA
단순한 SQL일 때
단일 데이터 조회 및 연관 관계의 엔티티를 활용할 때
같은 트랜잭션에서의 영속성 컨텍스트를 활용할 때
이전부터, MyBatis를 이용해 개발하다보니 익숙한 Querydsl에 치우쳤던 것 같다.
Auto Commit 설정
부하 테스트 과정에서의 Slow Query 로그를 확인했을 때 아래와 같이 set autocommit = 0/1 쿼리가 반복적으로 실행되고 있는 것을 확인했다.

Auto Commit의 경우 별도 Commit 명령 없이 자동으로 모든 명령을 즉시 반영한다. 명령어 호출 시점에 대해서 확인해보았을 때 아래와 같은 케이스에서 Auto Commit 설정 로그들을 확인할 수 있었다.
@Transactional선언이 되어있을 경우 각 서비스의 트랜잭션 전/후로set autocommit=?이 실행된다.
세부 로그를 통해서 관련 클래스의 내용을 확인해보니 hibernate.connection.provider_disables_autocommit 옵션 값에 따라 Auto Commit 호출에 영향이 발생하며 아래 애플리케이션 프로퍼티 설정으로 Auto Commit 설정을 비활성할 수 있다.
1
spring.datasource.hikari.auto-commit: false
spring.datasource.hikari.auto-commit이 false이면 hibernate.connection.provider_disables_autocommit는 true가 되어 Auto Commit이 비활성화된다.
@Transactional 선언이 없는 메서드의 경우 Auto Commit 설정이 호출되지 않았다. 코드수 감소를 최소화하기 위해 여러 서비스에 선언한 메서드들을 재사용했었으며, 조회 로직에서도 성능 향상 @Transaction(readOnly = true) 설정을 했던 점이 set autocommit=0/1 명령어 호출에 큰 영향이 있었던 것 같다.
Auto Commit 비활성화애 따른 성능 향상 결과
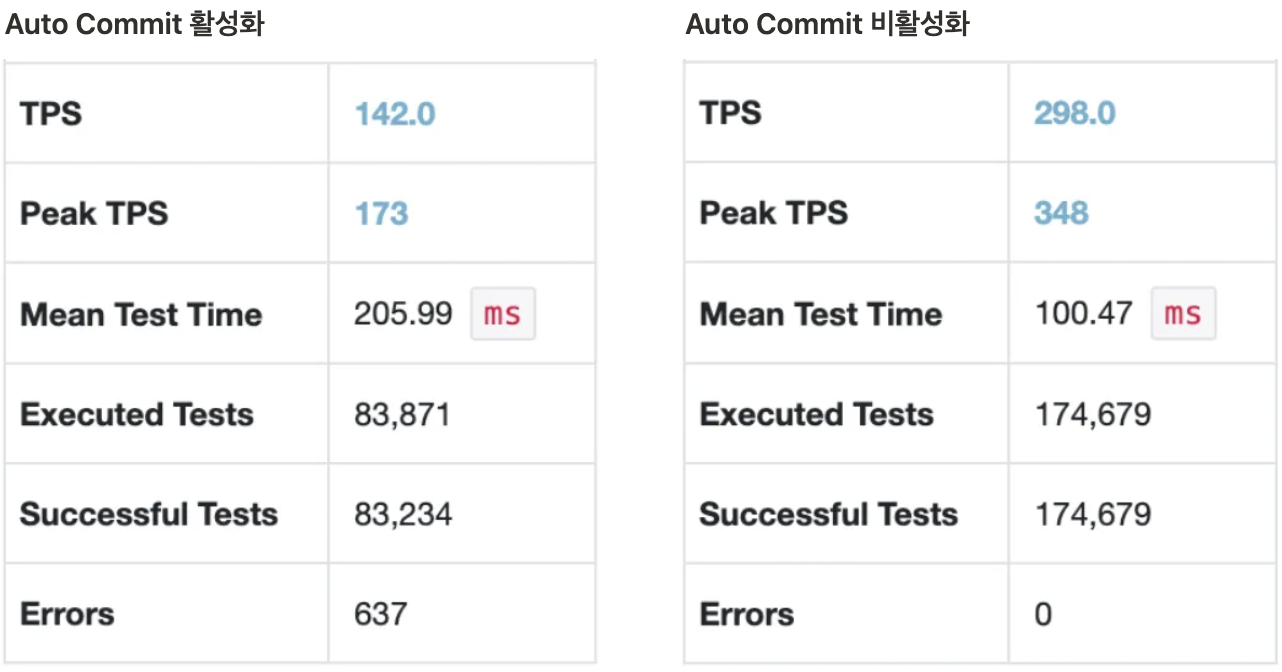
- Auto Commit 활성화 여부에 따라 성능은 약 2배의 차이가 나는 것을 확인했다.