대용량 트래픽 경험해보기(5/14) - Spring Batch를 이용한 샘플 데이터 추가
테스트 데이터 분석
전체 인구에 대한 통계 조사는 아니지만, 2023년 12월 기준으로 최근 1년이내 국내 여행 평균 횟수는 8.23이다.
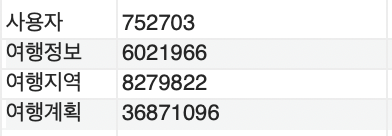
유사 서비스 분석을 통해 확인한 2023년 평균 국내여행 고유 방문자(752,703명)을 기준으로 데이터를 측정했으며, 주요 기능에 대한 예상 데이터 수는 아래와 같다.
| 구분 | 데이터 수 |
|---|---|
| 여행 정보 | 약 600만개 |
| 여행 지역 | 약 800만개 |
| 여행 계획 | 약 3,600만개 |
테스트 데이터 배치 환경
테스트 데이터를 추가하는 가장 빠른 방법은 Procedure를 작성해서 하는 방법이 가장 빠르다고 생각했다. 하지만, SQL로 작성해서 하는 방법보다 배치 작업에 대한 경험의 필요성으로 Spring Batch를 통해 작업을 진행했다.
Spring Batch
TravelJobConfig.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
@Slf4j
@Configuration
public class TravelJobConfig {
public static final String JOB_NAME = "TRAVEL_JOB";
private final Step travelStep1;
private final Step travelStep2;
public TravelJobConfig(
@Qualifier(TravelStepConfig.STEP_NAME_1) Step travelStep1,
@Qualifier(TravelStepConfig.STEP_NAME_2) Step travelStep2
) {
this.travelStep1 = travelStep1;
this.travelStep2 = travelStep2;
}
@Bean(JOB_NAME)
public Job tavelJob(JobRepository jobRepository) {
Job job = new JobBuilder(JOB_NAME, jobRepository)
.incrementer(new RunIdIncrementer())
.start(travelStep1)
.next(travelStep2)
.build();
return job;
}
}
TravelStepConfig.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
@Slf4j
@Configuration
@RequiredArgsConstructor
public class TravelStepConfig {
public static final String TASKLET_NAME = TravelJobConfig.JOB_NAME + ".TRAVEL_TASKLET";
public static final String STEP_NAME_1 = TravelJobConfig.JOB_NAME + ".TRAVEL_STEP_1";
public static final String STEP_NAME_2 = TravelJobConfig.JOB_NAME + ".TRAVEL_STEP_2";
private final JobParameter jobParameter;
private final JdbcTemplate jdbcTemplate;
private final DataSource dataSource;
private Long lastId = 0L;
@Bean(STEP_NAME_1)
@JobScope
public Step travelStep1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder(STEP_NAME_2, jobRepository)
.tasklet(maxIdTasklet(), transactionManager)
.build();
}
@Bean(TASKLET_NAME)
@StepScope
public Tasklet maxIdTasklet() {
return (contribution, chunkContext) -> {
lastId = jdbcTemplate.queryForObject("SELECT MAX(member_id) FROM travel", Long.class);
lastId = lastId == null ? 0L : lastId;
return RepeatStatus.FINISHED;
};
}
@Bean(STEP_NAME_2)
@JobScope
public Step travelStep2(JobRepository jobRepository, PlatformTransactionManager transactionManager
) throws Exception {
return new StepBuilder(STEP_NAME_2, jobRepository)
.<MemberResponseDto, List<TravelDto>>chunk(jobParameter.getChunkSize(), transactionManager)
.reader(pagingItemReader())
.processor(itemProcessor())
.writer(jdbcBatchItemWriter())
.build();
}
@Bean
@StepScope
public JdbcPagingItemReader<MemberResponseDto> pagingItemReader() throws Exception {
JdbcPagingItemReader<MemberResponseDto> reader = new JdbcPagingItemReader<>();
reader.setDataSource(dataSource);
reader.setFetchSize(jobParameter.getChunkSize());
reader.setPageSize(jobParameter.getChunkSize());
reader.setRowMapper(new BeanPropertyRowMapper<>(MemberResponseDto.class));
SqlPagingQueryProviderFactoryBean queryProvider = new SqlPagingQueryProviderFactoryBean();
queryProvider.setDataSource(dataSource);
queryProvider.setSelectClause("SELECT member_id");
queryProvider.setFromClause("FROM member");
queryProvider.setWhereClause("WHERE member_id > :lastId");
Map<String, Order> sortKeys = new HashMap<>();
sortKeys.put("member_id", Order.ASCENDING);
queryProvider.setSortKeys(sortKeys);
reader.setQueryProvider(Objects.requireNonNull(queryProvider.getObject()));
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("lastId", lastId);
reader.setParameterValues(parameterValues);
return reader;
}
@Bean
@StepScope
public ItemProcessor<MemberResponseDto, List<TravelDto>> itemProcessor(){
return item -> {
List<TravelDto> travels = new ArrayList<>();
Random random = new Random();
int travelCount = random.nextInt(6)+3;
int[] daysRange = new int[]{1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 4};
LocalDate start = LocalDate.of(2023, 1, 1);
LocalDate end = LocalDate.of(2023, 12, 31);
for (int i = 0; i < travelCount; i++) {
// 시작일부터 끝일까지의 날짜 중 랜덤으로 하나 선택
int startDay = (int) start.toEpochDay();
int endDay = (int) end.toEpochDay();
long randomStartDate = startDay + random.nextInt(endDay - startDay);
int plusEndDay = daysRange[random.nextInt(daysRange.length)];
// 선택된 날짜를 LocalDate 객체로 변환
LocalDateTime startDate = LocalDate.ofEpochDay(randomStartDate).atStartOfDay();
LocalDateTime endDate = LocalDate.ofEpochDay(randomStartDate).plusDays(plusEndDay).atStartOfDay();
String travelName = null;
if (i % 2 == 0)
travelName = "친구 여행";
else if (i % 3 == 0)
travelName = "가족 여행";
TravelDto travel = new TravelDto();
travel.setMemberId(item.getMemberId());
travel.setStartDate(startDate);
travel.setEndDate(endDate);
travel.setTravelName(travelName);
travel.setCreatorId(item.getMemberId());
travels.add(travel);
lastId = item.getMemberId();
}
return travels;
};
}
@Bean
public JdbcBatchListItemWriter<TravelDto> jdbcBatchItemWriter() {
JdbcBatchItemWriter<TravelDto> itemWriter = new JdbcBatchItemWriterBuilder<TravelDto>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql(
"INSERT INTO travel (member_id, travel_name, start_date, end_date, create_date, creator_id) " +
"VALUES (:memberId, :travelName, :startDate, :endDate, now(), :creatorId)"
)
.dataSource(dataSource)
.build();
itemWriter.afterPropertiesSet(); //Writer들이 실행되기 위해 필요한 필수값들이 제대로 세팅되어있는지를 체크
return new JdbcBatchListItemWriter<>(itemWriter);
}
JdbcBatchListItemWriter.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Slf4j
@RequiredArgsConstructor
public class JdbcBatchListItemWriter<T> implements ItemWriter<List<T>>, ItemStream, InitializingBean {
private final JdbcBatchItemWriter<T> delegate;
@Override
public void write(Chunk<? extends List<T>> chunk) throws Exception {
final Chunk<T> flattenedList = new Chunk<>(new ArrayList<>());
for (final List<T> list : chunk) {
flattenedList.addAll(list);
}
delegate.write(flattenedList);
}
@Override
public void afterPropertiesSet() throws Exception {
//do Nothing
}
}
JobParameter.java
1
2
3
4
5
6
7
8
9
10
@Getter
@NoArgsConstructor
@JobScope
@Component
public class JobParameter {
@Value("${chunk-size:10000}")
private int chunkSize;
}
Spring Batch 결과
여행정보 데이터만 예로 Spring Batch에서 JdbcBatch, Spring Data JPA saveAll 2개의 방식으로 chunk size를 10,000으로 테스트를 했을 때 아래와 같은 결과를 얻을 수 있었다.
| 구분 | 600만건 분당 처리량 |
|---|---|
| Spring Batch - JPA saveAll | 약 5,000건 |
| Spring Batch - JdbcBatch Insert | 약 900,000건 |
Batch 작업 결과
처음 테스트 데이터를 추가할 때 Procedure를 짜서 실행하는게 가장 빠르다고 생각했고 회원 데이터의 경우에는 Procedure를 통해 데이터를 추가했다. 하지만, 여행과 관련된 정보에 대해서는 Spring Batch를 사용한 이유는 언젠가는 대용량 데이터를 가공하고 처리해야하는 상황이 생길 것이고 이번 기회에 한번 학습하고자 했다.
이번 Spring Batch를 이용하면서 대량의 데이터에 대해서 추가하는 방식에서 Spring Data JPA보다 Jdbc BulkInsert 빠르다는 글을 보았고 실제 코드를 작성하여 테스트 해보았을 때 위 결과처럼 엄청나게 큰 차이를 확인할 수 있었다.
트러블 슈팅
문제 상황 발생
각 테이블에 대해 필요 인덱스 추가와 인덱스가 정상적으로 사용되는지까지 사전 작업을 완료한 상태였다. 그렇지만, 테스트 데이터 추가 후 리스트 쿼리 테스트를 진행하면서 아래 결과와 같이 여행 정보 현황 조회 SQL에서 이슈가 발생했다.

원인 추론 및 분석
페이징을 처리할 때 Offset Based Pagination을 자주 이용했었다. 이번에도 같은 방식으로 데이터를 조회했다. Offset이 낮을 때는 성능상 이슈는 없었지만 Offset이 커질 수록 데이터를 가져오는 속도가 느려지고 있었다. 실행계획을 보면 아래와 같이 Full Scan인 것을 볼 수 있다. 너무나 당연하다는 듯이 자연스럽게 Offset Based Pagination을 이용했다는 것이 이슈를 발생시키게 되었다.
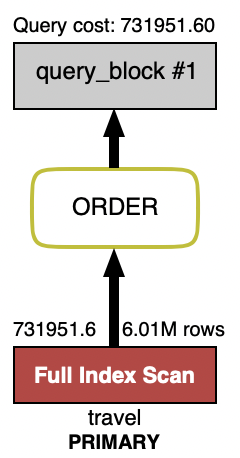
Pagination 전략은 2가지가 있다. 첫번째로 Offset Based Pagination, 두번째로 Cursor Based Pagination이다. Offset Based Pagination의 경우 왜 느린 것인가를 찾아보았는데, Offset 값이 클수록 더 많은 Row을 건너뛰어야 한다고 한다. 예를들어, 4,000,001부터 조회한다고 했을 때 앞의 4,000,000까지는 건너뛴다는 의미이다.
건너뛴다로 표현했지만, 실제로 그 만큼 데이터를 조회하고 버리는 것(discard)이라고 한다. 즉, 0에서 4,000,000까지 조회하고 버린 후에 4,000,001부터 조회하게 된다. 결국, 4백만건의 데이터를 조회하는 것이고 그 만큼 I/O가 발생하여 느리다.
해결 방안
Cursor Based Pagination
해결방안으로 Cursor Based Pagination 이용하기로 했고 그 결과 Offset을 처리했을 때와는 달리 index range scan이 발생했고 Query 실행 시간이 약 2800배 이상 차이나는 것을 볼 수 있다.

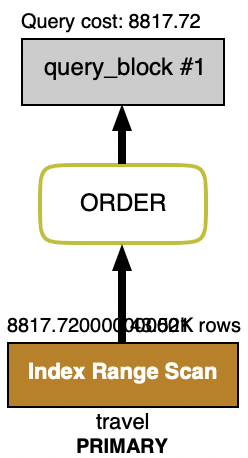
조회해야할 데이터가 뒤에 있는 경우에는 Cursor 기반의 페이징 처리가 성능이 좋지만, 처음 10000건에 대한 데이터 조회를 할 때는 어떻게 될까?

이 경우 실행 속도는 2배가 넘게 차이 나지만, 체감상으로 큰 차이가 없을 정도의 실행 시간이였다. 결과적으로, 대량의 데이터를 조회하지 않으면서 Hot Data를 대상으로 조회할 때에는 Offset Pagination을 사용해도 무방하다고 보지만, Cold Data를 조회해야할 필요가 있을 때에는 Cursor Based Pagination 전략은 필수라고 본다.