대용량 트래픽 경험해보기(14/14) - Containerd를 활용한 Kubernetes 클러스터 구축
KinD를 이용해 로컬에 K8S 클러스터 구축을 진행해보았다. KinD의 경우 로컬에서 개발 및 테스트용으로 적합한 방법이다.
운영 환경에 AWS에 K8S를 구축하려한다. AWS에서 K8S를 이용하는 방법으로는 AWS EKS(Elastic Kubernetes Service), 직접 구축(Self-Managed), kOps(Kubernetes Operations) 등 여러가지 방법이 있다.
AWS EKS, kOps의 경우 간편하게 환경을 구축할 수 있는 이점이 있다. 하지만, 운영 환경에서의 K8S를 직접 구축하면서 직접적인 관리와 세부적인 내용을 확인하고자 별도 EC2 서버에서 K8S 클러스터를 구축하고자 한다.
K8S 구축 전
KinD에서는 로컬 환경에서 각 노드(마스터, 워커)가 별도 컨테이너로 있었다. 운영 환경에서 생각해보았을 때 마스터 노드와 워커 노드는 어떻게 구성해야할지에 대해 생각을 해보았을 때 아래와 같은 구조이지 않을까 생각하여 아키텍처를 설계해보았다.
Kubernetes Architecture 설계
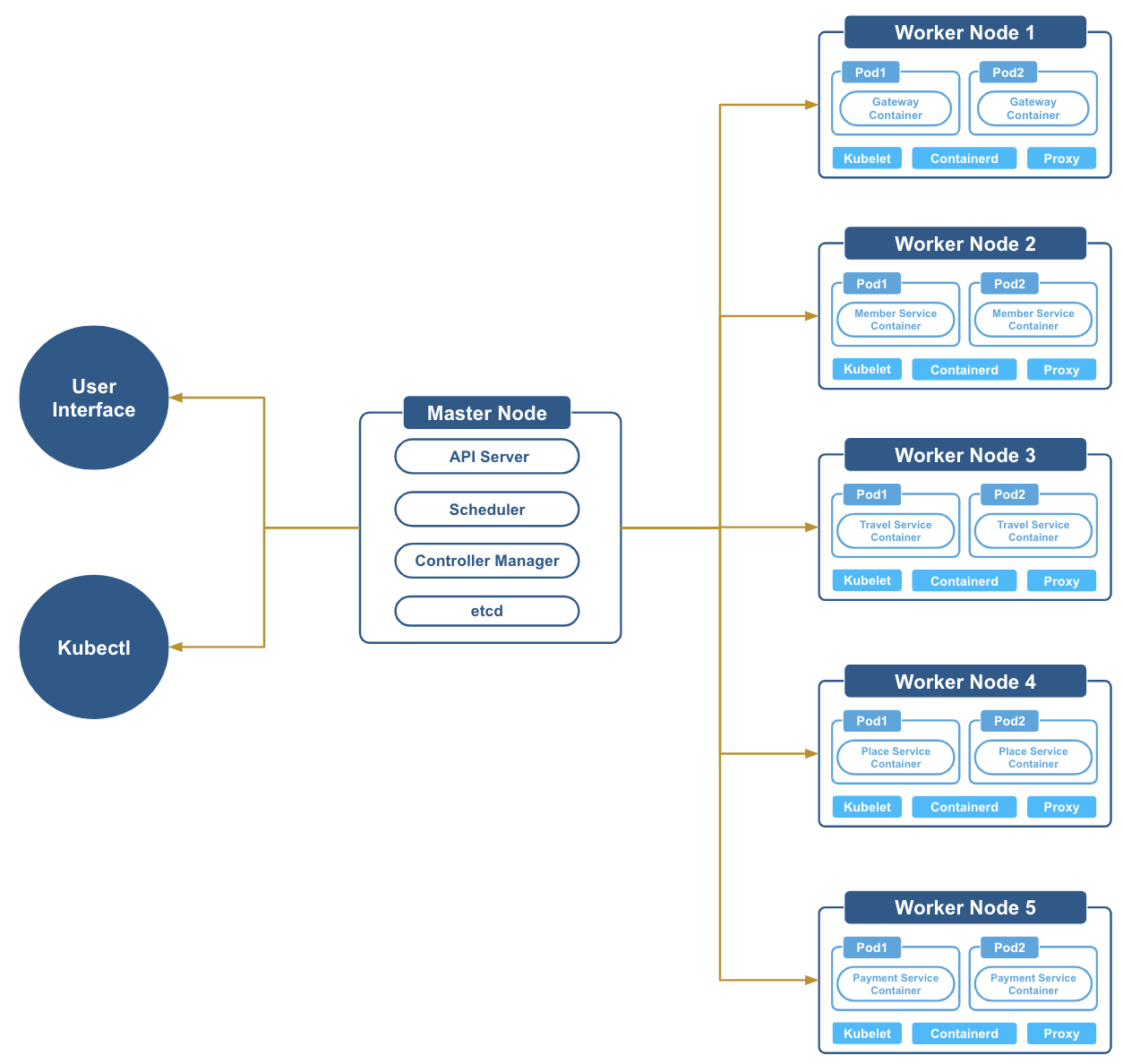
워커노드는 게이트웨이, 회원 서비스, 여행 플래너 서비스, 숙소 및 예약 서비스, 결제 서비스 순으로 구성하였다.
K8S 구축을 위한 WorkFlow 작성해보기
- 각 서비스를 Docker Repository 저장
- K8S 전제 조건 및 권장사양 체크
- 여행 플래너 및 숙소 예약 서비스 부하 테스트 트래픽 계산에 필요한 정보 계산
- 각 서비스 별 DAU, RPS, VUser, 목표 TPS
- K8S 마스터 노드 및 대시보드 설정
- 마스터 노드 및 클러스터 생성
- K8S 대시보드 설정
- 트래픽 정보를 기반으로 각 서비스의 최소 서버 사양 구하기
- 회원 서비스를 우선으로 워커 노드용 서버 생성 및 설정
- 워커노드 서버 생성시 필요한 최소 리소스 체크
- 워커노드 설정 후 마스터노드와 연동 방법 체크
- Containerd 설정 및 적용 확인
- 서버 리소스 기준으로 LimitRange, ResourceQuota 설정
- 회원 서비스용 DB 서버 생성 및 테스트 데이터 추가
- 간단한 부하를 통해 HPA(Horizontal Pod Autoscaler) 테스트
- 회원 외 서비스에 대한 워커 노드용 서버 생성 및 설정
서비스별 트래픽관련 정보 계산
종합 여행 플랫폼에서 여행 플래너인 메인 서비스 대비 숙박과 같은 부가 서비스에서 예약 및 결제에 대한 사용자 비율 20 ~ 50%로 진행해보고자 한다.
목표 수치
- Response Time : 500ms
- TPS : Active User / Response Time
- Active User는 VUser로 계산
DAU(Daily Active Users)
- 서비스 전체에 대한 DAU: 25,000
- 여행 플래너 서비스에 대한 DAU: 12,500 ~ 20,000
- 숙박 및 예약(결제포함)에 대한 DAU: 5000 ~ 12,500
RPS(Request Per Seconds)
여행 플래너
- 로그인부터 여행 정보 관련 및 여행 계획까지의 1일 평균 요청 수 : 약 12.5회 (기존 시나리오 1 ~ 3의 평균)
- 1일 총 접속수(DAU * 1명당 1일 평균 접속수)
- 최소 : 12,500 * 12.5 = 156,250
- 최대 : 20,000 * 12.5 = 250,000
- RPS (1일 총 접속수 / 86400)
- 최소 : 1.8 (156,250 / 86400)
- 최대 : 2.9 (250,000 / 86400)
피크 집중률 및 안전계수 적용 RPS (1일 총 접속수 * 2 * 2) : 11.6
숙소 및 예약
- 숙소 검색 및 예약 1일 평균 요청 수 : 약 20회
- 숙소 예약 및 결제의 경우 한 번의 요청 이후에 재발생 가능성이 너무 낮아 수치에 포함시키기 너무 큰 갭을 보이기에 평균 수치에서 제외)
- 1일 총 접속수(DAU * 1명당 1일 평균 접속수)
- 최소 : 5,000 * 20 = 100,000
- 최대 : 12,500 * 20 = 250,000
- 1일 최소 및 최대 RPS (1일 총 접속수 / 86400)
- 최소 : 1.2 (100,000 / 86400)
- 최대 : 2.9 (250,000 / 86400)
피크 집중률 및 안전계수 적용 RPS (1일 총 접속수 * 2 * 2) : 11.6
VUser
여행 플래너
- 한 번의 시나리오를 완료하는데 걸리는 시간 : 약 8분
- 최소 RPS에 대한 VUser: 약 70 ((1.8 * 480) / 12.5)
- 최대 RPS에 대한 VUser: 약 450 ((11.6 * 480) / 12.5)
숙소 및 예약
- 한 번의 시나리오를 완료하는데 걸리는 시간 : 약 30분
- 최소 RPS에 대한 VUser: 약 110 ((1.2 * 1800) / 20)
- 최대 RPS에 대한 VUser: 약 1050 ((11.6 * 1800) / 20)
부하 테스트 필요 정보 정리
| 구분 | RPS(안전계수 포함) | VUser | 목표 TPS |
|---|---|---|---|
| 여행 플래너 | 1.8 ~ 11.6 | 70 ~ 450 | 140 ~ 900 |
| 숙박 조회 및 예약 | 1.2 ~ 11.6 | 110 ~ 1050 | 220 ~ 2100 |
K8S 전제 조건
- 1개의 Master Node, 1개 이상의 Worker Node가 필요하며, 필요에 따라 Worker Node가 필요할 수 있다.
- Master Node 권장사항:
최소 2코어 이상의 CPU, 2Gib 이상의 메모리 - Worker Node 권장사항:
최소 1코어 이상의 CPU, 1Gib 이상의 메모리- 실행할 Pod 수에 따라 리소스는 달라질 수 있다.
- 마스터 노드와 워커 노드는 운영체제 및 컨테이너 저장을 위해 어느정도의 스토리지 용량 필요.
20Gib로 우선 시작
- 클러스터 내 모든 노드는 서로 통신할 수 있어야 하며, 필요한 포트가 열려 있어야 한다.
- Kubernetes는 노드에서
스왑 메모리 비활성화권장한다.- 메모리 관리 일관성: Kubernetes는 노드의 물리적 메모리만을 기준으로 리소스를 할당하며, 스왑 메모리를 포함하지 않는다. 스왑이 활성화된 경우 메모리 부족 상황을 정확히 감지하지 못할 수 있다.
- 안정성: 스왑 사용으로 인해 컨테이너의 메모리 사용량이 증가하면, Kubernetes가 이를 적절히 관리하지 못할 수 있으며, 이는 전체 클러스터의 안정성에 부정적인 영향을 미칠 수 있다.
서비스별 최소 서버 사양
마스터 노드
마스터 노드의 경우 K8S 최소 사양을 기준으로 가장 저렴한 인스턴스 유형을 선정했다.
| 인스턴스 유형 | vCPU | Memory | Network | 비용 |
|---|---|---|---|---|
| t3a.medium | 2 | 4Gb | 최대 5Gb | 시간당 0.0468USD |
게이트웨이
- 예상 실행 Pod 수: 기본 1개 / 최대 2개
Gateway는 Redis에서 토큰 관리 및 인증처리오 서비스를 모두 요청/응답 해준다. Gateway의 경우 Reactive 아키텍처로 Non-blocking I/O로 동시성의 수준을 고려했을 때 CPU 코어 수가 중요한 요소이고, Client는 요청은 모두 Gateway로 요청하기에 어느정도 서버 스팩이 필요하다고 한다.
게이트웨이 서버의 경우 처음 설정하는 부분이며, 위 서비스에 대해서 최소한의 서버 스팩을 고려했을 때 여행플래너 서버와 동일한 스팩으로 설정 한 후에 테스트 과정에서 Scale Up을 고려해보고자 한다.
| 인스턴스 유형 | vCPU | Memory | Network | 비용 |
|---|---|---|---|---|
| c5a.xlarge | 4 | 8Gb | 최대 10Gib | 시간당 0.172USD |
회원 서비스
- 예상 실행 Pod 수: 기본 1개 / 최대 2개
회원 서비스의 경우 구현한 기능은 로그인과 리프레시 토큰이 만료되어 재발급 과정에서의 회원 조회 기능만 현재 유지중이며, Pod 확장 및 배포를 고려했을 때 서버 스팩은 아래와 같이 설정했다.
| 인스턴스 유형 | vCPU | Memory | Network | 비용 |
|---|---|---|---|---|
| c5a.xlarge | 4 | 8Gb | 최대 10Gib | 시간당 0.172USD |
여행 플래너 서비스
- 예상 실행 Pod 수: 기본 1개 / 최대 3개
이전 부하테스트 과정에서 여행 플래너만의 서비스를 기준으로 계산한 RPS, VUser, TPS와 비교했을 때 30% 가까이 차이가난다.
| 구분 | 기존 시나리오에 대한 평균 | 여행 플래너 시나리오 평균 |
|---|---|---|
| RPS | 14.5 | 12.5 |
| VUser | 580 | 450 |
| TPS | 1160 | 900 |
이전 여행 플래너 서비스의 서버 스팩은 아래와 같다.
| 인스턴스 유형 | vCPU | Memory | Network | 비용 |
|---|---|---|---|---|
| c5a.2xlarge | 8(4코어) | 15Gb | High | 시간당 0.454USD |
기존 서버를 기준으로 운영했을 때 CPU가 60% 가까이 사용률을 보이고 있으며 부하는 발생하지 않았다. 약 30%의 트래픽이 감소한 상태이며 기존 서버 스팩에 안정적인 사용률을 보이기에 여행 플래너 서버 스팩은 유지한다.
숙소 조회 및 예약 서비스
- 예상 실행 Pod 수: 기본 1개 / 최대 2개
숙소 조회 및 예약에 대한 트래픽 정보(RPS, VUser, TPS)를 보면서 이전 여행 플래너 시나리오2와 비교했을 때 비슷한 트래픽이지만 API와 비즈니스 로직에 대한 차이가 있다. 비교적 적은 API와 간략한 로직으로 구성된 숙소 조회 및 및 예약 서비스에 대해서 1단계 낮은 서버로 구성했다.
| 인스턴스 유형 | vCPU | Memory | Network | 비용 |
|---|---|---|---|---|
| c5a.xlarge | 4(2코어) | 8Gb | 최대 10Gib | 시간당 0.172USD |
결제 서비스
- 예상 실행 Pod 수: 기본 1개 / 최대 2개
결제 서비스의 경우 결제와 생성, 승인, 조회에 대한 기능이 있으며, 결제 생성 및 승인 처리는 반드시 예약이 발생해야하는 로직으로 설계하였다.
한명의 사용자를 기준으로 숙소 예약에 의한 정상적인 결제 처리는 하루 1회로 볼 수 있으나 한 주를 기준으로 0.15회, 한달을 기준으로 0.03회다. 해당 수치의 경우 TPS 측정에는 너무 적은 수치로 생각되어 위 트래픽 정보에 반영하지 않았으며, 이에 Pod 확장 및 배포를 고려했을 때 회원 서비스와 동일한 서버 스팩이 적절할 수 있다고 생각했다.
| 인스턴스 유형 | vCPU | Memory | Network | 비용 |
|---|---|---|---|---|
| c5a.xlarge | 4 | 8Gb | 최대 10Gib | 시간당 0.172USD |
Kubernetes 구축 사전준비
1
2
sudo yum update -y
sudo yum install -y git curl wget vim jq
Containerd 설치 및 설정
Containerd 설치
1
sudo yum install -y containerd

Containerd 설정
아래 명령어를 통해 config.toml 파일에 기본 옵션 설정을 활성화 해준다.
- 주석 되어있는 옵션들을 주석 해제하여 활성화해준다.
1
sudo containerd config default | sudo tee /etc/containerd/config.toml
1
sudo vim /etc/containerd/config.toml
SystemdCgroup 활성화
1
2
3
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
...
SystemdCgroup = true # **false -> true로 설정**
- Sandbox Image 설정
- Containerd를 사용할 때, Pod를 생성하면 자동으로
registry.k8s.io/pause컨테이너가 실행된다. 이 컨테이너는 Sandbox 컨테이너 또는 Pause 컨테이너라고 불리며, Kubernetes의 Pod 네트워크 및 리소스를 유지하는 핵심 역할을 한다. - K8S에 적합한 SandBox Image 설정
1
2
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.k8s.io/pause:3.8"
Containerd 재시작 및 활성화
1
2
3
sudo systemctl restart containerd
sudo systemctl enable containerd
sudo systemctl status containerd
스왑 비활성화
메모리 관리 일관성과 안정성을 위해 스왑 메모리를 비활성화 한다.
1
2
sudo swapoff -a
sudo sed -i '/swap/d' /etc/fstab
네트워크 시스템 설정
IP 포워딩 및 브리지 설정
클러스터 내의 네트워크 통신을 활성화하고, 파드(pod) 간 및 파드와 외부 네트워크 간의 통신을 지원하기 위한 설정이다.
K8s 클러스터에서의 네트워크 통신은 일반적으로 CNI(Container Network Interface) 플러그인을 통해 이루어지며, IP 포워딩과 브리지 설정은 네트워크 트래픽이 클러스터 내에서 적절하게 라우팅되고 전달되도록 보장하기위해 설정한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# iproute 설치
sudo yum install -y iproute
sudo yum install -y iproute-tc
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
# 즉시 설정(재부팅하면 재설정 해줘야함)
sudo sysctl --system
- iproute / iproute-tc: Kubernetes가 네트워크 관련 작업을 처리를 위해 필요할 수 있다.
- modprobe br_netfilter: Linux 커널 모듈을 로드하는 명령어로, 브리지 네트워크 필터링을 활성화하기 위함이며, Kubernetes와 같은 컨테이너화된 시스템에서 네트워크 패킷이 적절하게 필터링되도록 하기 위해 필요한 설정이다.
- net.bridge.bridge-nf-call-iptables: Linux 시스템에서 브리지 네트워크가 iptables와 통신할 수 있도록 설정하는 파일이며, 브리지 네트워크 사용을 위해 활성화 필요.
- net.ipv4.ip_forward: Linux 시스템에서 IP 포워딩을 활성화하거나 비활성화하는 커널 파라미터이다. 이 파라미터는 네트워크 트래픽을 라우팅하는 데 사용한다.
Kubelet, Kubeadm, Kubectl 설치
설치 이슈
Kubelet, Kubeadm, Kubectl 설치를 위해서 google cloud에서 yum의 k8s 저장소를 통해서 설치한다.
https://kubernetes.io/ko/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
공식 사이트에서 저장소 설정 및 설치 과정을 진행하면서 계속해서 저장소를 찾을 수 없다고 한다.
- x86_64의 경우 baseUrl 변경 필요.
Kubelet, Kubeadm, Kubectl 설치 과정에서 아래와 같이 Repository를 찾을 수 없다는 이슈가 발생했다.
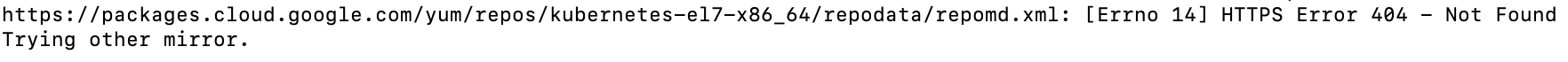
공식 문서를 찾아보니, 2024년 3월 4일부터 패키지 저장소가 중단되었다.

해결 방법
https://kubernetes.io/blog/2023/08/15/pkgs-k8s-io-introduction/#how-to-migrate-rpm
중단관련 내용에서 조금 더 내려가다보면 yum repository에 대한 새 저장소를 확인할 수 있으며 baseUrl과 gpgkey를 아래와 같이 변경한다.
1
2
3
4
5
6
7
8
9
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
1
2
3
# kubelet, kubeadm, kubectl 설치
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
1
2
3
4
# 버전 확인
kubectl version --client
kubelet --version
kubeadm version
1
2
# kubelet 서비스 활성화
sudo systemctl enable --now kubelet
만약, 정상적으로 설치가 안되면 아래 명령어를 통해 yum 캐시 정리를 진행 후 재설치하면 된다.
1
2
sudo yum clean all
sudo yum makecache
기타 이슈
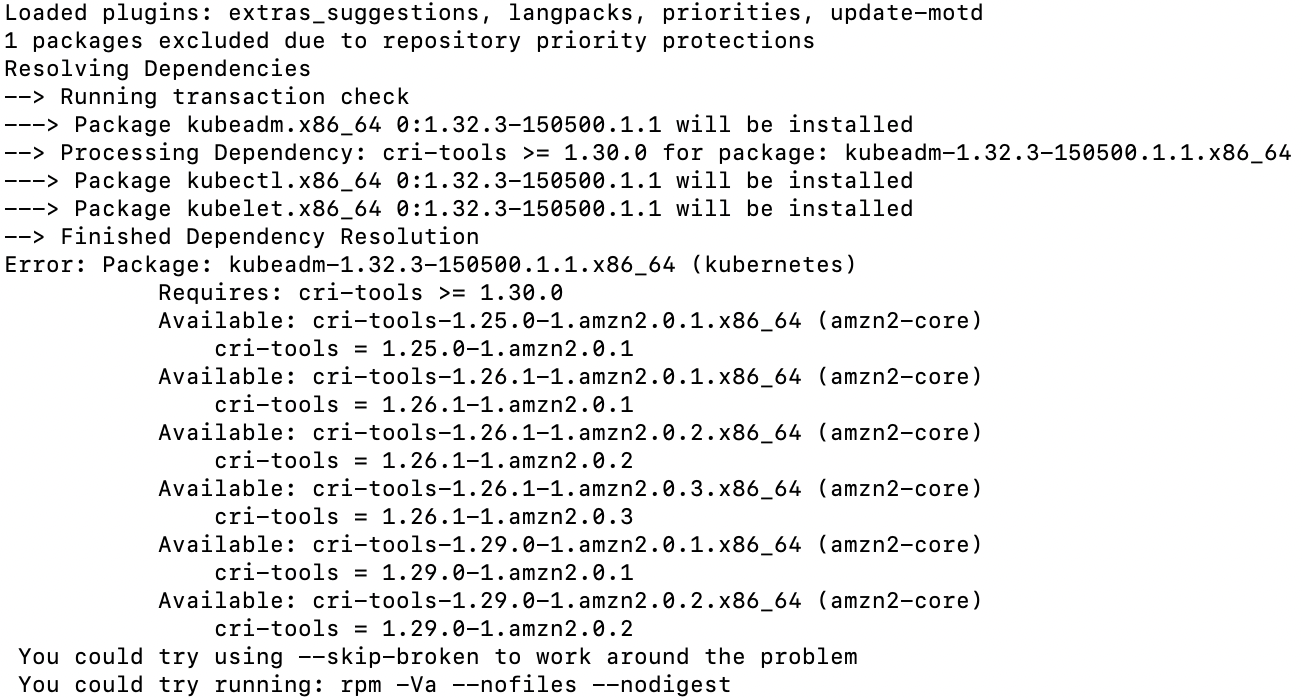
원래 목적은 v1.32를 설치하려했으나 아래와 같이 cli-tools 버전 이슈가 발생했다. 현재 사용중인 OS는 Amazon Linux 2이며 해당 OS에서는 v1.29인 cli-tools를 제공한다.

Kubernetes 클러스터 구축
마스터 노드 초기화
1
2
3
4
5
6
sudo kubeadm init \
--apiserver-advertise-address={Internal IP} \
--apiserver-cert-extra-sans={Elastic Public IP} \
--control-plane-endpoint={Elastic Public IP 혹은 DNS}:6443 \
--pod-network-cidr=192.168.0.0/16 \
--cri-socket=unix:///run/containerd/containerd.sock
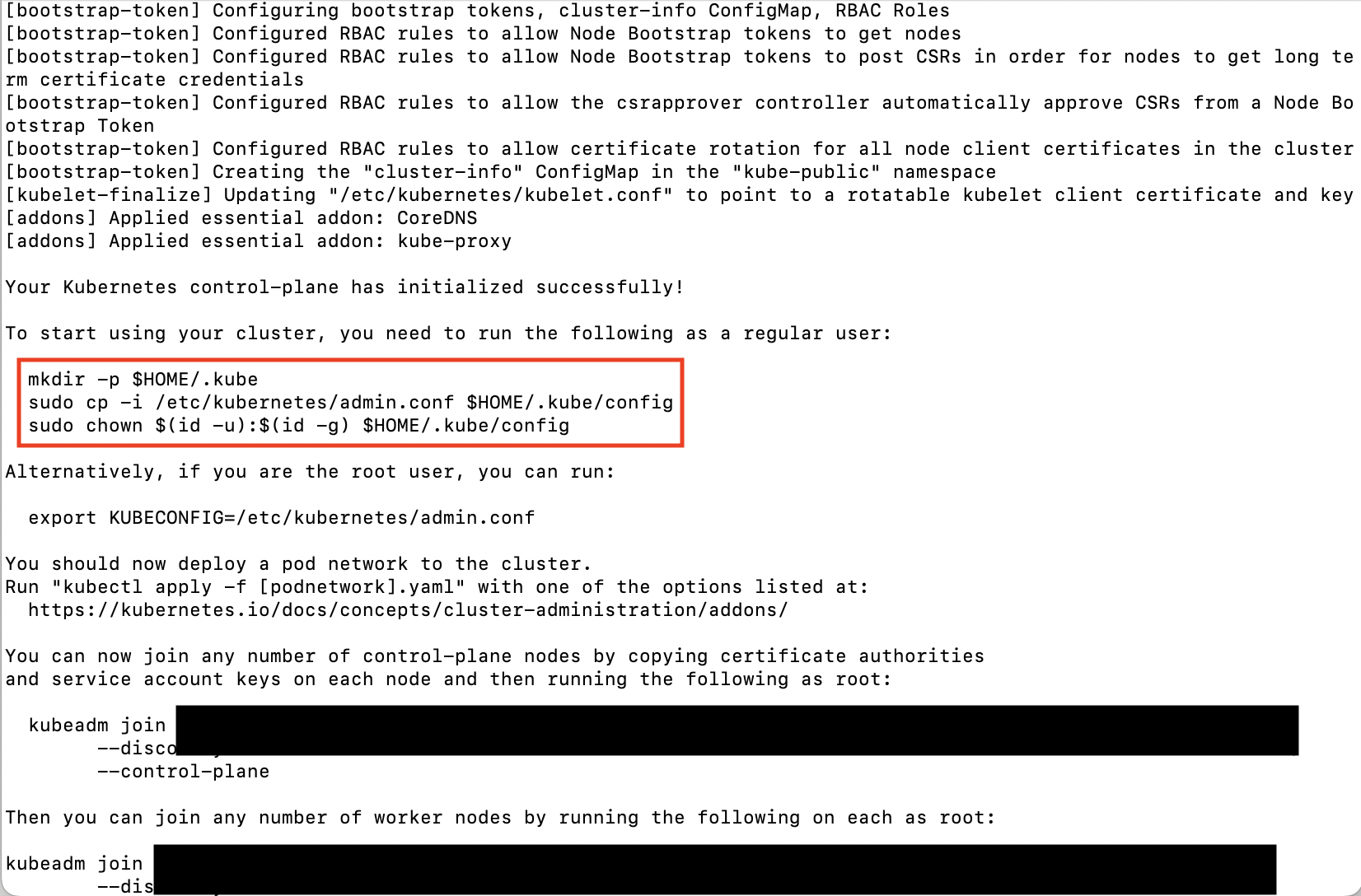
관리자 계정에서 Kubectl 설정
config 파일 확인(/etc/kubernetes)

- kubeadm-config의 경우 kubeadmin init에 사용하는 설정 파일로 나머지 config 파일은 kubeadm 초기화 후 자동 생성
클러스터 초기화 이후 로그 확인시 아래와 같은 설정을 해야한다.
1
2
3
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config # 소유자 변경
클러스터 확인
1
kubectl cluster-info

네트워크 플러그인 설치
Kubernetes 클러스터에서 Pod 간 통신을 위해 CNI(Container Network Interface)를 설정해야 합니다. 여기서는 Calico를 사용한다.
1
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
1
kubectl get pods --all-namespaces # 전체 네임스페이스 Pod 조회

클러스터 Reset을 해야할 경우
1
sudo kubeadm reset
위 명령어를 통해 클러스터를 리셋할 수 있지만, 리셋 이후 다시 클러스터를 생성하고 네트워크 플러그인 설정 후에 아래와 같은 오류가 발생할 수 있다.
couldn’t get current server API group list: … tls: failed to vertify certificate: x509
인증서 관련 오류로 네트워크 플러그인 Calico 파드 일부가 pending 상태가 계속 유지되고 결국 running 되지 않는 상황에서 강제로 삭제 후 재 생성을 반복하다가 클러스터를 초기화하면서 발생할 수 있다.
Reset 이후 처리사항
1
kubeadm certs check-expiration
- 조회된 인증서들이
|MISSING|으로 표기되는지 확인
1
sudo rm -rf $HOME/.kube
- reset 이후 다시 init 할 경우 위 경로의 디렉토리를 생성하게 되는데 생성 전 삭제한다.
- 삭제하지 않을 경우 overrite를 할 수 있는데 overrite를 할 경우 오류가 해결되지 않을 수 있다.
워크노드 추가를 위한 확인
마스터 노드에서 워커 노드를 클러스터에 추가하기 위한 join 명령을 확인합니다.
1
kubeadm token create --print-join-command
출력 예시
kubeadm join xxx.xxx.xxx.xxx:6443 — token … sha256:…
K8S 대시보드 설정
K8S 기본 정책상 마스터 노드는 Taint 설정이 되어있어, 파드가 스케줄링되지 않도록 되어있다. 별도 K8S 대시보드용 워커노드를 생성하여 설정해도되나, 마스터 노드에 설정하기로 했다.
1
kubectl describe node <마스터노드 호스트명> | grep -i taint # 마스터 노드 Taint 확인
출력 결과: Taints: node-role.kubernetes.io/control-plane:NoSchedule
NoSchedule로 설정되어있으면 이 노드에는 Pod를 배포할 수 없다.
마스터 노드 Taint 제거
1
kubectl taint nodes <마스터노드 호스트명> node-role.kubernetes.io/control-plane:NoSchedule-
- 마지막
-를 추가하면 제거된다.
K8S 대시보드 리소스 설정
1
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
1
2
# 대시보드 서비스 조회
kubectl get svc -n kubernetes-dashboard
외부 접근을 위한 Node Port 설정
K8S 대시보드 서비스를 조회하면 TYPE이 ClusterIP로 확인될 것이다. 아래 명령어를 통해 서비스 리소스를 수정할 수 있으며 아래와 같이 NodePort 설정을 해준다.
1
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: v1
kind: Service
...
spec:
...
ports:
- nodePort: 31443 # 추가
port: 443
protocol: TCP
targetPort: 8443
type: NodePort # ClusterIP -> NodePort로 변경
...
로그인을 하려면 토큰 생성이 필요하며, 서비스 계정 및 Cluster 바인딩 후 토큰을 생성하여 로그인하면된다.
서비스 계정 생성 및 Cluster 바인딩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# k8s-account-binding.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
1
2
# Service Account 리소스 설정
kubectl apply -f k8s-account-binding.yaml
1
kubectl -n kubernetes-dashboard create token admin-user
Metrics Server
K8S 클러스터의 리소스 사용에 대한 데이터 집계를 위해 Metric Server를 설정한다. Command Line Interface에서 보편적으로 리소스 사용률을 확인 할 수 있는 명령어로 top이 있다. K8S 클러스터의 리소스 사용률을 볼 수 있는 명령어는 다르며 Metrics Server를 설정해야 사용할 수 있다.
1
kubectl top <nodes/pods/svc 등>
Metrics Server 설정
1
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
metrics server 설정 이후 Pod 로그를 확인하면 아래와 같은 내용을 확인할 수 있다.
Readiness probe failed: Get “https://192.168.165.14:10250/readyz”: dial tcp 192.168.165.14:10250: connect: connection refused
위 경우 TLS 인증 과정을 거치며 발생하는 것으로 저는 SSL 설정을 하지 않아 TLS 인증을 하지 않는 방법으로 설정했다.
1
2
# metrics-server deployment 수정
kubectl edit deployment metrics-server -n kube-system
1
2
3
4
5
spec:
containers:
- args
- --kubelet-insecure-tls # 추가
...
1
kubectl rollout restart deployment metrics-server -n kube-system
설정 이후 아래 명령어를 통해 재배포를 하면 파드 상태가 정상인 것을 확인할 수 있으며, 대시보드 혹은 kubectl top 명령어를 통해 아래와 같이 CPU, Memory 사용률을 확인할 수 있다.
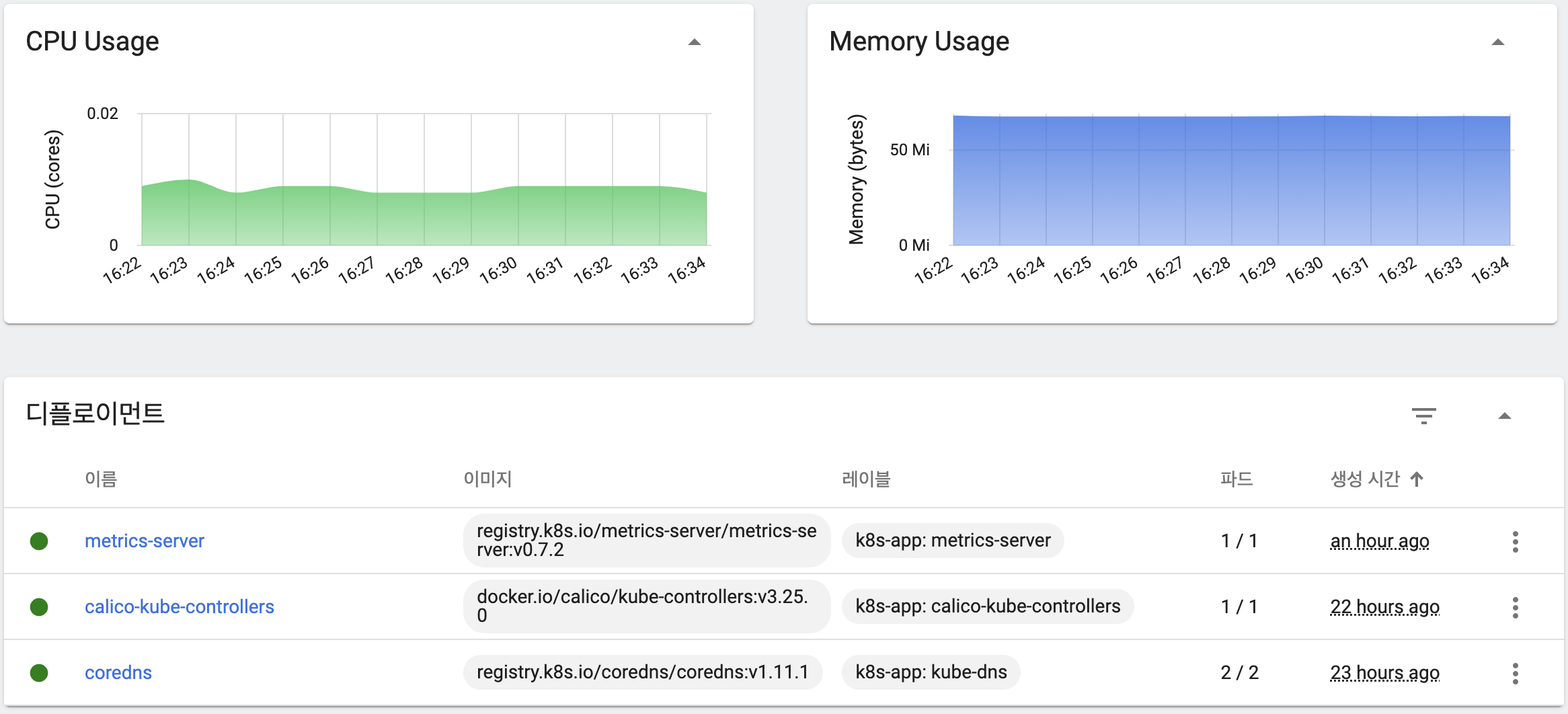
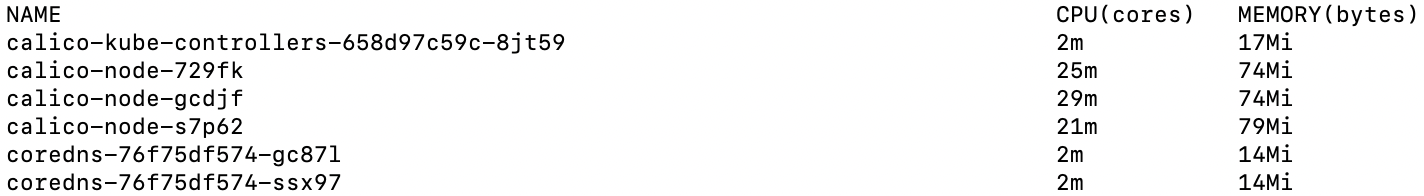
워커노드 환경 구축
워커노드 사전 설정
워커 노드 또한 마스터 노드와 일부 동일한 설정이 있다. 동일한 설정의 경우 순서는 아래와 같으며 상세 설정은 생략하겠습니다.
Containerd 설정(SystemdCgroup 활성화) → IP 포워딩 및 브리지 설정 → kubelet, kubeadm, kubectl 설치
Kubeadm 마스터 노드 Join
마스터 노드 Join 전 마스터 노드 EC2 보안 그룹 6443 포트 인바운드 규칙을 확인한다.
포트 충돌 이슈
kubeadm join 과정에서 10250 포트 사용 충돌할 수 있다.
error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR Port-10250]: Port 10250 is in use
1
sudo lsof -i :10250 # -> kubelet의 포트 사용으로 보이고 있다.
위 설정의 경우 기존 systemctl에 설정한 kubelet이며 해당 서비스를 중단한다.
1
sudo systemctl stop kubelet # kubelet 중단 후 kubeadm join 재실행
마스터 노드 Join
1
2
# 마스터 노드
kubeadm token create --print-join-command
출력 예시
kubeadm join xxx.xxx.xxx.xxx:6443 — token … sha256:…
1
2
# 워커노드 노드
sudo kubeadm join xxx.xxx.xxx.xxx:6443 — token … sha256:…
마스터 노드에서 워커노드 연동 확인
1
2
3
# 마스터 노드에서 실행
kubectl get nodes

Ready 상태가 아닌 경우 kubelet 로그 확인
1
sudo journalctl -u kubelet -f
노드상태가 Ready의 경우 워커노드의 kubelet 서비스를 다시 활성화해준다.
1
2
sudo systemctl restart kubelet
sudo systemctl enable --now kubelet
트러블 슈팅1
추가한 워커노드의 상태가 NotReady 상태가 유지되어 확인해보니 아래 오류 발생했다.
err=”failed to validate nodeIP: node IP: \”xxx.xxx.xxx.xxx\” not found in the host’s network interfaces” node=“hostname”
해결방법
kubeadm-config 설정에서 NodeCluster구성에서 Node IP를 Elastic IP의 Public IP를 이용으로 인해 발생하였다. 노드 간 통신은 인스턴스 내부 네트워크를 통해 이루어지기에 초기 마스터 노드에서 클러스터 생성(kubeadm init)시에 apiserver-advertise-address를 Private IP(내부 IP)로 설정해야한다.

트러블 슈팅2
워커노드에서 kubectl을 통해 노드, 서비스, 파드 등 조회하려하면 아래와 같이 오류가 발생하여 불가능할 것이다.
couldn’t get current server API group list: Get “http://localhost:8080/api?timeout=32s”: dial tcp 127.0.0.1:8080: connect: connection refused
여러 내용을 찾아보니 워커노드의 kubectl이 올바른 K8S API 서버에 연결하지 못해서, 로컬호스트(127.0.0.1)로 요청을 보내면서 발생하게된다.
해결방법
마스터 노드의 admin.conf를 워커 노드로 복사하여 kubadm config를 설정해준다.
1
2
# 워커 노드
mkdir -p $HOME/.kube
1
2
# 마스터 노드
sudo scp /etc/kubernetes/admin.conf 계정이름@정보:/home/계정이름/.kube/config
완료되면 kubectl을 이용해 Pod, Node, Service 확인할 수 있다.
외부 서비스 연결
AWS RDS, Redis를 연결 방법에 대해서 찾아보았을 때 K8S에서는 외부 서비스 연결에 ExternalName 타입의 서비스를 이용해야한다.
Service 리소스 설정
1
2
3
4
5
6
7
8
9
10
# rds-mysql-service.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql-external-service
namespace: <네임스페이스>
spec:
type: ExternalName
externalName: <RDS-ENDPOINT> # 포트는 제외
Secret 리소스 설정
Secret 리소스의 데이터는 Base64로 입력해야한다. 이에 커멘드에서 아래 명령어를 통해 DB명, USERNAME, PASSWORD의 Base64
1
echo -n '<RDS DB PASSWORD>' | base64
1
2
3
4
5
6
7
8
9
10
11
12
# rds-mysql-service.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysql-credentials-secret
namespace: <네임스페이스>
type: Opaque
data:
database: <DB Name base64>
username: <DB Username Base64>
password: <DB Password Base64>
Deployment 리소스 설정
중요하지 않은 설정은 ConfigMap으로 설정했으며 주요 정보는 Secret으로 설정했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-deployment
namespace: <네임스페이스>
spec:
containers:
- name: app-container
...
env:
- name: DB_HOSTNAME
value: "mysql-external-service" # ExternalName 타입 서비스의 이름
- name: DB_NAME
valueFrom:
secretKeyRef:
name: mysql-credentials-secret # Secret의 이름
key: database # Secret data의 database key
- name: DB_PORT
valueFrom:
configMapKeyRef:
name: config-map
key: DB_PORT
- name: DB_USER
valueFrom:
secretKeyRef:
name: mysql-credentials-secret # Secret의 이름
key: username # Secret data의 username key
- name: DB_PWD
valueFrom:
secretKeyRef:
name: mysql-credentials-secret # Secret의 이름
key: password # Secret data의 password key
서비스 임시 테스트
NodePort 설정 후 해당 포트를 보안그룹 인바인드 규칙에 넣어준다. 이후 http:/{IP 혹은 DNS}:{NodePort}/actuator/health 로 접속하면 아래 결과를 확인할 수 있으며, AWS RDS 서비스 연결 정상화로 DB Connection Health 상태가 정상적인 것을 확인할 수 있다.

트러블 슈팅
외부 서비스 연결은 위한 서비스 생성 과정에서 서비스 리소스가 생성되었고 대시보드에서 정상 운영 상태를 확인하였다. 그런데 Deployment 리소스 설정 후에 DB Connection이 계속 실패하는 것을 확인했다.
서비스 리소스에서 정상적으로 RDS DNS를 요청하는지 확인했다.
1
kubectl run -it --rm --image=busybox --namespace=<네임스페이스> --restart=Never curl-test -- /bin/sh
설정한 네임스페이스로 임시 파드를 생성한 후 테스트해보았다.
1
nslookup <서비스명>
;; connection timed out; no servers could be reached
원인 확인
타임아웃으로 인한 연결 실패의 경우 보안그룹이라고 생각하여 RDS 보안그룹 인바운드/아웃바운드 체크하였지만, 해결되지 않았다. 서비스 메타데이터 이름 특수문자일까(?)라는 생각, 임시 테스트용 mysql-client Pod를 생성하여 테스트해보았지만 실패!!
여러 정보를 찾고 ChatGPT에 계속해서 질문하다보니 CoreDNS 캐시 이슈가 있을 수 있다고 한다. CoreDNS는 정상적으로 Running 상태임에도 캐시 문제가 발생할 수 있다고 하여 초기화해야한다고 한다.
해결 방안
CoreDNS 캐시 초기화: CoreDNS 캐시가 문제가 될 경우, CoreDNS Pod를 삭제하여 캐시를 초기화할 수 있다.
1
kubectl delete pod -n kube-system -l k8s-app=kube-dns
- 위 명령어를 통해 CoreDNS 삭제로 캐시 초기화 이후 자동 실행된다.
- 캐시 초기화 및 정상 처리까지 주기가 있으며 기본 설정(30초) 이후 다시 확인할 수 있다.
- 재시작(restart)명령어는 CoreDNS 캐시가 초기화되지 않는다.
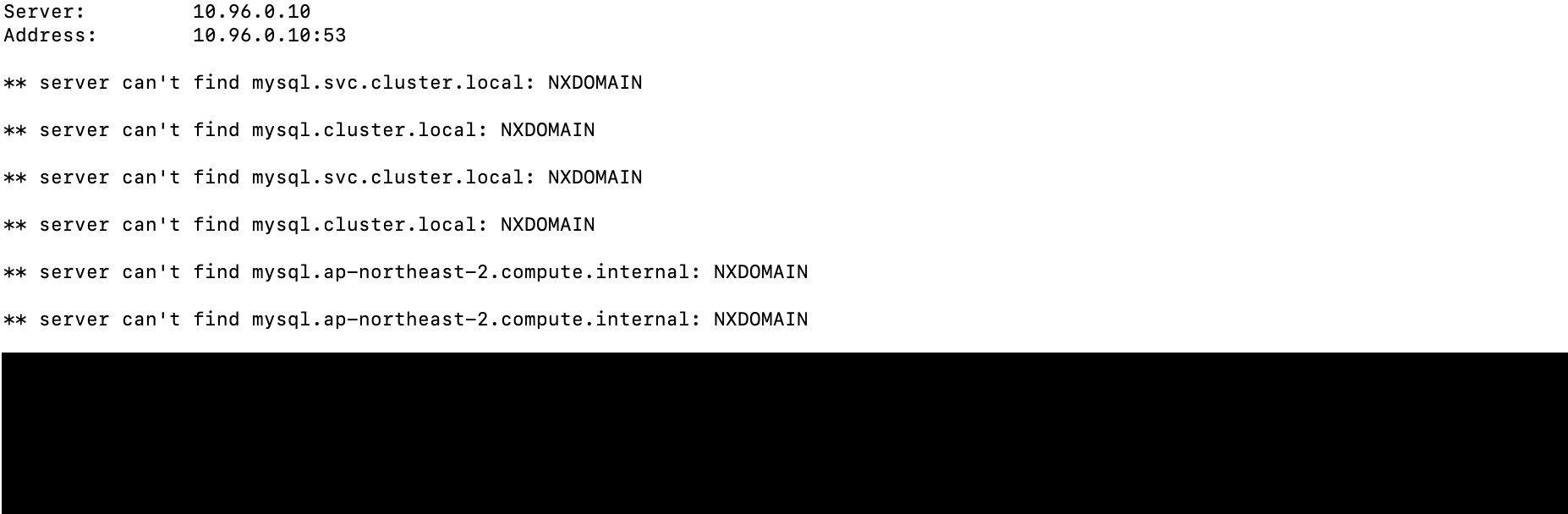
CoreDNS 캐시 초기화 후에 nslookup을 통해 아래와 같이 Cluster DNS를 체크하면 연결되는 DNS를 확인할 수 있다.
트러블 슈팅 과정에서
위 이슈를 처리하면서 두가지 사항을 정리하면 아래와 같다.
중복 서비스명 이슈
처음에 외부 서비스 리소스 설정과 관련해서 서로 다른 네임스페이스에서 동일한 서비스명을 사용했다. 네임스페이스가 다르니 문제가 없을 것이라 생각했지만, 서비스가 정상적으로 올라가지 않는 이슈가 있었다. Pod간 통신을 위한 Cluster DNS로 <서비스명>.<네임스페이스>.svc.cluster.local 이용했지만 해결되지 않아 서비스명을 변경해야 했다.
CoreDNS 캐시 초기화 주기 확인 및 변경
문제가 있을 때마다 CoreDNS 캐시를 초기화를 진행하면서 초기화 되기까지 기다리는 시간이 좀 답답하여 초기화 주기를 확인할 필요가 있었다.
CoreDNS ConfigMap에서 설정을 변경할 수 있다.
1
kubectl edit configmap coredns -n kube-system
1
2
3
4
5
6
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30 # 캐시된 레코드 유효 기간을 의미하며 설정된 시간(초)이후 갱신
}
- 위 설정을 통해 갱신 시간을 줄 일 수 있으나 너무 짧은 시간으로 줄이면 성능에 영향이 발생한다.
Strimzi Operator를 이용한 Kafka 클러스터 구축
Strimzi Operator란?
Strimzi Operator는 K8S 환경에서 카프카 설치와 운영을 단순화한다. 쿠버네티스 crd를 이용하여 주키퍼, 카프카 클러스터를 설치할 수 있고 토픽 등도 crd로 관리가 가능하며, 각 컴퍼넌트를 crd로 배포하고 관리한다.
- Cluster Operator: kafaka cluster, zookeeper cluster 등 컴퍼넌트를 배포하고 관리한다.
- Entity Operator: user operator와 topic operator를 관리한다.
- Topic Operator: topic생성, 삭제 등 topic관리한다.
- User Operator: kafaka 유저 관리한다.
- Zookeeper Cluster : 카프카의 메타데이터 관리 및 브로커의 정상 상태 점검한다.
- Kafka Cluster : 카프카 클러스터(여러 대 브로커 구성) 구성한다.
Kraft Mode
Strimzi Operator를 이용하면서 추가적으로 알아볼 내용으로 Kraft Mode가 있다.
기존 Kafka 클러스터의 메타데이터 관리를 위해서 Zookeeper를 이용했었다. 그러나, v0.32 버전 이후부터 Zookeeper 없이 메타데이터를 관리할 수 있는 Kraft Mode를 지원하기 시작했다.
Kraft Mode는 Kafka 자체에서 Raft 합의 프로토콜을 활용하여 메타데이터를 관리하는 방식으로 Zookeeper를 사용하지 않으면서 시스템의 복잡도가 감소하였고, 메타데이터 관리를 내부적으로 처리함으로써, 안정성과 확장성이 증가한다.
버전 체크
현재 설치된 Kafka 버전에 맞는 Strimzi Kafka Operator 버전을 확인할 필요가 있다.
Strimzi Kafka Operator 설정
1
kubectl apply -f 'https://strimzi.io/install/latest?namespace=<네임스페이스>' -n <네임스페이스>
1
kubectl get pods -n <네임스페이스>
KafkaNodePool 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: node-pool
namespace: <네임스페이스>
labels:
strimzi.io/cluster: <Kafka 리소스명>
spec:
replicas: 3
roles:
- controller
- broker
storage:
type: persistent-claim
size: 3Gi
deleteClaim: false
class: <스토리지 클래스명>
- persistent-claim
- 각 노드의 스토리지 볼륨을 동적으로 할당하고, 이 스토리지의 지속성을 유지를 위한 설정이다.
- Kafka는 데이터 저장소로 디스크를 사용하며, 이 디스크를
persistent-claim방식으로 설정하여 Pod가 재시작되거나 클러스터가 변경되더라도 데이터가 손실되지 않도록 한다.
- deleteClaim
true: PVC가 삭제되면 해당 PVC와 연결된 PV도 함께 삭제됩니다.false: PVC가 삭제되더라도 PV는 삭제되지 않으며, PV는 수동으로 관리한다.
Storage Class 리소스 설정
NFS 혹은 별도 스토리지 서비스를 이용하지 않고 있어 로컬 스토리지를 리소스로 설정하여 진행하였다.
1
2
3
4
5
6
7
8
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: <스토리지 클래스명>
namespace: <네임스페이스>
provisioner: kubernetes.io/no-provisioner # 수동 관리를 위한 설정
volumeBindingMode: WaitForFirstConsumer
reclaimPolicy: Retain
- provisioner
- kubernetes.io/<프로비저너>: PV를 사전에 생성할 필요 없이, PVC만 생성하여 필요한 스토리지를 자동으로 할당받을 수 있다.
- 프로비저너: aws-ebs, gce-pd, azure-disk, rbd 등
kubernetes.io/no-provisioner: 동적 프로비저닝을 사용하지 않고, 사용자가 수동으로 Persistent Volume을 관리하고자 할 때 사용하는 설정이다.
- kubernetes.io/<프로비저너>: PV를 사전에 생성할 필요 없이, PVC만 생성하여 필요한 스토리지를 자동으로 할당받을 수 있다.
- volumeBindingMode
Immediate: PVC가 생성될 때, Kubernetes는 즉시 PV를 찾아서 PVC와 바인딩한다.WaitForFirstConsumer: PVC가 생성되더라도, Kubernetes는 PVC가 실제로 사용될 때까지 PV와 바인딩하지 않는다.
- reclaimPolicy
Retain: PVC가 삭제되더라도 PV는 삭제되지 않고 보존된다. 수동으로 관리되어야하며, 다른 PVC가 이를 사용할 수 있도록 재사용할 수 있다.Delete: PVC가 삭제될 때 PV도 삭제된다.
Persistence Volume 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
apiVersion: v1
kind: PersistentVolume
metadata:
name: kafka-local-pv-1
spec:
capacity:
storage: 3Gi # KafkaNodePool의 Storage Size와 동일하게 설정
volumeMode: Filesystem
accessModes:
- ReadWriteOnce # 한 개의 노드에서만 접근 가능
persistentVolumeReclaimPolicy: Retain # PVC와 연결이 끊어졌을 때 데이터 보존(Retain)
storageClassName: <스토리지 클래스명>
local:
path: /mnt/disks/data # 해당 노드의 실제 디렉토리 경로
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- <워커 노드 호스트명>
KafkaNodePool의 Replicas 만큼 PersistenceVolume도 생성해야 PVC 리소스들이 정상적으로 Binding된다.
Kafka 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: <kafka 리소스명>
namespace: <네임스페이스>
annotations:
strimzi.io/node-pools: enabled # Kafka Node Pool 활성화
strimzi.io/kraft: enabled # Kraft Mode 활성화
spec:
kafka:
version: 3.9.0
metadataVersion: 3.9-IV0
replicas: 2
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: false
config:
auto.create.topics.enable: "false"
offsets.topic.replication.factor: 2
transaction.state.log.replication.factor: 2
transaction.state.log.min.isr: 1
default.replication.factor: 2
min.insync.replicas: 1
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
entityOperator:
topicOperator: {}
userOperator: {}
kafkaExporter:
groupRegex: ".*"
topicRegex: ".*"
metadataVersion의 경우 아래 링크에서 확인
Kafka UI 리소스 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-ui-deployment
namespace: tp-kafka
spec:
replicas: 1
selector:
matchLabels:
app: kafka-ui-app
template:
metadata:
labels:
app: kafka-ui-app
spec:
containers:
- name: kafka-ui-container
image: provectuslabs/kafka-ui:latest
ports:
- containerPort: 8080
env:
- name: DYNAMIC_CONFIG_ENABLED
value: "true"
- name: KAFKA_CLUSTERS_0_NAME
value: "<클러스터명>"
- name:
- name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
value: "<Bootstrap 서비스 리소스명>:9093"
부트스트랩 서비스 리소스의 경우 서비스 조회를 하면 아래와 같이 확인이 가능하다. Strimzi Kafka Operator를 사용하는 경우, Kafka 리소스를 생성하면 내부/외부 서비스가 자동으로 생성된다.

Kafka KRaft 모드 : Kafka 3.3+ 버전부터 Zookeeper 없이 KRaft 모드를 지원하며, Strimzi Operator는 기본적으로 Zookeeper를 사용하지만, 직접
Kafka리소스를 수정하여 KRaft 모드를 사용할 수 있다.
외부접속을 위해 Kafka UI 서비스 리소스를 생성 한후 노트 포트를 설정
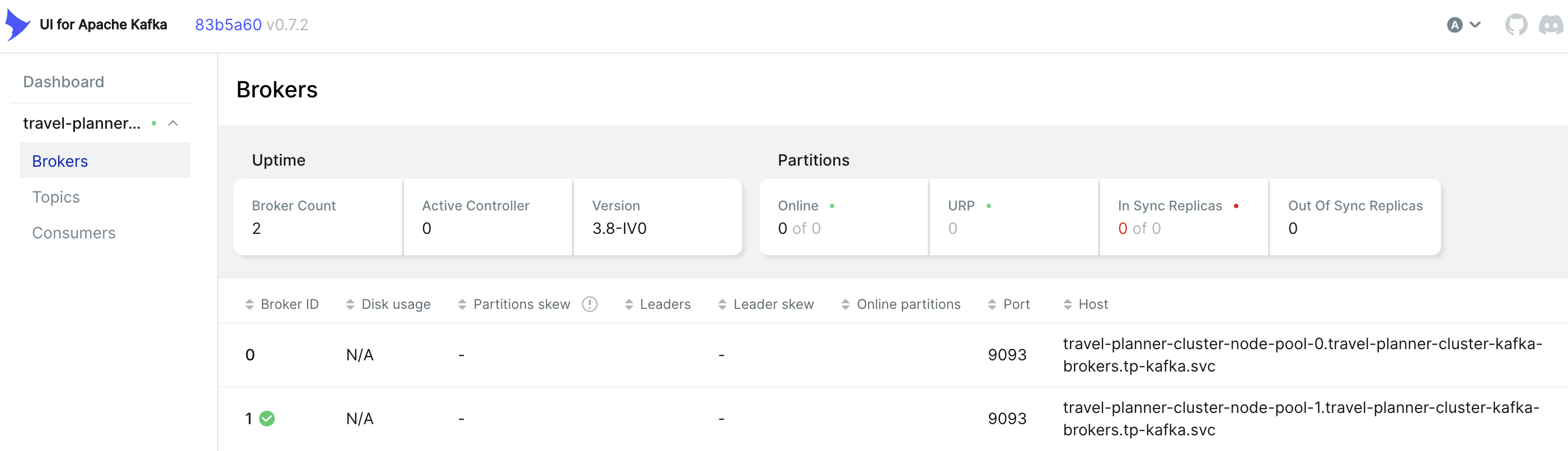
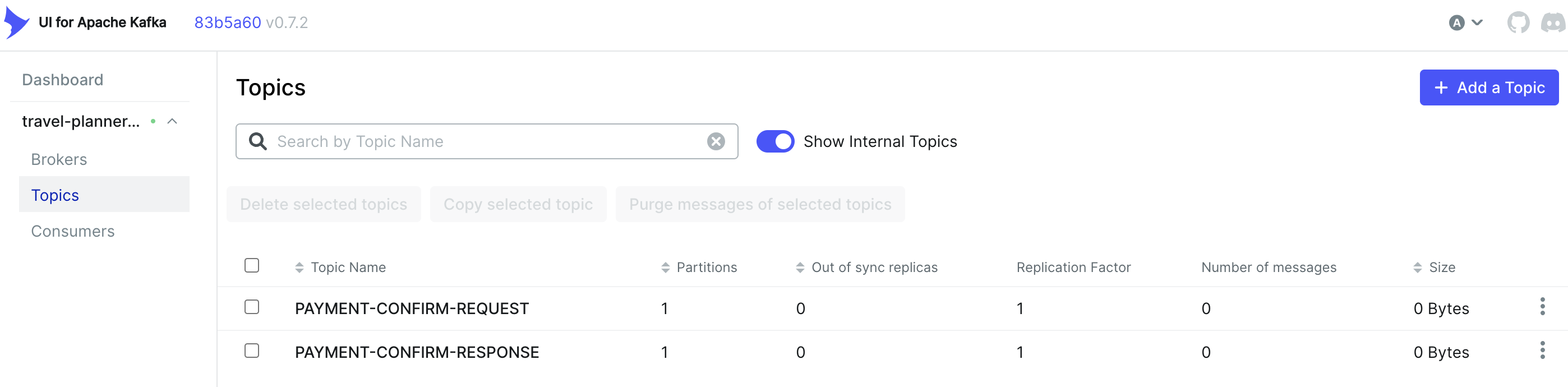
CNI 트러블 슈팅
기존 외부 서비스 연결에 대해서 트러블 슈팅 처리 이후 외부 서비스 및 Kafka 클러스터 연동에 대해서 설정 테스트를 진행했으나 주기적으로 끊기는 현상이 발생했다.
K8S에는 네트워크 통신을 위해 CNI를 이용하게 되는데, 사용한 CNI는 Calico이다. 설정에 놓친 부분이 있을까 하여, 여러 사이트 및 공식 문서를 보았다.
IP In IP 설정
Calico는 기본 네트워크 캡슐화로 IP-In-IP를 지원한다. 그러나, AWS에서는 기본으로 지원하지 않으며 노드간 통신을 위해서 AWS 보안그룹에 사용자 지정 프로토콜을 설정해줘야한다.
- 유형: 사용자 지정 프로토콜
- 프로토콜: 4 (= IP-In-IP의 프로토콜 번호)
- 소스: VPC의 CIDR
각 노드는 서로 다른 서브넷일 수 있으며, 서로 다른 VPC에서도 노드간 통신을 위해 설정해야한다.
BGP(Border Gateway Protocol) Port 설정
워커노드를 추가할 때마다 Calico Node Pod가 확장된다. 이 때 로그를 확인했을 때 아래와 같은 오류가 발생했다.
calico/node is not ready: BIRD is not ready: BGP not establised with XXX
위 오류는 Calico에서 BGP Peering을 통해 노드 간의 라우팅 정보를 교환할 때 발생하는데 실패했을 때 발생하는 오류이다.
1
2
# Calico Node와 BGP 피어 상태를 확인
sudo calicoctl node status # STATE: up, INFO: Established이어야 정상
해결방안
BGP 피어링을 설정하려면 노드간 방화벽 설정 확인이 필요하다. 기본적으로 TCP 179이며, 모든 노드의 보안그룹에 179 포트를 열어주고 Calico Node 데몬 셋을 재시작해준다. (CNI마다 설정하는 포트가 다르므로, 확인 후 설정 필요)

포트를 설정하지 않아도 Calico Node Pod는 Running 상태이다. 그렇다고, Ready(1/1) 상태가 아니기에 반드시 정상 상태를 확인할 필요가 있다.
위 설정을 했음에도 새로운 워커노드가 추가되었을 때 생성되는 Calico Node Pod가 Running 상태가 아닌 Error 상태일 경우가 있다. 로그를 확인해보면 아래와 같은 내용을 확인할 수 있다.
Calico node Clearing out-of-date IPv4 address from this node IP=””
이 오류 메시지는 Calico가 현재 노드에서 올바른 IPv4 주소를 감지하지 못하고 있으며, 기존 IP를 제거하려고 시도하고 있음을 의미한다.
이 경우 수동으로 감지할 인터페이스를 설정해주며 Calico 데몬셋에 IP_AUTODETECTION_METHOD 환경변수를 설정해준다.
1
2
# calico가 감지하는 인터페이스 IPV4 IP 확인
calicoctl get nodes -o wide
OS에 맞는 아이피 확인 명령어를 통해 calico가 감지하는 인터페이스 IPV4 IP에 맞는 네트워크 인터페이스명을 확인한다.
예) eth0
1
kubectl set env daemonset/calico-node -n kube-system IP_AUTODETECTION_METHOD="interface=eth0"
calico 환경변수 설정 후 데몬셋을 재시작해주고 다시 워커노드를 마스터노드에 설정시키면 Calico Node Pod가 정상 상태가 되는 것을 확인할 수 있다.
Prometheus Operator를 이용한 Prometheus & Grafana 구성
Prometheus Operator는 K8S에서 쉽게 배포, 관리, 운영할 수 있도록 도와주는 도구이다. 기존 수동으로 리소스 파일을 생성하는데 발생하는 어려움에 대해서 CRD를 통해 K8S 리소스로 구성 가능하여 쉽고 편리하게 설정 가능하다.
Helm 없이도 쉽게 배포와 관리가 가능하여 아래 오픈소스를 통해서 설치할 수 있다. K8S 버전별 호환되는 버전을 확인 후 설치한다.
Source Clone
1
2
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus
모니터링 네임스페이스 및 CustomResourceDefinition 생성
1
kubectl apply --server-side -f manifests/setup
Prometheus & Grafana 리소스 배포
1
kubectl apply -f manifests
리소스 배포 이후 아래 명령어를 통해 배포된 리소스들을 확인할 수 있다.
1
kubectl get all -n monitoring
Grafana 대시보드 접속을 위한 설정
NodePort 설정
1
kubectl edit svc grafana -n monitoring
spec.ports NodePort를 설정해주며, EC2 보안그룹에 해당 포트를 열어준다.
Grafana Network Policy 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# sudo vi grafana-networkPolicy.yaml
...
spec:
egress:
- {}
ingress:
- from:
- ipBlock:
cidr: 0.0.0.0/0 # 추가
- podSelector:
matchLabels:
app.kubernetes.io/name: prometheus
...
- from에- ipBlock.cidr를 추가해주며, 전체 접근 허용을 위한 설정으로0.0.0.0/0으로 설정했다. 접근에 제한을 두려면 환경에 맞게 cidr를 설정해주면 된다.
1
kubectl apply -f grafana-networkPolicy.yaml
http://{EC2 외부 IP}:{NodePort}로 접속하면 Grafana 화면조회가 가능하다.
- 초기 접속 정보: admin/admin
Grafana 모니터링 결과
Dashboard > Default에 적절한 대시보드 선택하면 아래와 같이 리소스 사융률에 대한 정보를 확인할 수 있다.
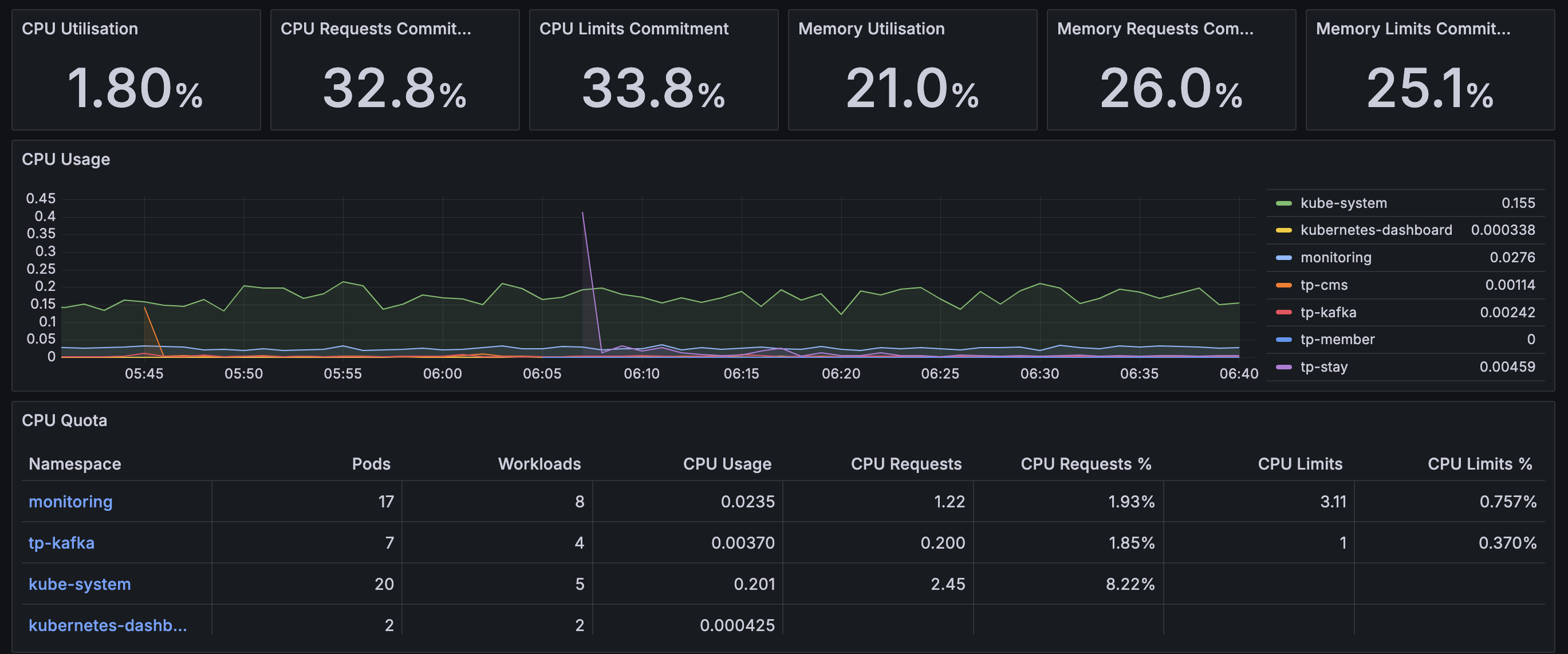
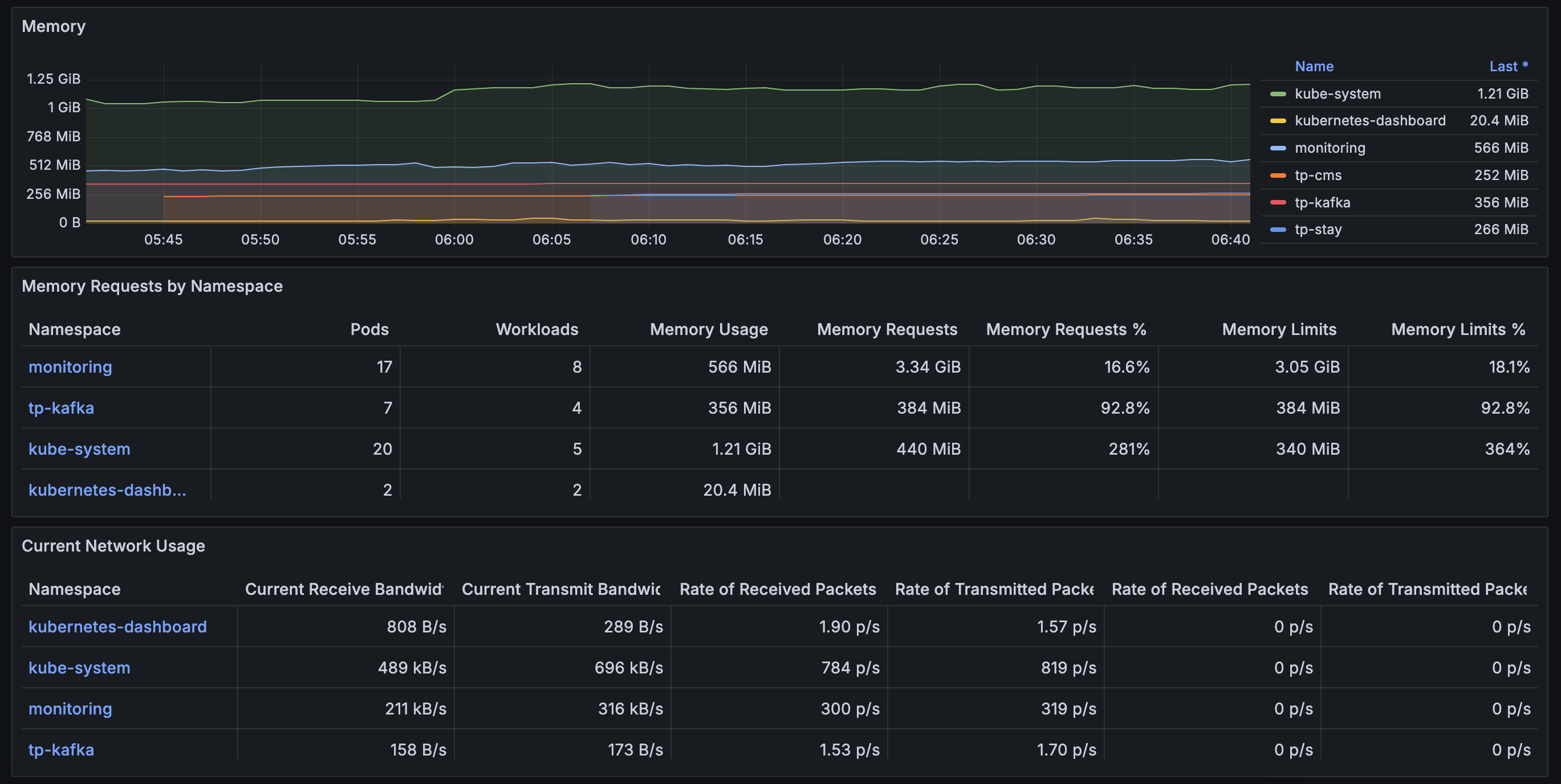
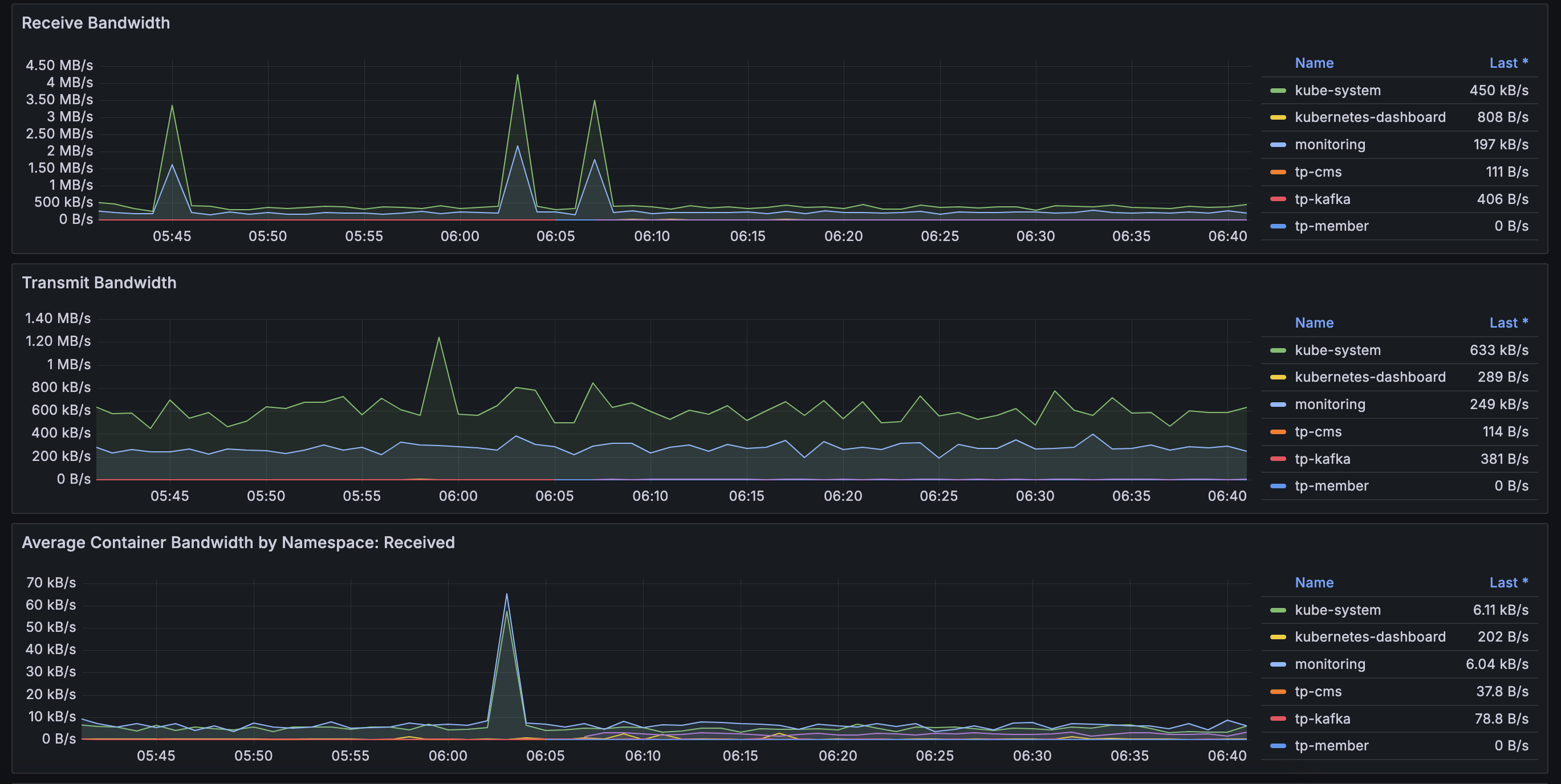
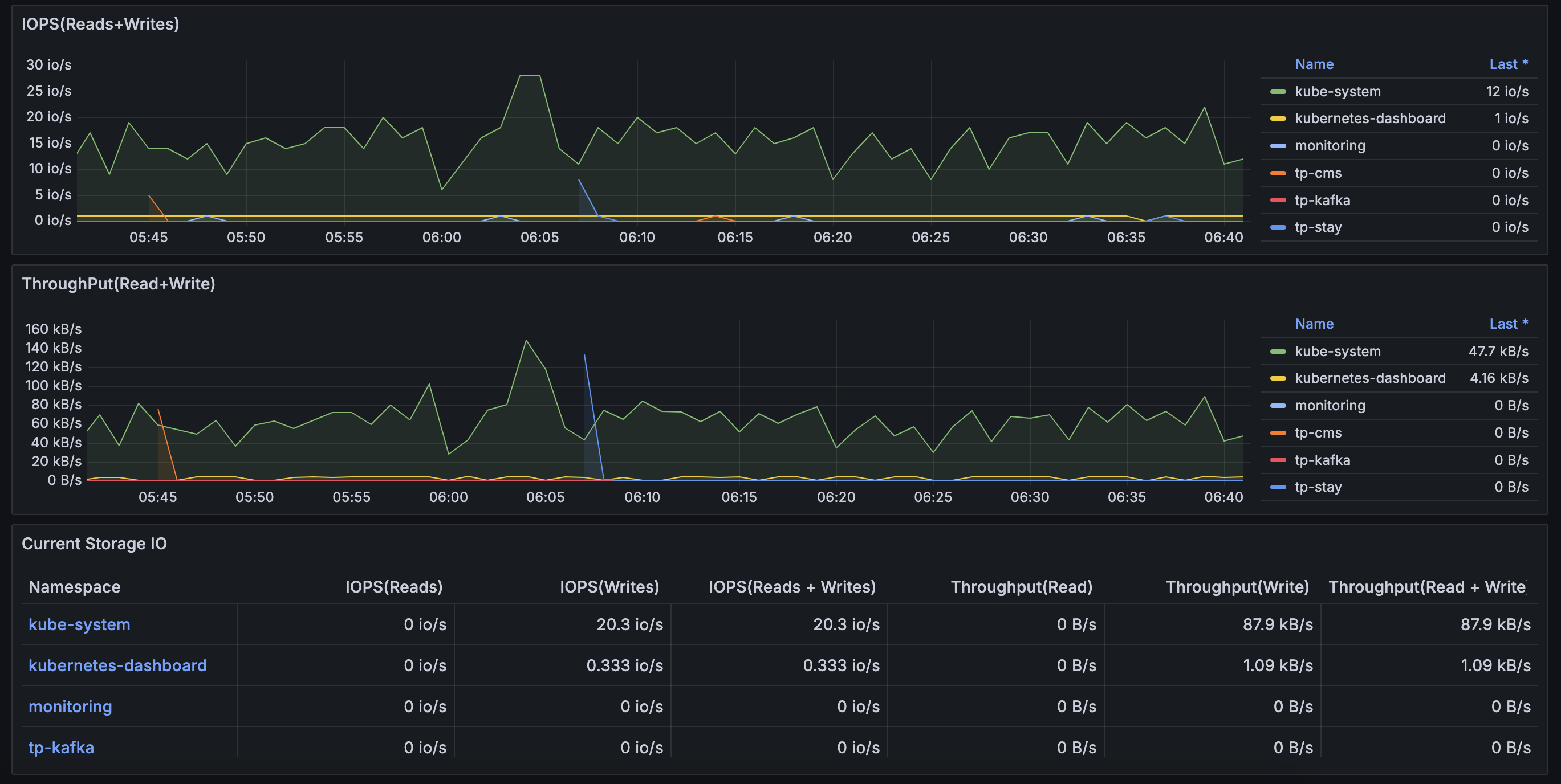
K8S 클러스터 구축 결과
API 결과
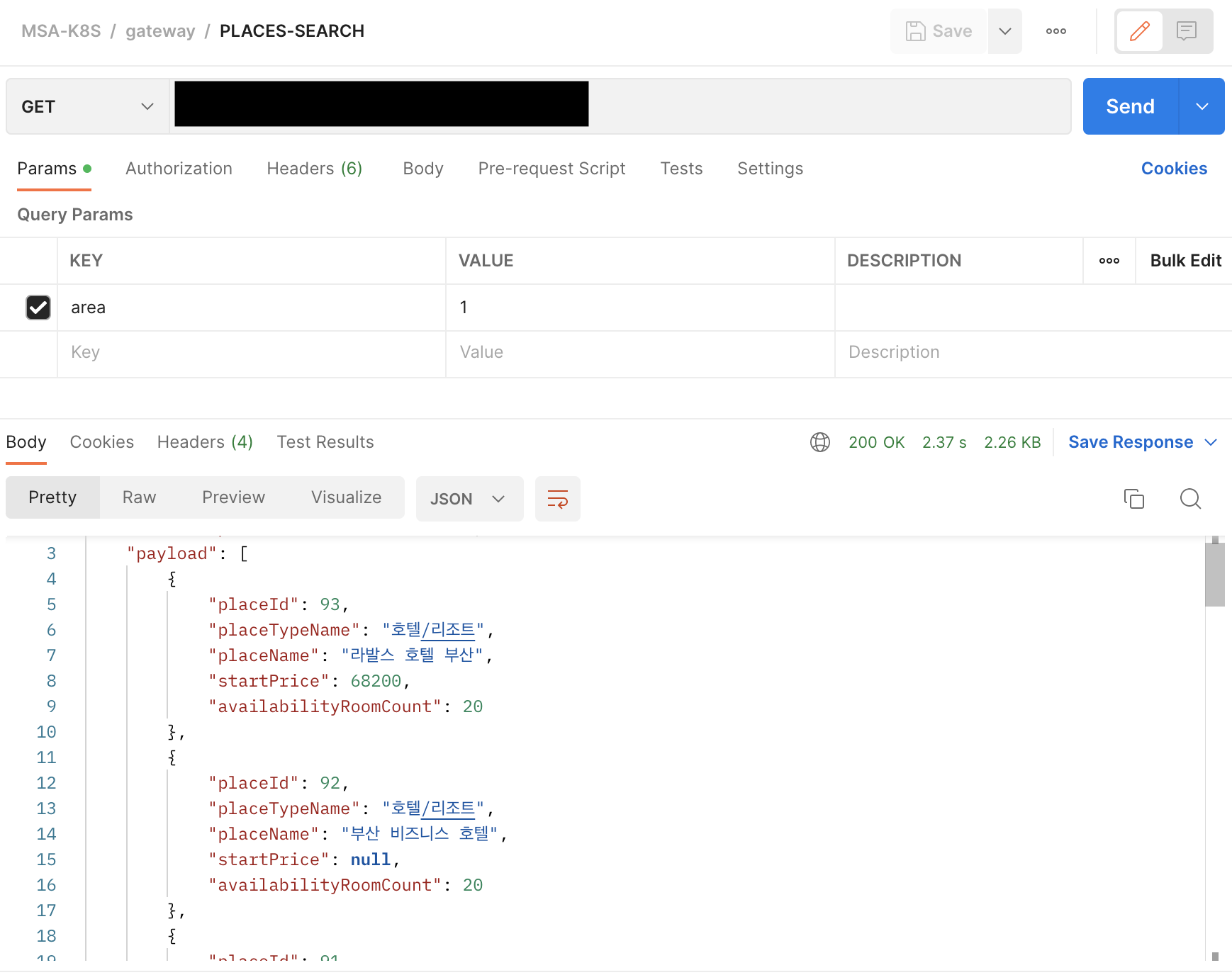
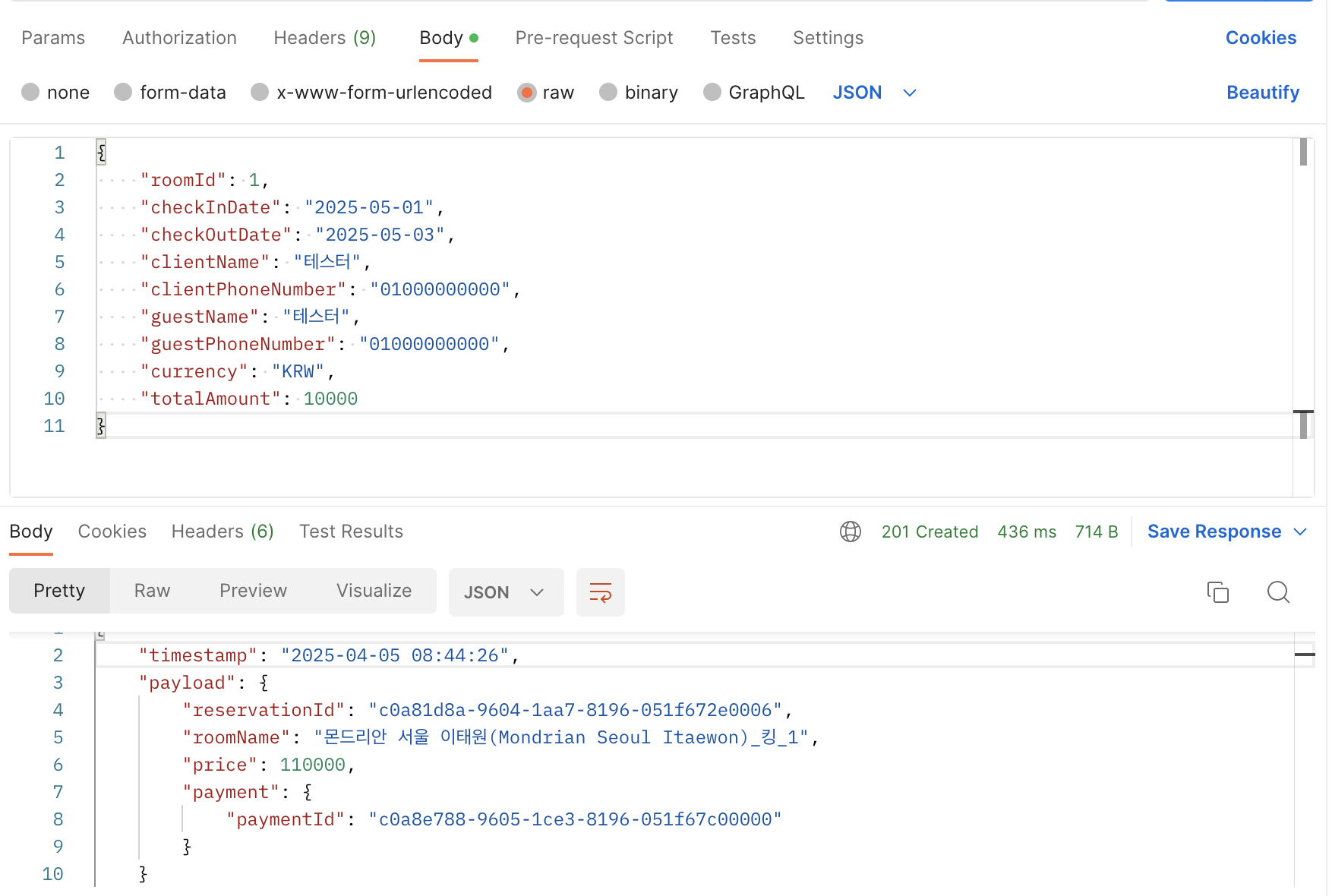
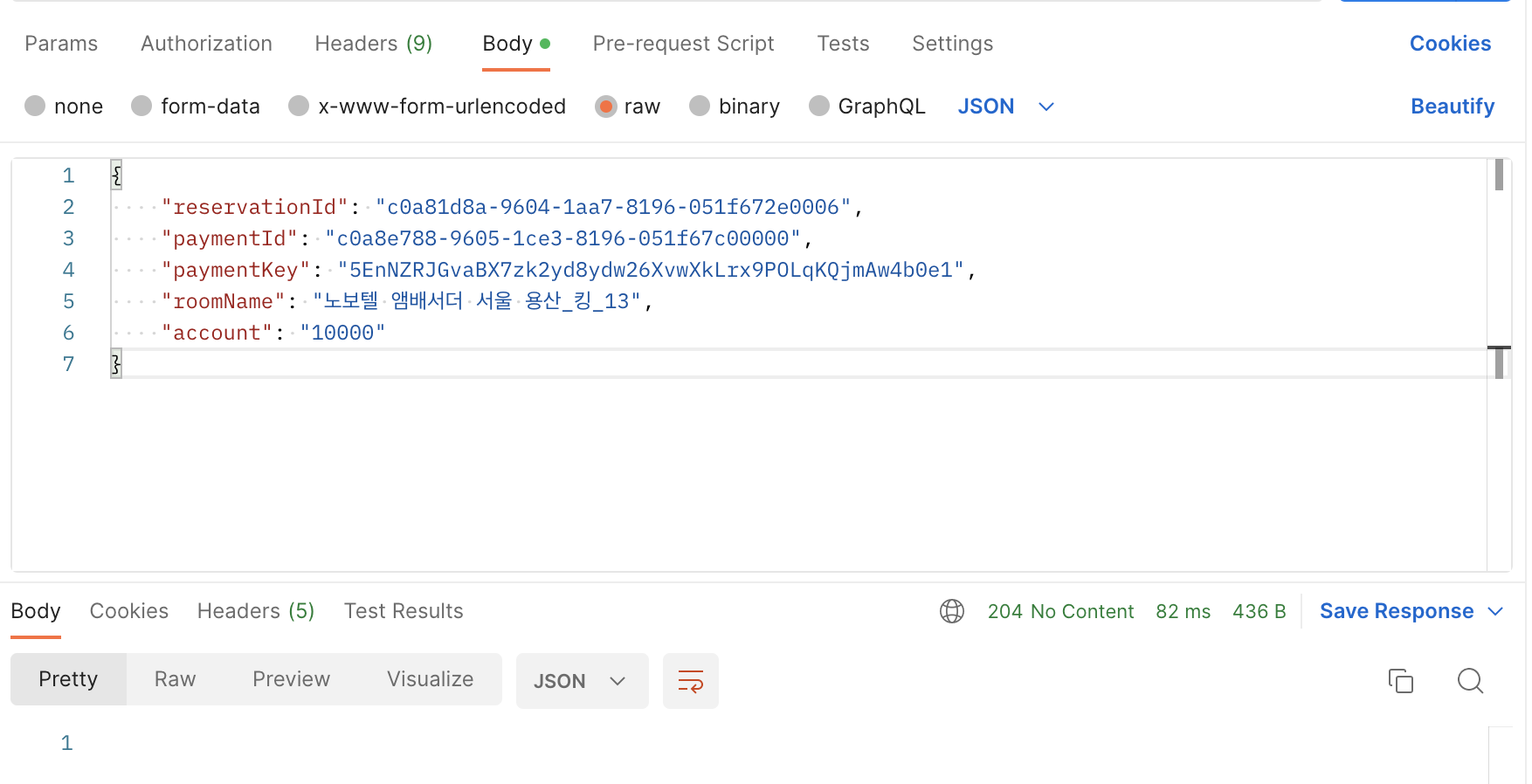
Kafka 결과