대용량 트래픽 경험해보기(12/14) - 스트레스 테스트1 (AWS Auto Scaling)
스트레스 테스트 전 설정해야할 것으로 과도한 트래픽이 발생하고 다시 낮아지게 될 경우 서버에 대한 Scale Down/Up 혹은 Scale In/Out이다.
- Scale Down/Up : 수직적 확장을 뜻하며 운영중인 서버 컴퓨팅을 축소(Down)하거나 확장(Up)을 의미한다.
- Scale In/Out : 수평적 확장을 뜻하며 운영중인 서버를 포함해 추가 서버 컴퓨팅 개수를 줄이거나(In) 늘리는 것(Out)을 의미한다.
트래픽이 낮아지면 오버 프로비저닝(Over Provisioning : 과도하게 많은 리소스를 할당한 상태)으로 불필요한 비용이 발생할 수 있고 트래픽이 높아지면 언더 프로비저닝(Under Provisioning : 부족한 리소스를 할당한 상태)으로 서비스가 중단될 수 있다.
계산된 RPS, TPS, VUser를 기반으로 현재 적절한 서버가 구축된 상태이며 과도한 트래픽 발생시 필요한 방법으로 서버 확장이다.
서버 확장에 AWS Auto Scaling, 오케스트레이션 도구(K8S, Docker Swarm 등) 2가지 방법이 있다.
구축된 인프라를 기준으로 가장 적합한 방법은 AWS Auto Scaling이다. 컨테이너 기반으로 구축했지만, 서비스 규모를 보았을 때 1개 서버에 1개의 컨테이너를 운영하기고 있고 오케스트레이션 도구를 이용해 환경을 설정하고 관리하기에 다소 복잡한 면이 있다.
하지만, 대용량 트래픽에서 독립된 서비스가 많아지면 배포의 편리성과 확장성을 위해 오케스트레이션 도구 이용은 필수적이기에 위 2가지 방법에 대해서 모두 학습하고 적용해보고자 한다.
Auto Scaling 전 서비스 분석
Auto Scaling을 설정하기 전에 테스트 과정에서 계산한 동시 접속자를 기준에 앞으로 얼마나 많은 트래픽이 발생할 수 있는지 그리고 어느 정도의 서버 사양이 필요한지 확인해볼 필요가 있다.
평균 테스트 기준
- DAU : 25,000
- Response Time : 500ms
| 구분 | RPS | VUser | TPS |
|---|---|---|---|
| 시나리오1 | 8.8 | 510 | 1020 |
| 시나리오2 | 21.6 | 1200 | 2400 |
| 시나리오3 | 13.2 | 20 | 40 |
서비스 재분석
첫 주제 분석에서 트리플 서비스를 기반으로 테스트 기준을 계산했다. 2023년 1월부터 12월까지의 평균 DAU는 25,000이며 이 기준으로 진행한 테스트는 Peak Rate와 안전계수를 포함한 것이다.
평균 DAU와 가장 높은 7월의 DAU를 비교했을 때 약 20% 정도가 차이가 나지만, 피크율 및 안전계수를 적용했기에 현재 서버 사양으로는 운영 상에는 문제가 없을 것으로 보인다.
최근에 다시 트리플 서비스를 확인해보았을 때 2024년 7월의 고유 사용자 수가 약 170만명이다. 그래서 특정 이벤트로 인해서 사용자가 증가했다는 가정으로 진행하고자 한다.
스트레스 테스트 기준
2024년 고유 사용자를 조회된 기준으로 2023년 1~9월을 기준으로 2024년 1~9월의 고유방문자 수를 비교했을 때 약 80%가 증가하였고 이 수치를 기반으로 스트레스 테스트에 필요한 지표를 계산 했을 때 아래와 같다.
- DAU : 45,000
- Response Time : 500ms
| 구분 | RPS | VUser | TPS |
|---|---|---|---|
| 시나리오1 | 15.6 | 900 | 1800 |
| 시나리오2 | 38.8 | 2100 | 4200 |
| 시나리오3 | 24 | 30 | 60 |
Auto Scaling
AWS Auto Scaling은 애플리케이션 수요에 따라 EC2 인스턴스의 수를 자동으로 조정하는 역할을 한다. EC2, ECS, RDS, DynamicDB 서비스 종류에 따라 확장(Scale Out) 혹은 축소(Scale In)를 할 수 있다.
약 80%의 동시 접속자가 증가를 기준으로 서버 확장시 기존과 동일한 스팩의 인스턴스 유형(c5a.2xlarge)을 확장 서버로 선택하고자 한다.
시작 템플릿 생성
시작 템플릿(Launch Template)의 경우 Auto Scaling이 되면 기준이 되는 인프라를 기반으로 인스턴스를 생성하기 위함이다.
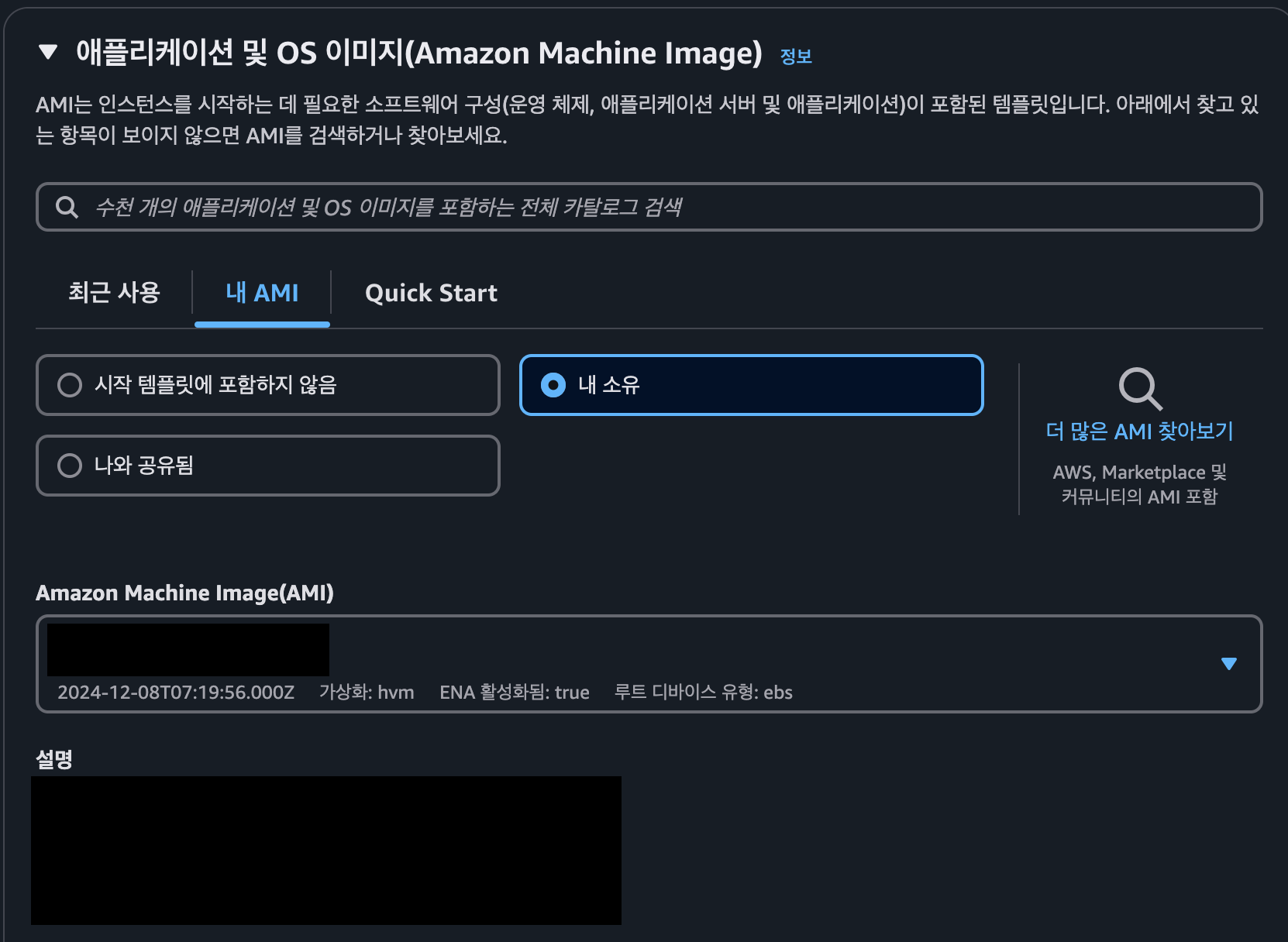
- AMI의 경우 구축한 서버를 기준으로 AMI를 생성
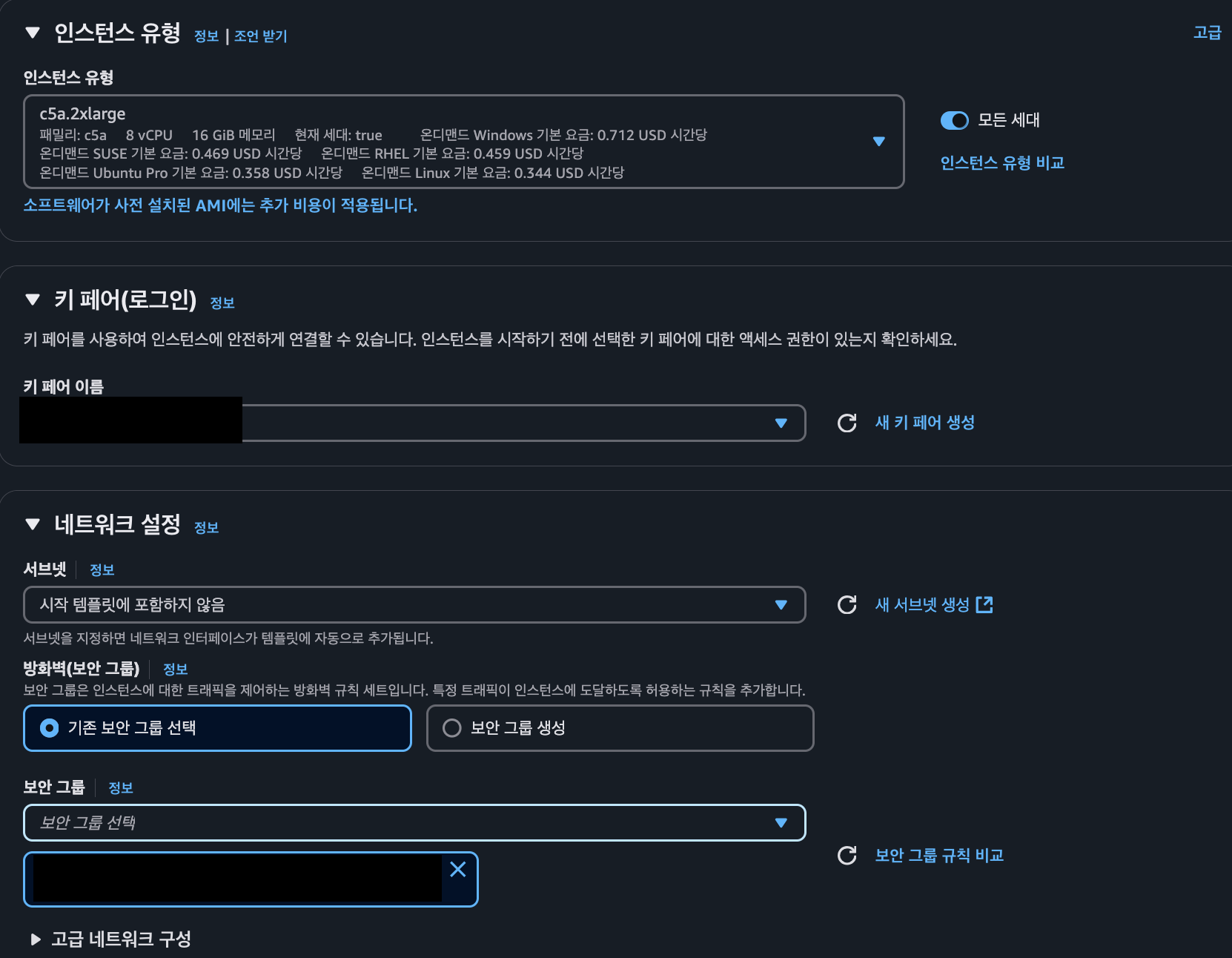
- 확장 대상 서버의 인스턴스 유형을 선택하며, 기존 서버와 동일한 키페어 및 보안 그룹을 선택
Auto Scaling Group 설정
시작 템플릿 설정
네트워크 설정
로드 벨런서 설정 및 연결

Auto Scaling 그룹 및 크기 조정
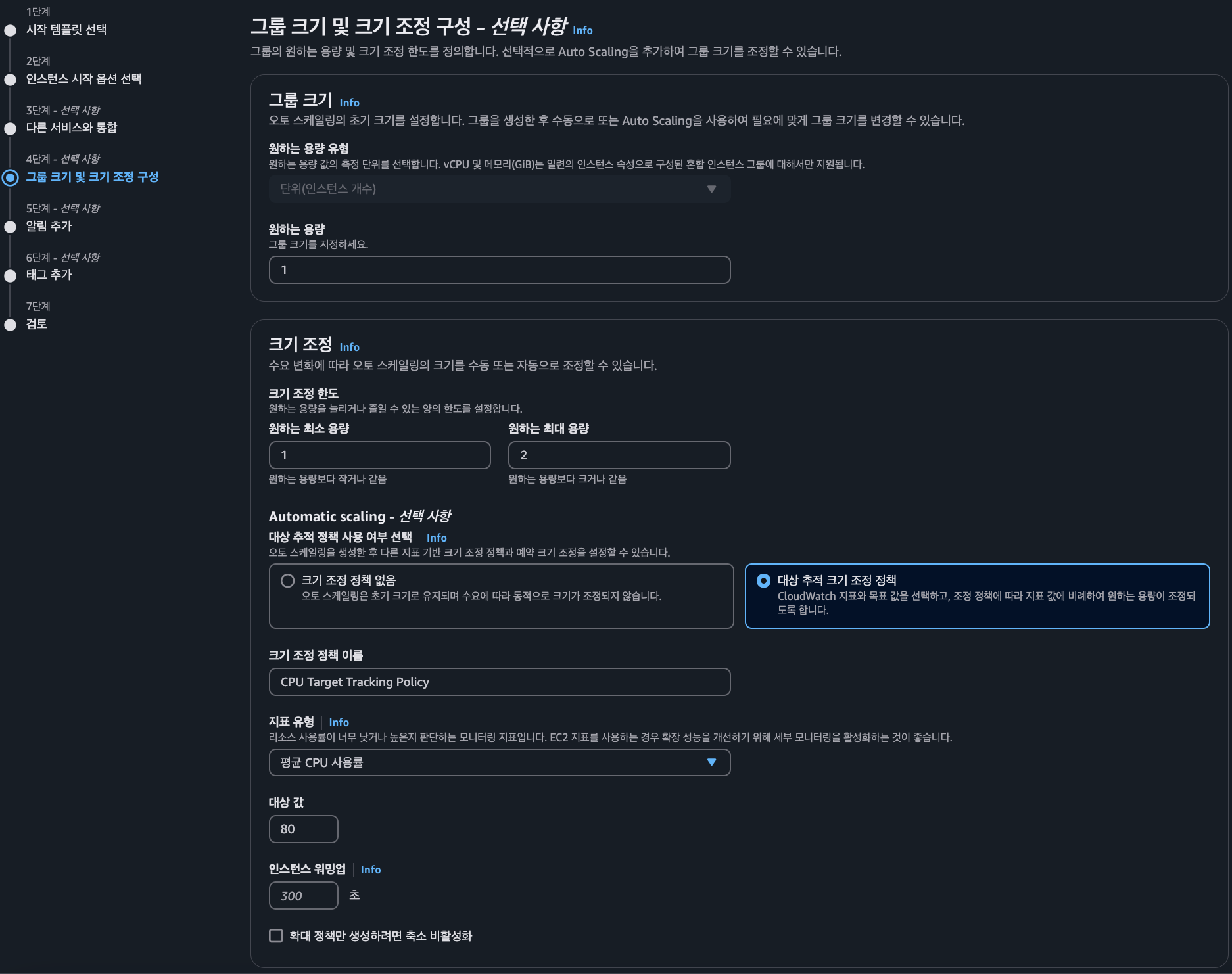
- 원하는 용량 : 인스턴스 초기 단위 수이며 설정한 수 만큼 초기 인스턴스가 생성
- 원하는 최소 용량 : 인스턴스 생성의 최소 용량
- 원하는 최대 용량 : 인스턴스 생성시 최대 허용 용량
- 지표 유형 :
평균 CPU 사용량의 경우 초기 인스턴스의 평균 CPU 사용량에 따라 그룹의 크기가 조정- 대상 값 : 평균 CPU 사용량이 특정 시점을 기준으로 대상 값을 초과하면 크기가 조정된다.
Cloud Watch, SNS, Lambda 설정
Auto Scaling 설정이 완료되면 Auto Scaling 그룹 → 활동 → 작업기록에서 인스턴스 시작 및 종료 현황을 확인할 수 있지만, 이벤트 발생시 매번 접속하기보다 Slack Webhook을 통해 쉽고 편하게 발생한 이벤트를 확인하고자 한다.
SNS
Lambda
함수 생성
SNS 트리거 추가
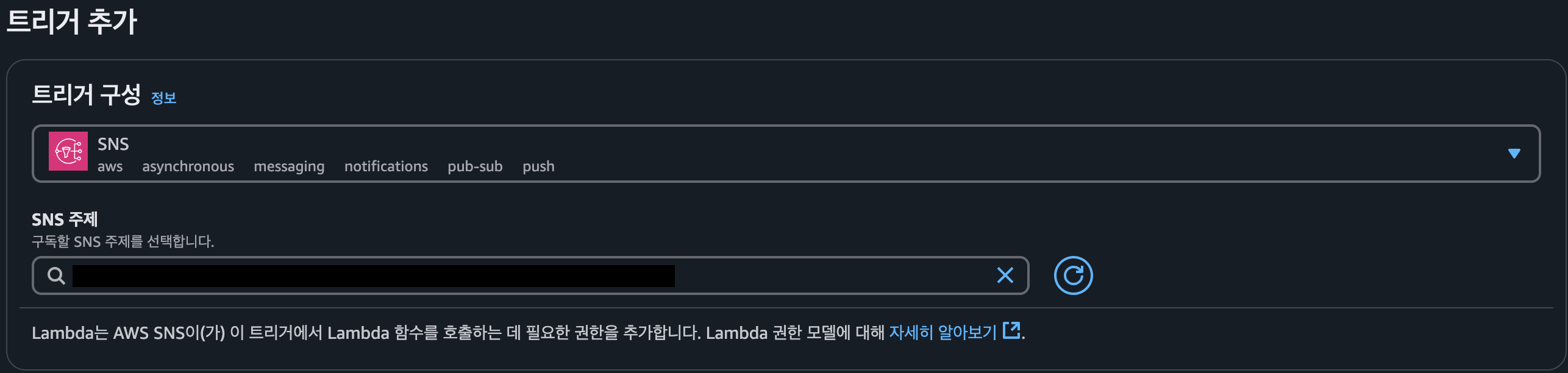
- 트리거 추가를 완료하면 SNS에 구독현황에 설정한 Lambda가 있는 것을 확인할 수 있다.
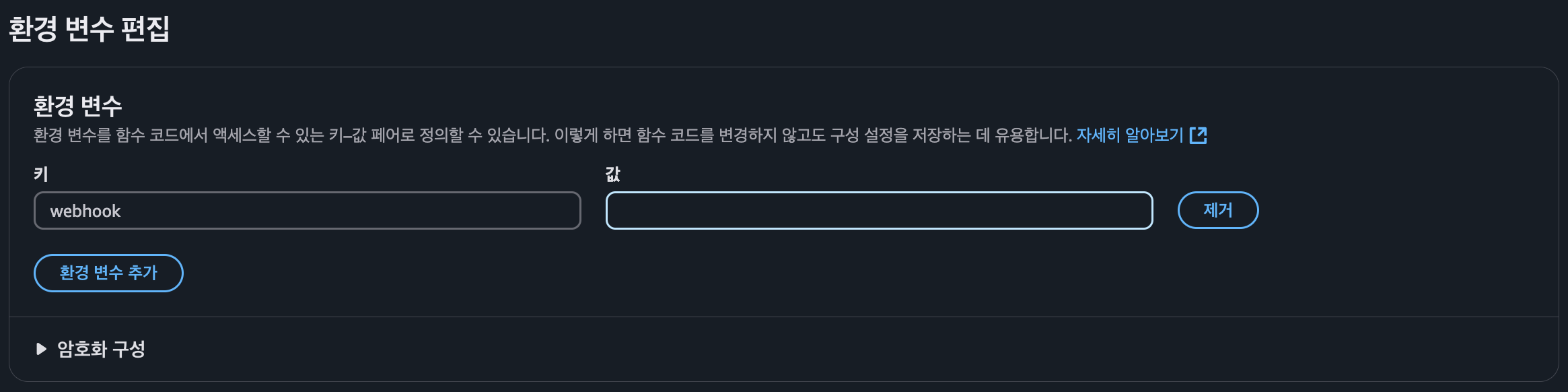
Webhook 설정
구성 → 환경 변수에서 생성한 Slack Webhook URL을 설정해준다. (키 = webhook)
index.js 추가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
// 구성 -> 환경변수로 webhook을 받도록 합니다.
const ENV = process.env
if (!ENV.webhook) throw new Error('Missing environment variable: webhook')
const webhook = ENV.webhook;
const https = require('https')
const statusColorsAndMessage = {
ALARM: {"color": "danger", "message":"위험"},
INSUFFICIENT_DATA: {"color": "warning", "message":"데이터 부족"},
OK: {"color": "good", "message":"정상"}
}
const comparisonOperator = {
"GreaterThanOrEqualToThreshold": ">=",
"GreaterThanThreshold": ">",
"LowerThanOrEqualToThreshold": "<=",
"LessThanThreshold": "<",
}
exports.handler = async (event) => {
await exports.processEvent(event);
}
exports.processEvent = async (event) => {
console.log('Event:', JSON.stringify(event))
const snsMessage = event.Records[0].Sns.Message;
console.log('SNS Message:', snsMessage);
const postData = exports.buildSlackMessage(JSON.parse(snsMessage))
await exports.postSlack(postData, webhook);
}
exports.buildSlackMessage = (data) => {
const newState = statusColorsAndMessage[data.NewStateValue];
const oldState = statusColorsAndMessage[data.OldStateValue];
const executeTime = exports.toYyyymmddhhmmss(data.StateChangeTime);
const description = data.AlarmDescription;
const cause = exports.getCause(data);
return {
attachments: [
{
title: `[${data.AlarmName}]`,
color: newState.color,
fields: [
{
title: '언제',
value: executeTime
},
{
title: '설명',
value: description
},
{
title: '원인',
value: cause
},
{
title: '이전 상태',
value: oldState.message,
short: true
},
{
title: '현재 상태',
value: `*${newState.message}*`,
short: true
},
{
title: '바로가기',
value: exports.createLink(data)
}
]
}
]
}
}
// CloudWatch 알람 바로 가기 링크
exports.createLink = (data) => {
return `https://console.aws.amazon.com/cloudwatch/home?region=${exports.exportRegionCode(data.AlarmArn)}#alarm:alarmFilter=ANY;name=${encodeURIComponent(data.AlarmName)}`;
}
exports.exportRegionCode = (arn) => {
return arn.replace("arn:aws:cloudwatch:", "").split(":")[0];
}
exports.getCause = (data) => {
const trigger = data.Trigger;
const evaluationPeriods = trigger.EvaluationPeriods;
const minutes = Math.floor(trigger.Period / 60);
if(data.Trigger.Metrics) {
return exports.buildAnomalyDetectionBand(data, evaluationPeriods, minutes);
}
return exports.buildThresholdMessage(data, evaluationPeriods, minutes);
}
// 이상 지표 중 Band를 벗어나는 경우
exports.buildAnomalyDetectionBand = (data, evaluationPeriods, minutes) => {
const metrics = data.Trigger.Metrics;
const metric = metrics.find(metric => metric.Id === 'm1').MetricStat.Metric.MetricName;
const expression = metrics.find(metric => metric.Id === 'ad1').Expression;
const width = expression.split(',')[1].replace(')', '').trim();
return `${evaluationPeriods * minutes} 분 동안 ${evaluationPeriods} 회 ${metric} 지표가 범위(약 ${width}배)를 벗어났습니다.`;
}
// 이상 지표 중 Threshold 벗어나는 경우
exports.buildThresholdMessage = (data, evaluationPeriods, minutes) => {
const trigger = data.Trigger;
const threshold = trigger.Threshold;
const metric = trigger.MetricName;
const operator = comparisonOperator[trigger.ComparisonOperator];
return `${evaluationPeriods * minutes} 분 동안 ${evaluationPeriods} 회 ${metric} ${operator} ${threshold}`;
}
// 타임존 UTC -> KST
exports.toYyyymmddhhmmss = (timeString) => {
if(!timeString){
return '';
}
const kstDate = new Date(new Date(timeString).getTime() + 32400000);
function pad2(n) { return n < 10 ? '0' + n : n }
return kstDate.getFullYear().toString()
+ '-'+ pad2(kstDate.getMonth() + 1)
+ '-'+ pad2(kstDate.getDate())
+ ' '+ pad2(kstDate.getHours())
+ ':'+ pad2(kstDate.getMinutes())
+ ':'+ pad2(kstDate.getSeconds());
}
exports.postSlack = async (message, slackUrl) => {
return await request(exports.options(slackUrl), message);
}
exports.options = (slackUrl) => {
const {host, pathname} = new URL(slackUrl);
return {
hostname: host,
path: pathname,
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
};
}
function request(options, data) {
return new Promise((resolve, reject) => {
const req = https.request(options, (res) => {
res.setEncoding('utf8');
let responseBody = '';
res.on('data', (chunk) => {
responseBody += chunk;
});
res.on('end', () => {
resolve(responseBody);
});
});
req.on('error', (err) => {
console.error(err);
reject(err);
});
req.write(JSON.stringify(data));
req.end();
});
}
코드 탭에서 위 코드로 index.js 생성 후 Deploy를 한다. 코드는 아래 블로그를 참고했습니다.
Webhook 테스트
테스트 탭에서 이벤트 Json란에 아래 코드를 통해 테스트를 할 수 있으며 결과는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"Records": [
{
"EventSource": "aws:sns",
"EventVersion": "1.0",
"EventSubscriptionArn": "{구독ARN}",
"Sns": {
"Type": "Notification",
"MessageId": "test",
"TopicArn": "{주제 ARN}",
"Subject": "ALARM: \"RDS-CPUUtilization-high\" in Asia Pacific (Seoul)",
"Message": "{\"AlarmName\":\"Auto Scaling CPU 알람 (70% 초과)\",\"AlarmDescription\":\"Aurora Auto Scaling CPU 알람 (70% 초과)\",\"AWSAccountId\":\"{AWS Account Id}\",\"NewStateValue\":\"ALARM\",\"NewStateReason\":\"Threshold Crossed: 3 out of the last 3 datapoints [8.891518474692088 (24/12/13 10:30:00), 9.72 (24/12/13 10:30:00), 9.18241509182415 (24/12/13 10:30:00)] were greater than or equal to the threshold (7.0) (minimum 3 datapoints for OK -> ALARM transition).\",\"StateChangeTime\":\"2024-12-08T15:00:00.708+0000\",\"Region\":\"Asia Pacific (Seoul)\",\"AlarmArn\":\"{Cloud Watch ARN}\",\"OldStateValue\":\"OK\",\"Trigger\":{\"MetricName\":\"CPUUtilization\",\"Namespace\":\"AWS/ASG\",\"StatisticType\":\"Statistic\",\"Statistic\":\"MAXIMUM\",\"Unit\":null,\"Dimensions\":[{\"value\":\"aurora-postgresql\",\"name\":\"EngineName\"}],\"Period\":60,\"EvaluationPeriods\":3,\"ComparisonOperator\":\"GreaterThanOrEqualToThreshold\",\"Threshold\":7,\"TreatMissingData\":\"- TreatMissingData: ignore\",\"EvaluateLowSampleCountPercentile\":\"\"}}",
"Timestamp": "2024-12-13T10:30:17.380Z",
"SignatureVersion": "1",
"MessageAttributes": {}
}
}
]
}

Cloud Watch
Cloud Watch → 모든 경보 → 경보 생성에서 경보를 생성한다.
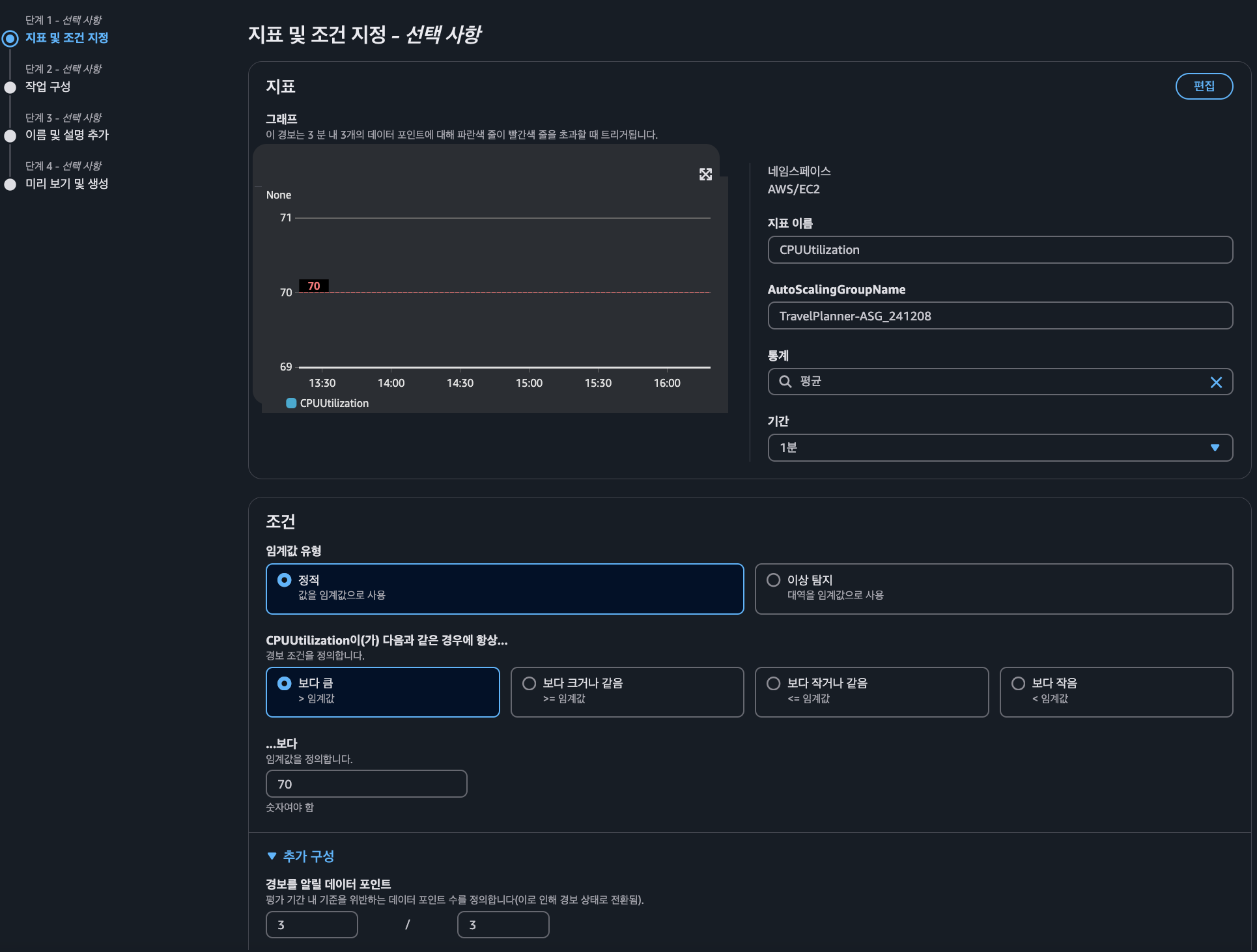
지표 설정
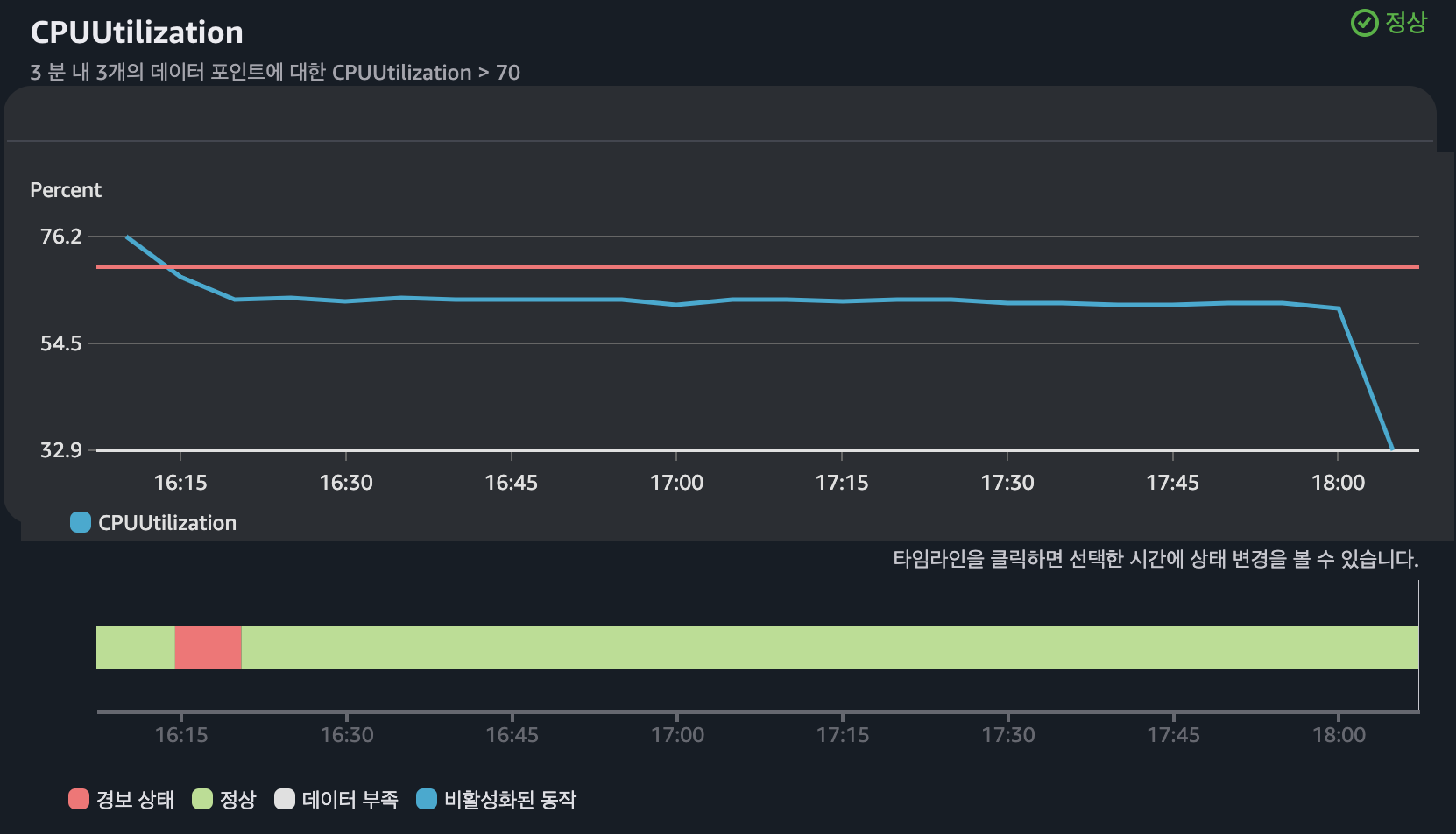
지표의 경우 경보를 받고자 하는 지표를 선택한다. 아래 설정의 경우 Auto Scaling 그룹에서 3분동안 3번의 평균 CPU 사용률이 70%가 초과하면 경보 상태로 인지한다는 의미이다.
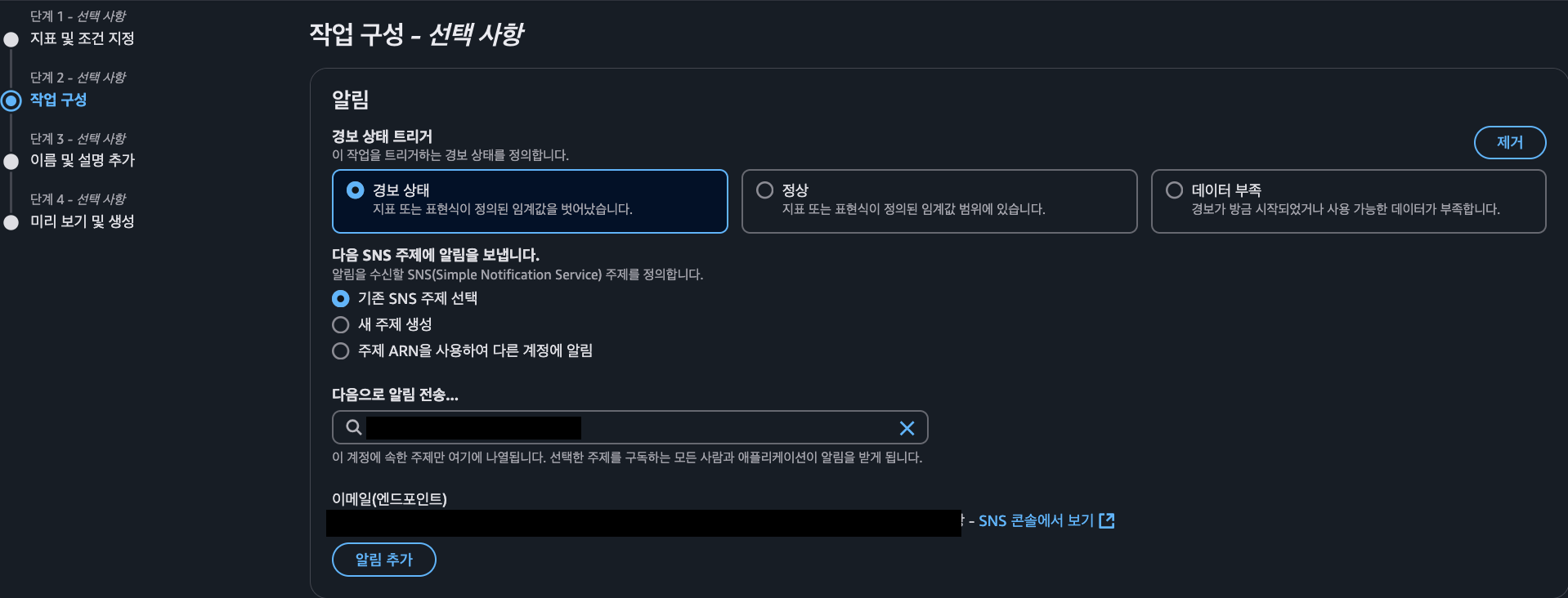
SNS 작업 구성
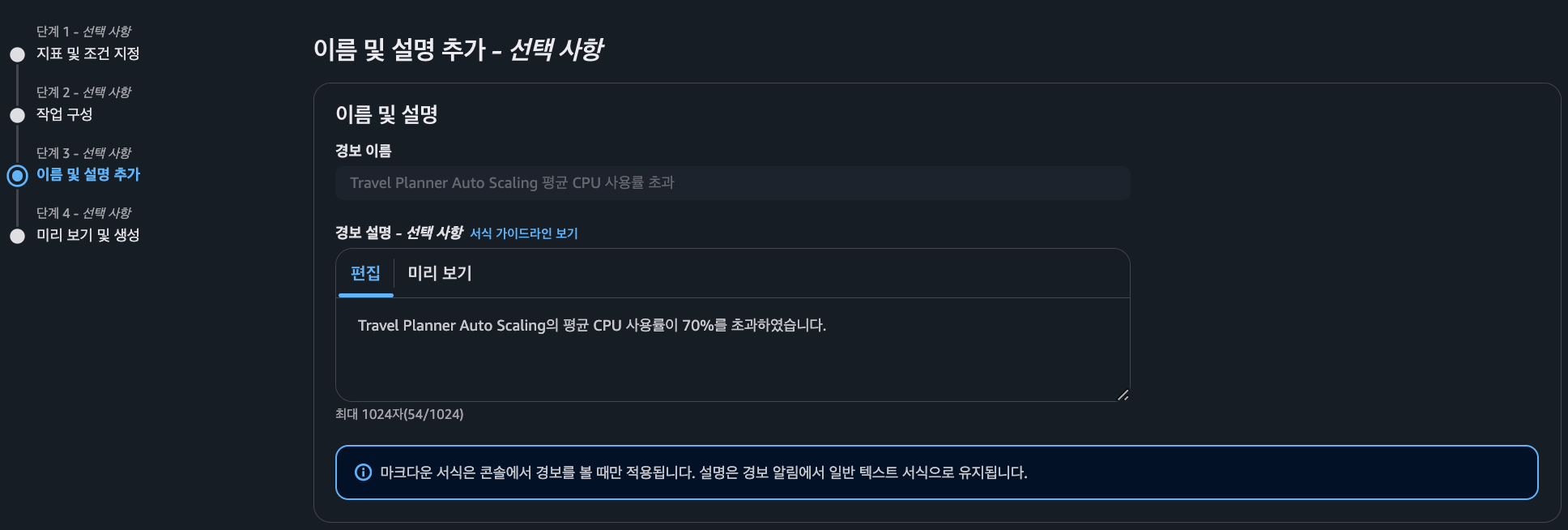
알람 제목 및 설명 설정
경보에 대한 이름과 설명을 추가한다. 알람 테스트 결과에서 알람 제목과 원인란에 기입된다.
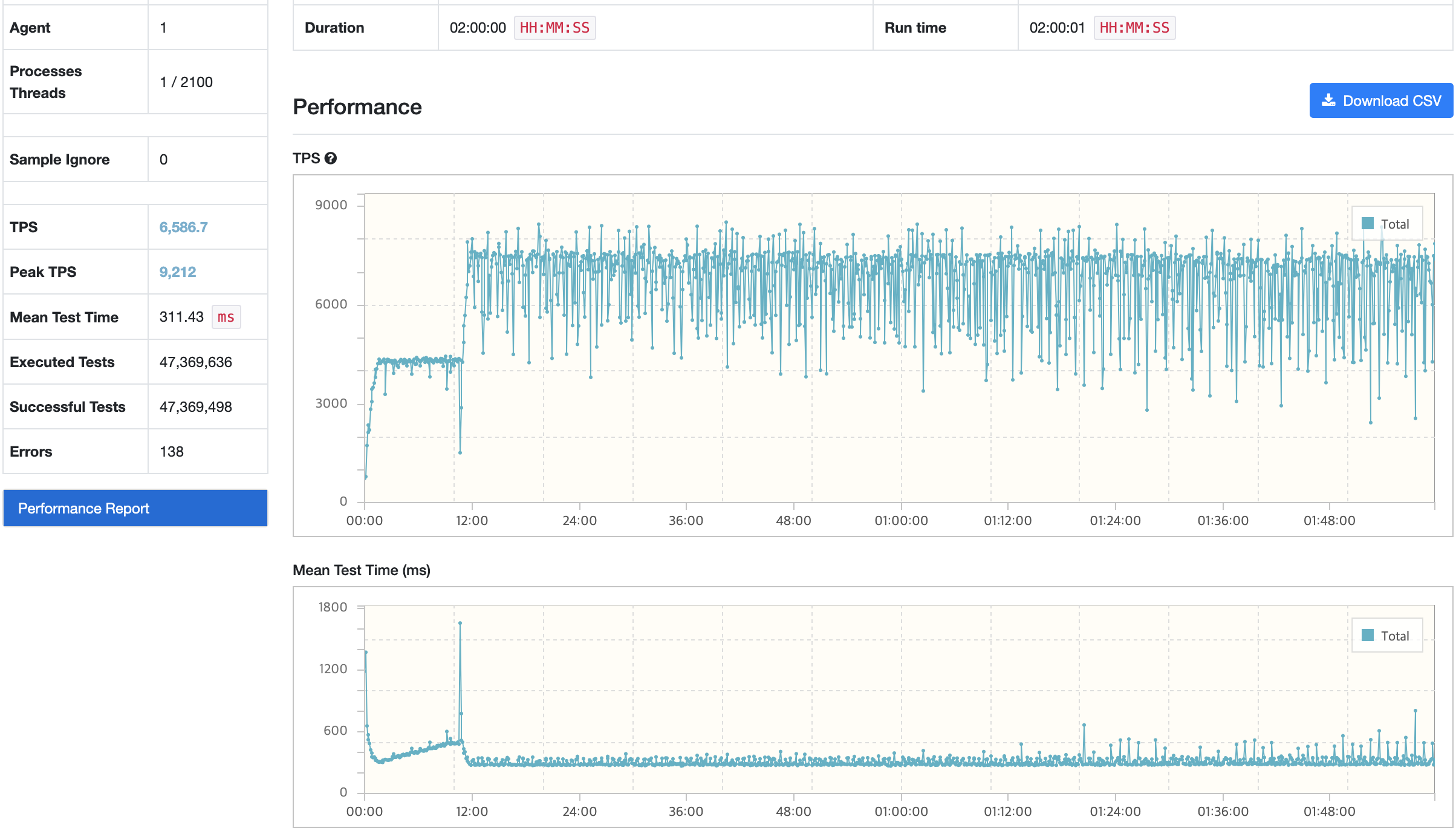
스트레스 테스트
스트레스 테스트의 경우 3개의 시나리오 중 리소스 사용률이 가장 높았었던 시나리오2를 테스트해보았으며, 테스트 과정에서 서버 Scale In/Out은 아래와 같다.
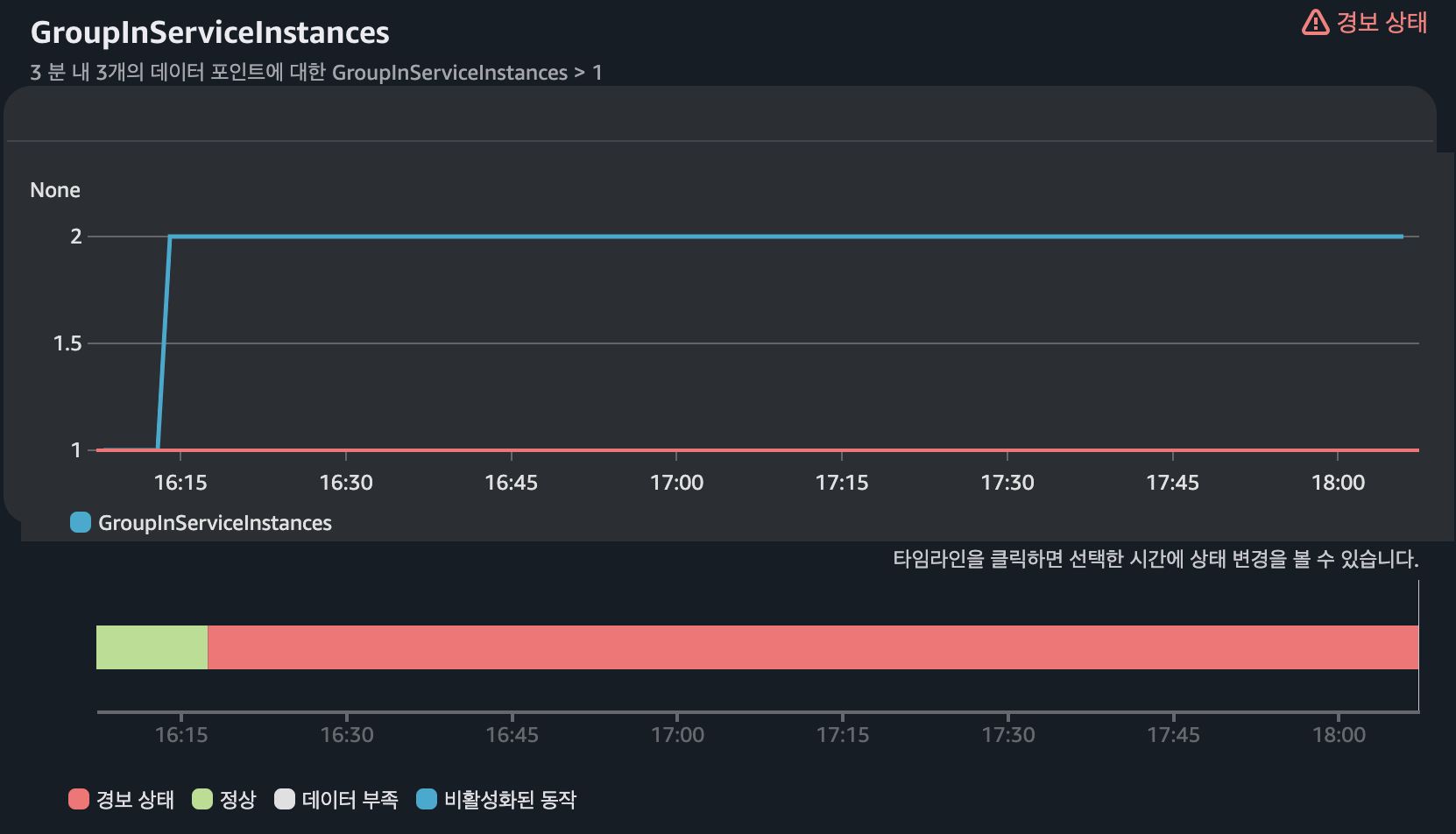
- Auto Scaling Group에 구성된 인스턴스 평균 CPU 사용률이 70% 초과하면 신규 인스턴스 생성
- 기본 1개의 인스턴스로 구성되고 최대 2개까지 확장
- 인스턴스 축소 과정에서 가장 최근에 생성된 인스턴스부터 종료
- 신규 인스턴스 수명은 최대 1일로 설정 (최소 1일부터 설정 가능)
사전 설정
- Tomcat Worker Thread : 20 → 25
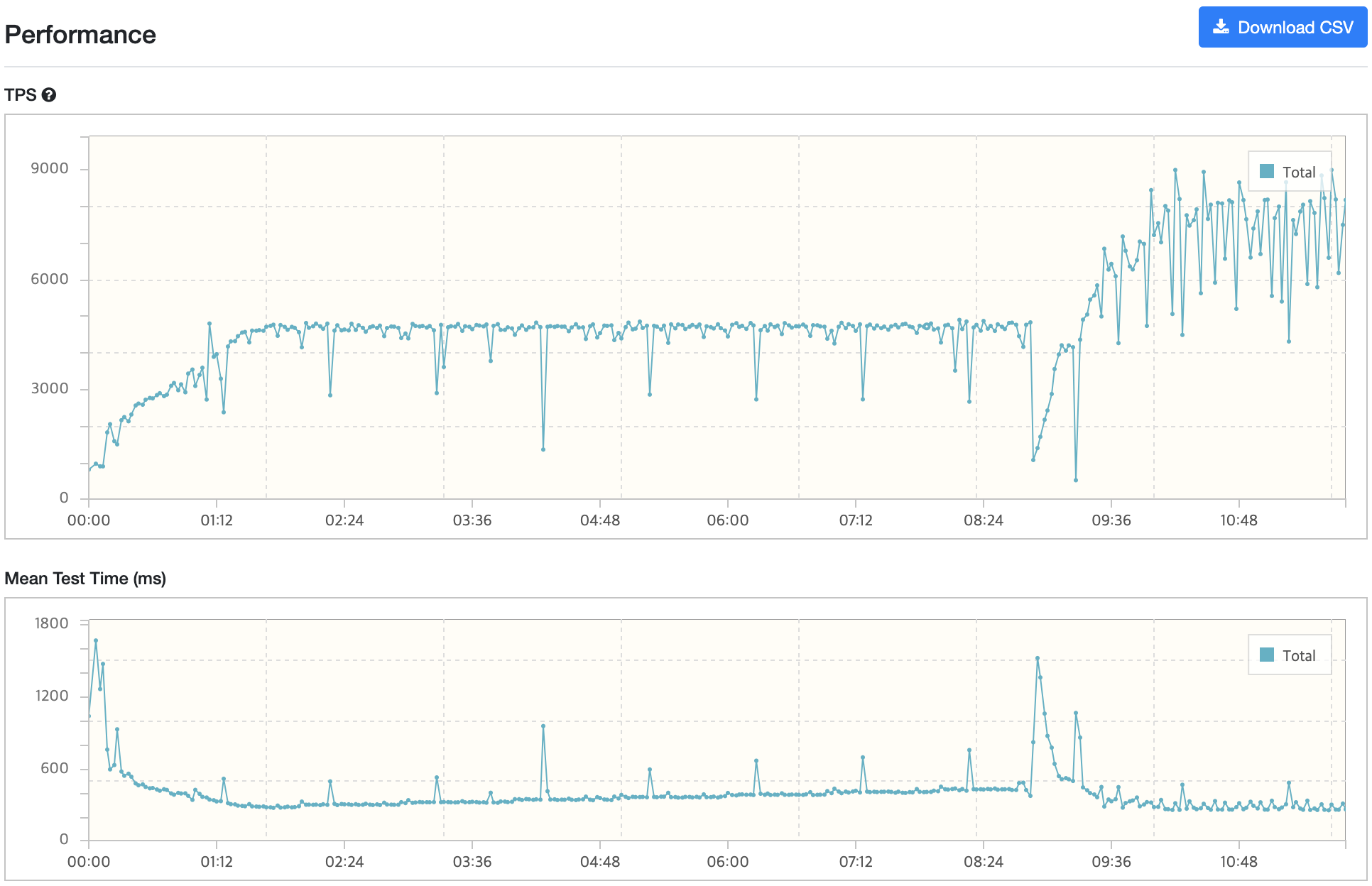
테스트 결과
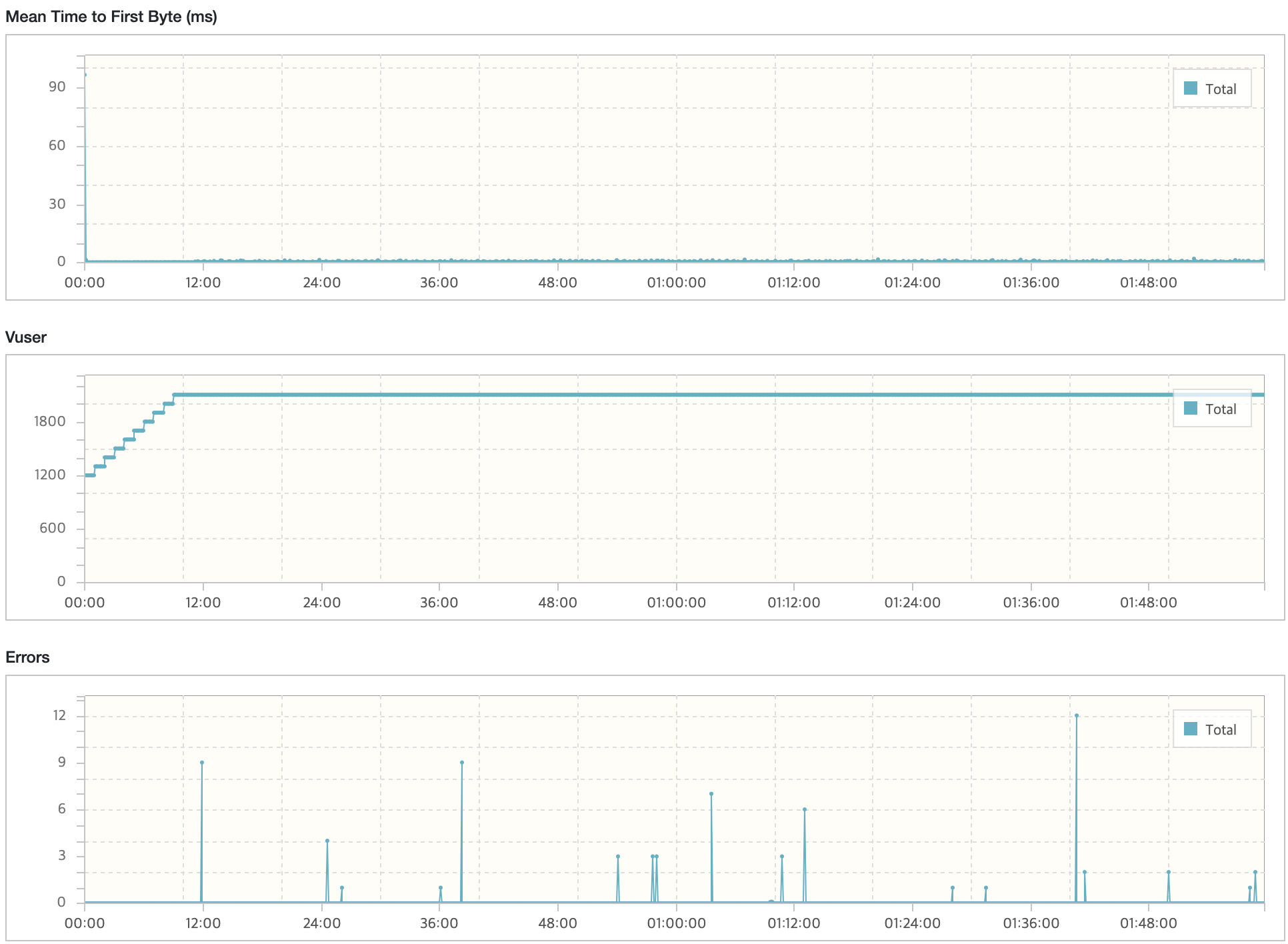
nGrinder
기본 API 서버

Auto Scaling으로 생성된 API 서버

RDS - MySQL
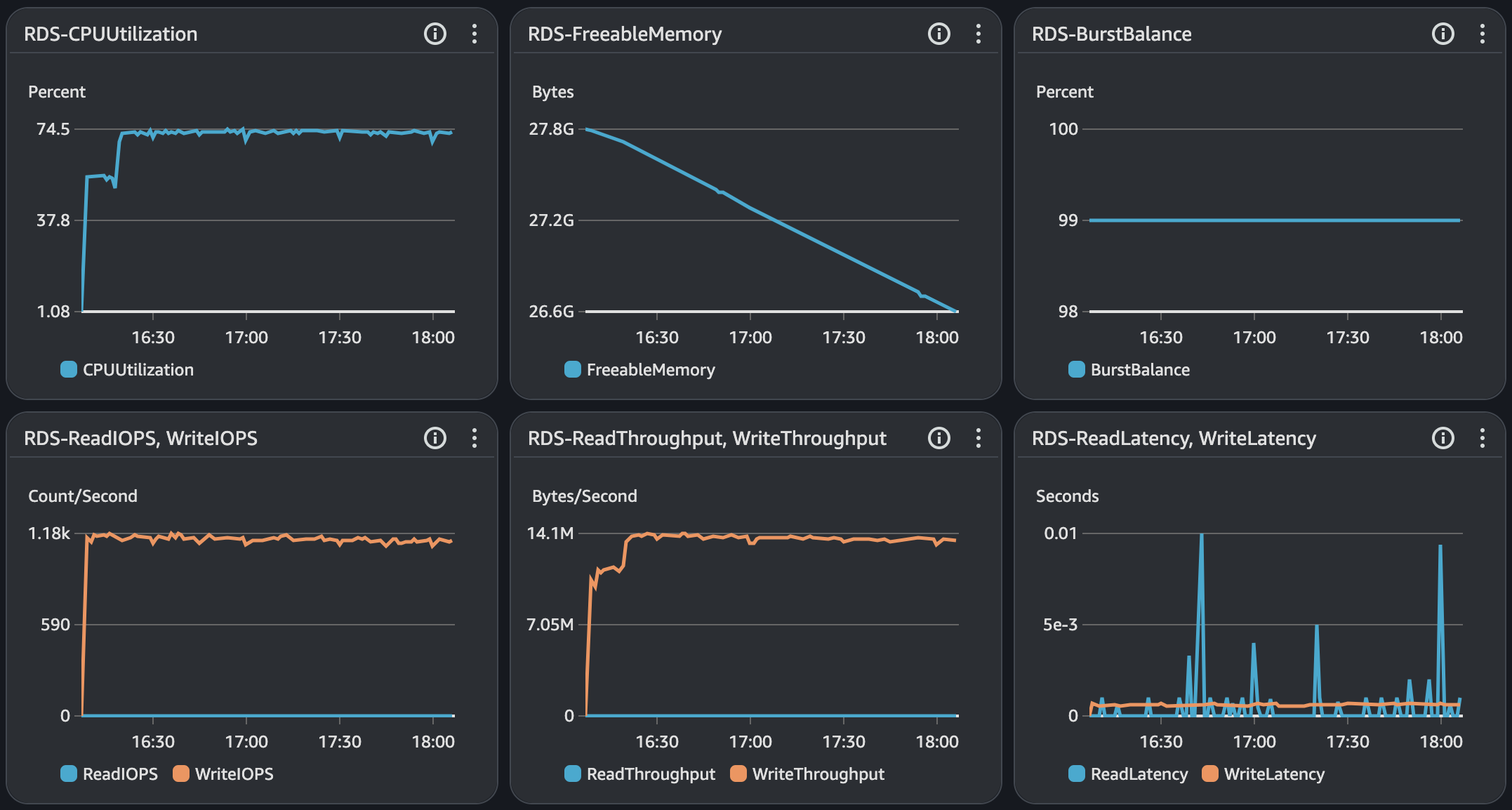
Cloud Watch Monitoring & Alarm
CPU 부하

Scale Out

트러블 슈팅
문제 상황 발생
테스트는 VUser 1200부터 시작해 1분동안 약 100씩 증가시키는 과정으로 진행했다. 약 10분이 지난 시점에 급격하게 트래픽이 낮아지고 MTT가 증가하는 현상을 확인했을 때를 보면 신규 인스턴스가 정상화가 되면서 Latency가 발생하였다.
아래 지표에서 보면 신규 서버에 트래픽이 발생하는 첫 시점에 Response Time이 가장 높은 것을 볼 수 있었다.
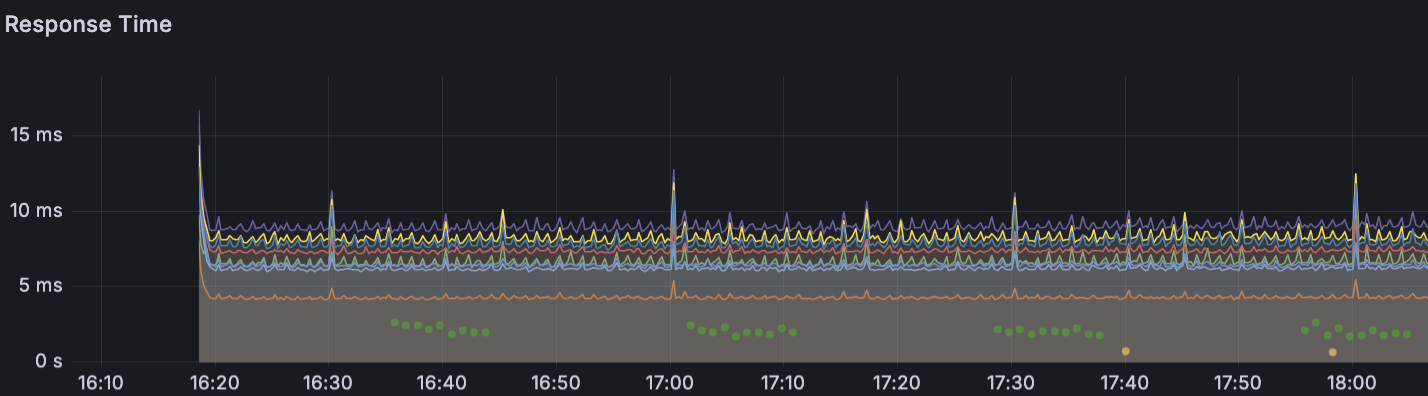
원인 분석 및 해결방안1
Latency가 발생한 시점에 Auto Scaling으로 인한 신규 인스턴스가 운영 상태가 되었다. 애플리케이션이 시작될 시 발생하는 성능 저하의 여러가지 원인 중 JVM Warm-up 과정이 없어서 발생한 것으로 확인된다.
Java에는 클래스를 읽어오기 위해 클래스 로더가 이용한다. 클래스 로더는 일반적으로는 Lazy Loading 방식으로 동작하기에 배포 직후에는 클래스는 클래스 로더에 의해 메모리에 적제되어있지 않은 상태이다. 이런 상태에서 API가 호출될 때 클래스 로더에 의해 클래스들이 최초로 메모리에 적제되어지는데 이 과정에서 Latency가 발생하게 된다. 클래스 로더 Warm-up은 아래와 같이 ApplicationRunner를 이용해 진행할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Component
public class WarmupRunner implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) {
try {
//사용 되는 클래스를 호출
}
catch (Exception e){
e.printStackTrace();
}
}
}
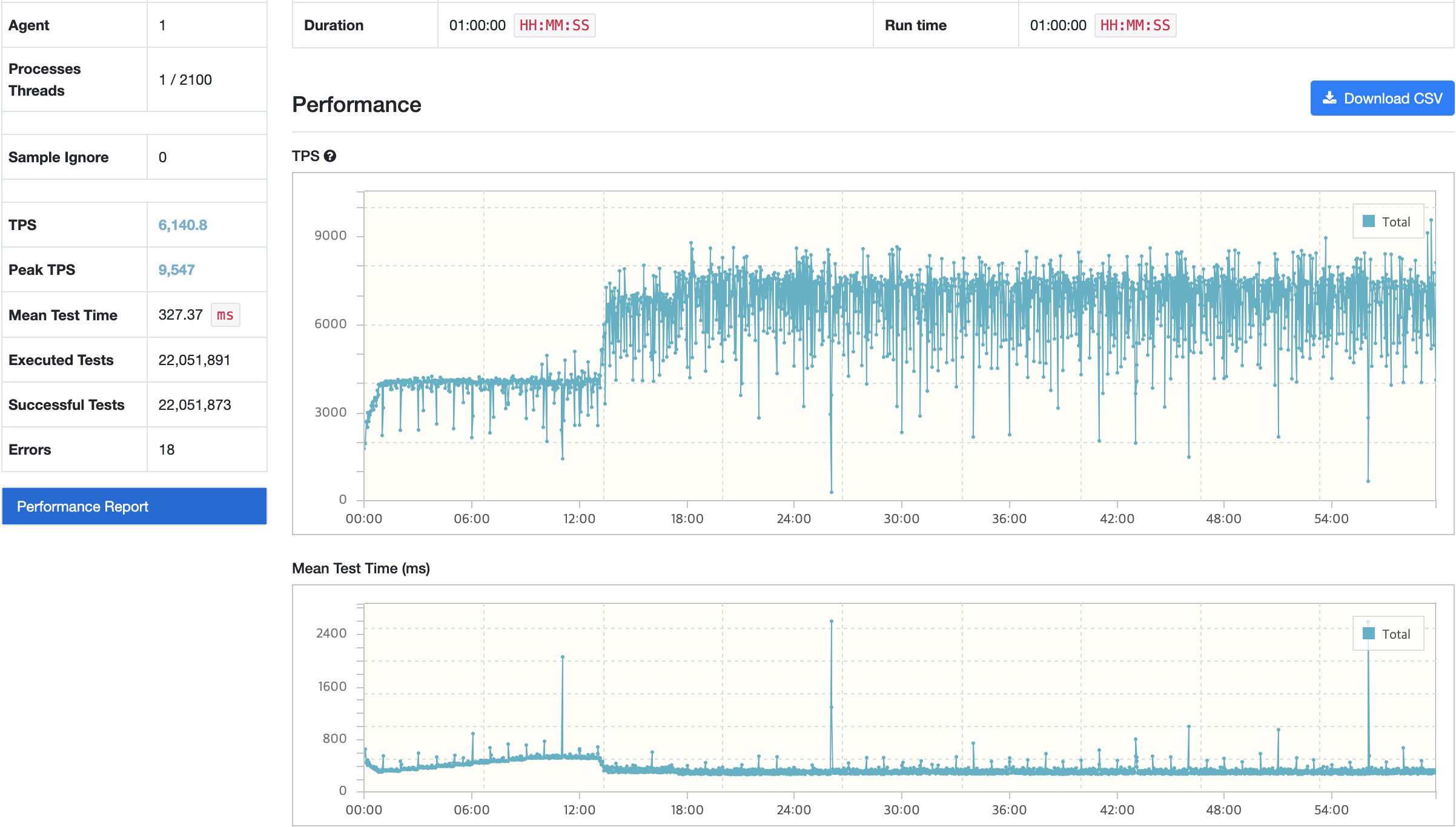
결과1
Before 클래스 로더 Warm Up

After 클래스 로더 Warm Up

ApplicationRunner를 이용한 Warm Up시 API의 응답시간 차이는 약 2배 차이난다.
변화가 없다…
원인 분석 및 해결방안2
JIT 컴파일러 Warm Up
JVM Warm-up에는 클래스 로더 외 JIT 컴파일러가 있다. JIT 컴파일러에는 C1, C2 컴파일러가 있으며 C1 컴파일러의 경우 초반 성능을 올리는 역할을 하며 C2 컴파일러의 경우 C1에 비해 더 오랜 기간동안 남아있는 코드를 관찰하고 분석한다.
정리하면 C1은 초기 단계에서 빠르게 성능을 끌어 올리고 이후에 C2가 더 자주 사용되는 코드를 모아서 더 나은 컴파일된 코드로 재컴파일한다. C2 컴파일러를 통해 성능이 최적화가 되며 Tiered Compilation 단계라고 한다.
클래스 로더 Warm Up의 경우 반복되는 실행은 JVM에 부하만 발생한다. 실제로 Loop를 통해 100, 1000번 반복해도 효과가 없었다.
JIT 컴파일러는 실제 Workload만 최적화한다. 즉, API 호출하여 실행되는 코드에 대해서만 최적화를 진행하기에 실제 JIT 컴파일러 Warm-up API를 만들고 API를 호출할 스크립트를 만들어 실행해야한다.
JIT 컴파일러 Warm-up 작업 전 설정된 TieredStopAtLevel을 확인해야하며, 값은 변경이 가능하고 레벨별 정보는 아래와 같다.
- 0(Interpreter) : 코드가 처음 실행될 때 바이트코드를 직접 인터프리트하여 실행하고 컴파일 오버헤드가 없지만, 실행 속도는 느리다.
- 1(C1 컴파일러) : 빠르게 컴파일하여 성능을 향상시키는 데 초점을 맞추며 일반적으로 최적화 수준이 낮고, Warm-up(준비) 단계에서 유용하다.
- 4(C2 컴파일러) : 고도의 최적화를 수행하며, 실행 속도 최적화에 집중하며 최적화에 시간이 더 걸리지만, 애플리케이션의 성능을 크게 개선한다.
C1 컴파일러의 기본 Threshold는 1,500회이고 C2 컴파일러의 기본 Threshold는 10,000회
Warm Up Shell Script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#!/bin/bash
container_name='{Container 명}'
# Health Check
while [ 1 = 1 ]; do
sleep 3
curl -S {Host IP or DNS Health Check URL}
if [[ $? -eq 0 ]]; then
echo "Curl 호출이 성공했습니다."
break # curl 호출이 성공하면 while문을 종료
fi
done
# '[[.State.Status]]'의 대괄호를 중괄호로 변경
container_status=$(docker inspect --format '[[.State.Status]]' $container_name)
# Container 정상 운영 상태 확인
if [[ "$container_status" == "running" ]]; then
# Warm Up Api 10000번 호출
for ((i=0; i<10000; i++));
do
response_code=$(curl -s -o /dev/null -w "%{http_code}" -X POST -H -d {Host IP or DNS Warm Up URL})
if [[ "$response_code" -eq 200 ]]; then
((count++))
fi
done
echo "Attempt 1000: Response code 200. Count = $count"
# Warm Up 완료 Api 호출
response_code2=$(curl -s -o /dev/null -w "%{http_code}" -X POST -H -d {Host IP or DNS Warm Up Complete URL})
if [[ "$response_code2" -eq 200 ]]; then
echo "Warm Up Completed"
else
echo "Warm Up Not Completed"
fi
fi
exit 0
결과2
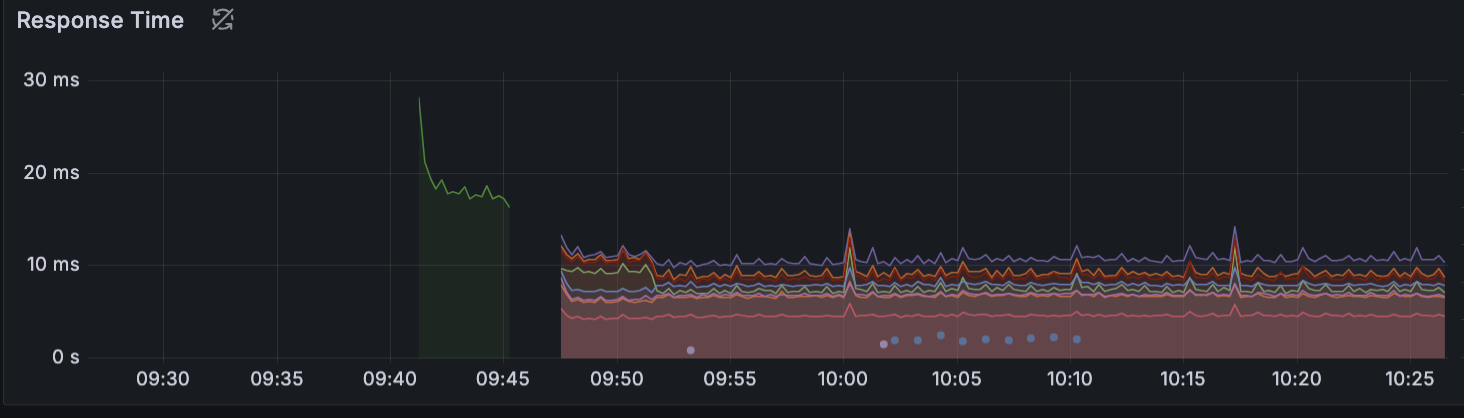
- Warm Up 작업이 완료되어야 대상그룹의 Health Check를 만족할 수 있도록했다.
Warm Up에 대한 호출 횟수는 1500, 10000 2번의 테스트를 진행했으며, 10000번의 호출을 해야 평균 응답시간에 만족할 수 있게 최적화가 되었으며, 10분이 넘어가면서 신규 인스턴스가 확장되고 Lantency가 발생했던 시점에 성능 저하가 발생하지 않고 TPS가 자연스럽게 증가되었다.
마무리
Auto Scaling을 통한 Scale Out 그리고 배포시에 Warm Up 과정은 실제 운영에서 중요한 부분이다.
이번 스트레스 테스트에서 Warm Up을 처음 알게 되었다. 부하 및 내구성 테스트 과정에서 배포한 후 성능저하가 있다는 것은 인지하고 있었다. 그래서 테스트 전 2분 동안 수동으로 Warm Up을 했었지만 불필요한 시간과 작업을 하고 있었고 그때는 큰 문제라고 생각하지 않았던 것 같다.
실제 서비스 운영시 Scale Out 과정에서 급격한 성능 저하는 큰 이슈이다. 이러한 점에서 JVM Warm Up은 초기 이슈 발생을 막을 수 있으며 성능 개선을 위해 필수적이라고 생각한다.