대용량 트래픽 경험해보기(11/14) - 내구성 테스트와 GC Tuning
지난 글에서 부하 테스트를 진행하였다. 이번 글에서는 4시간의 테스트 동안 서버가 어느정도의 트래픽을 버티며 어느 시점부터 목표 수치를 넘어가거나 성능이 저하되는 지점을 찾아서 확인해보려한다.
인프라 사양
| 구분 | EC2 | RDS | ElastiCache(Redis) |
|---|---|---|---|
| 인스턴스 유형 | c5a.2xlarge | db.t4g.xlarge | cache.t2.micro |
| vCPU | 8(4코어) | 8(4코어) | 1 |
| Memory | 15Gb | 32Gb | 0.555Gb |
| Network | High | 2,780Mbps | 낮음에서 중간 |
| 비용 | 시간당 0.454USD | 시간당 0.813USD | 시간당 0.0208USD |
내구성 테스트
시나리오1
nGrinder
API 서버

RDS - MySQL
시나리오2
nGrinder
API 서버

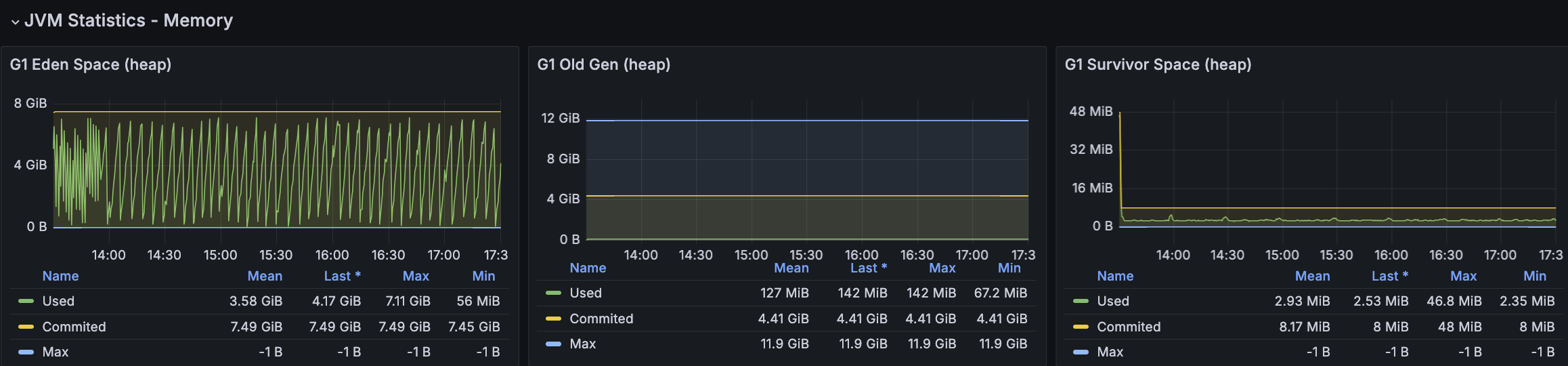
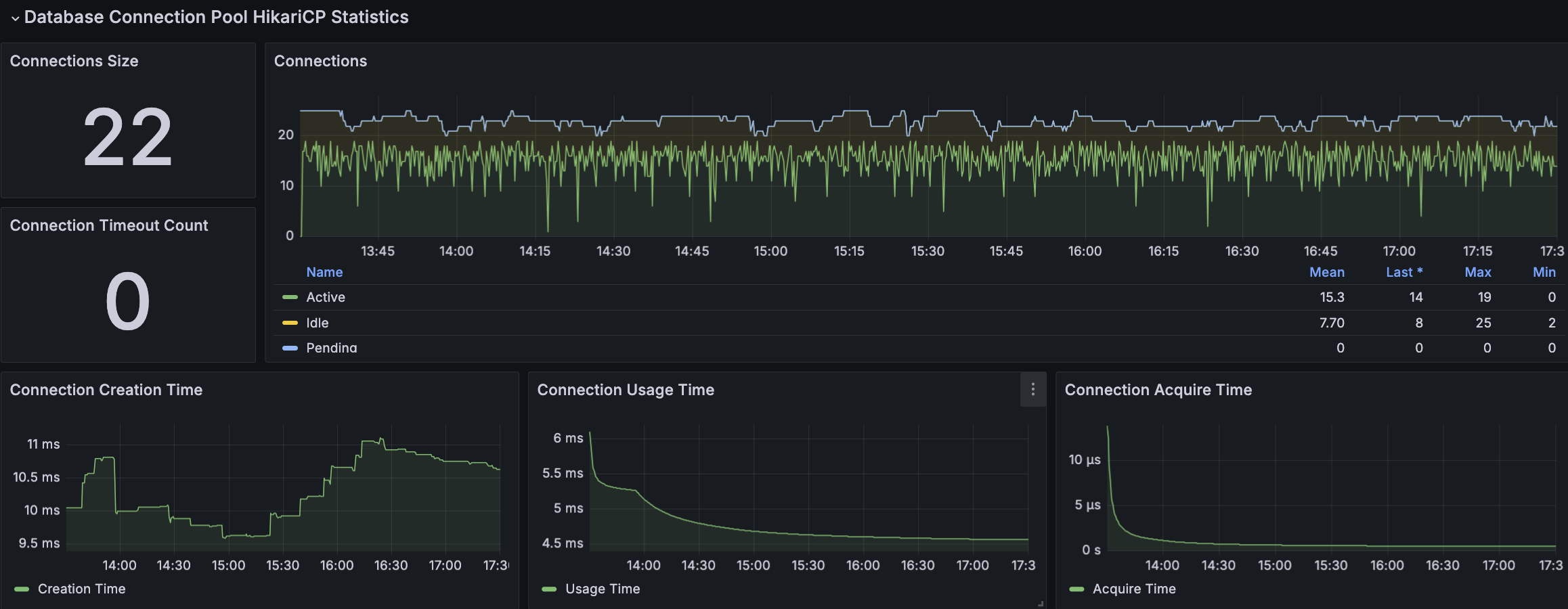
RDS - MySQL
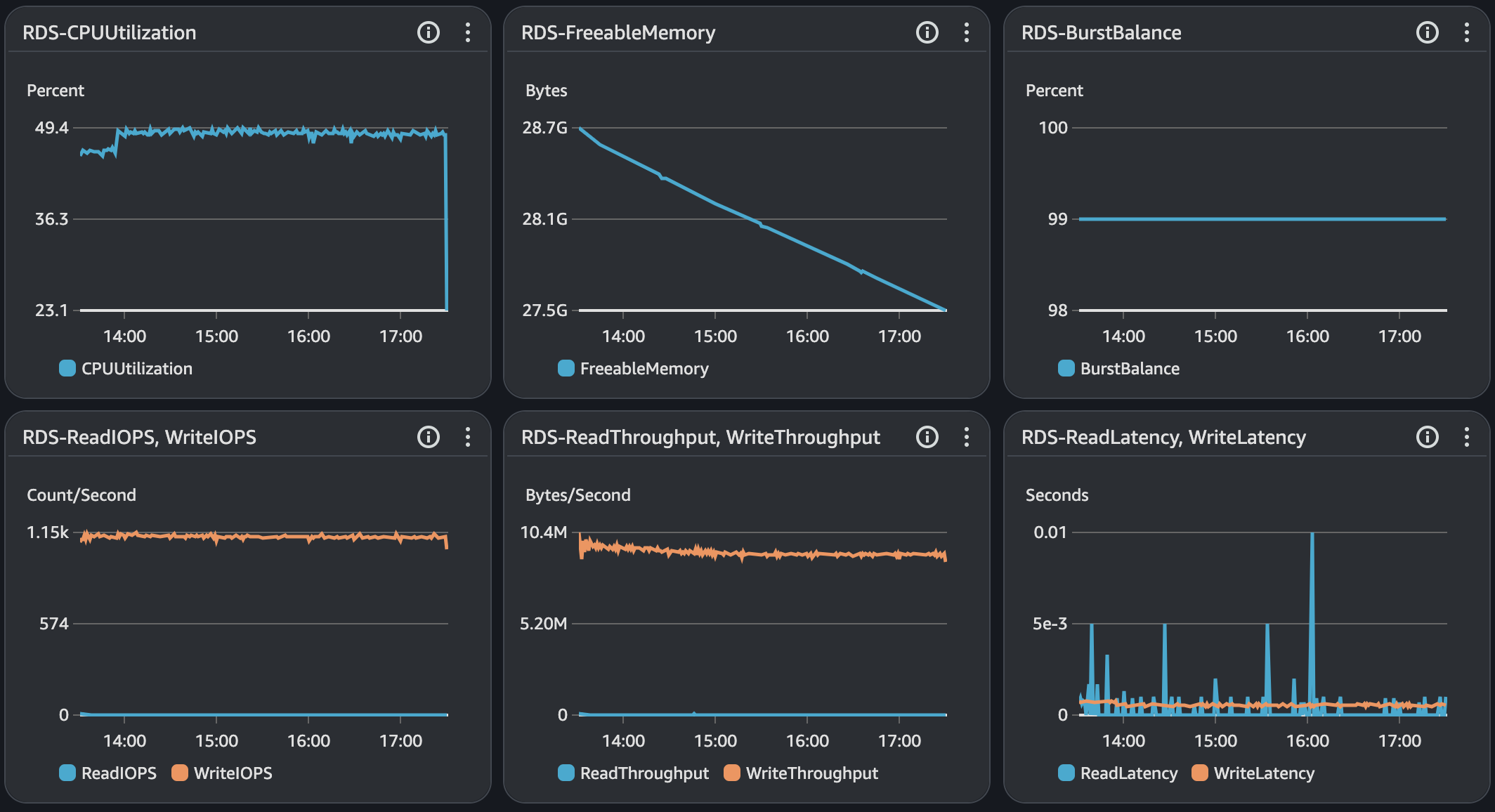
시나리오3
nGrinder
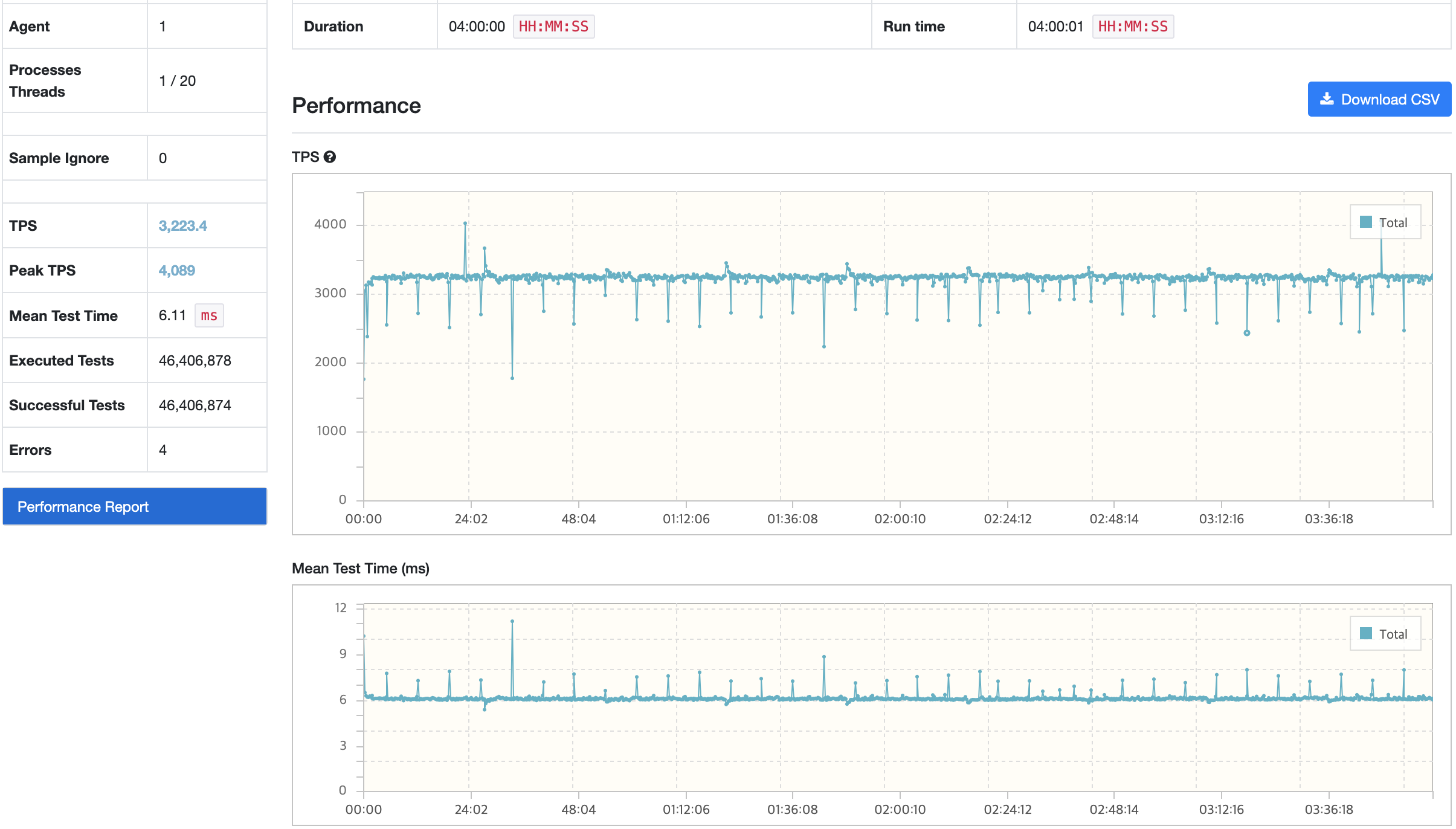
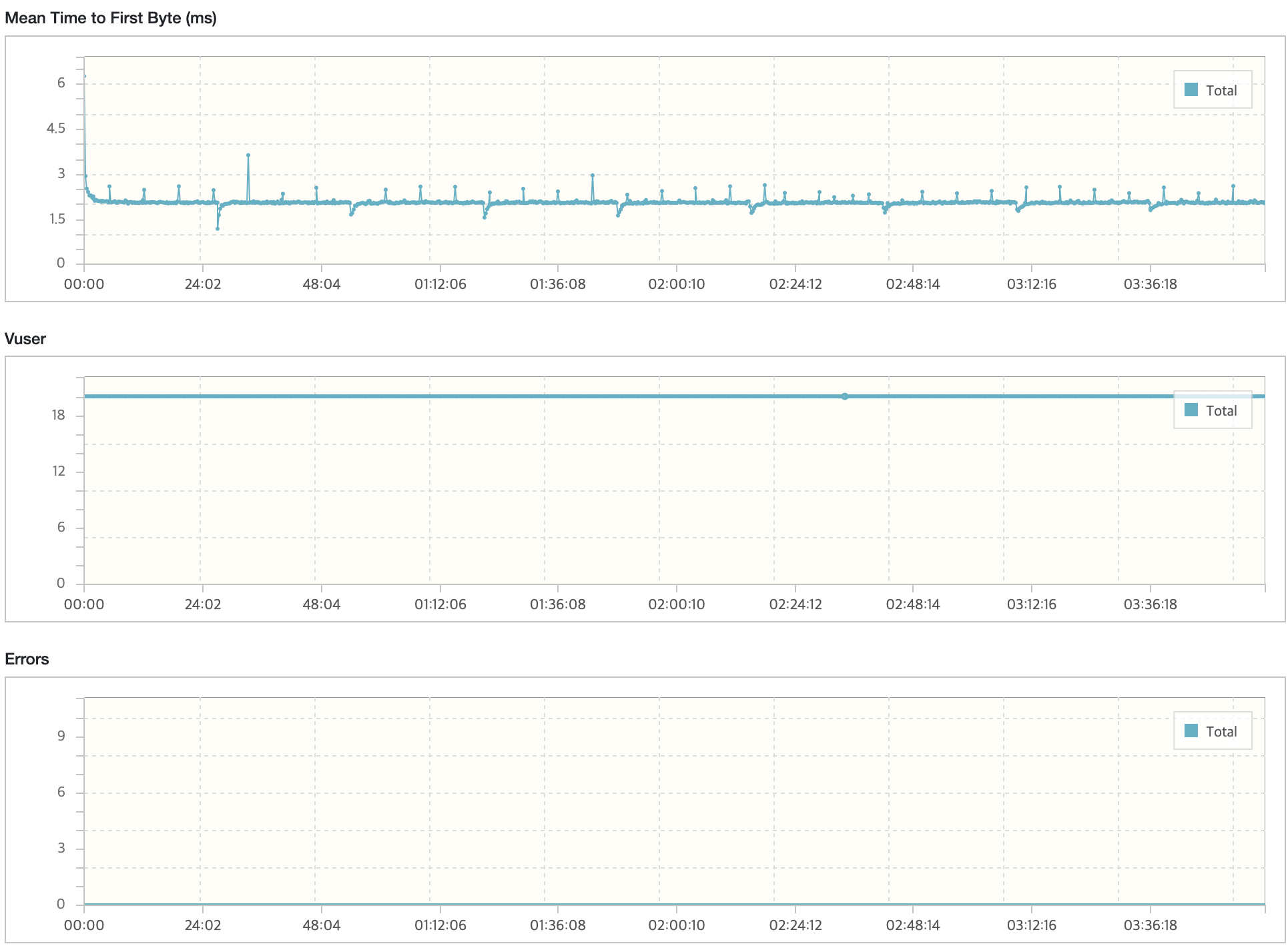
API 서버

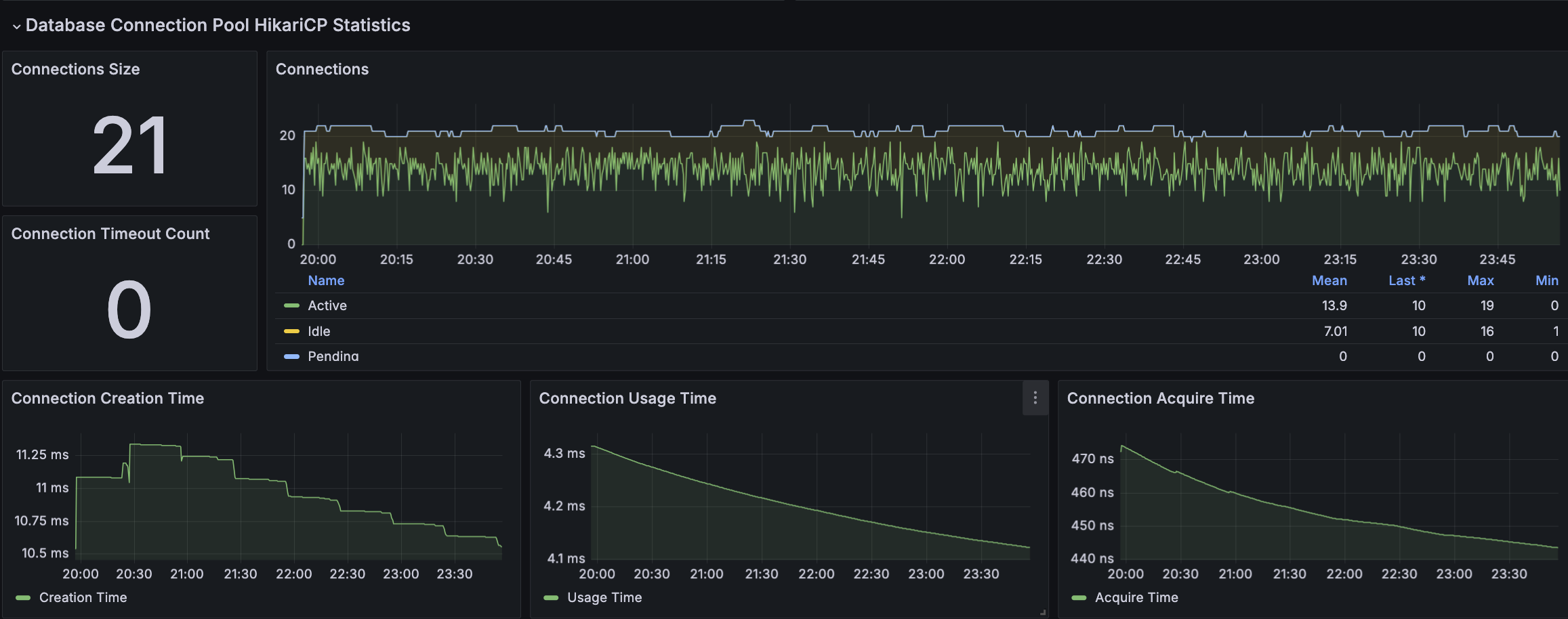
RDS - MySQL
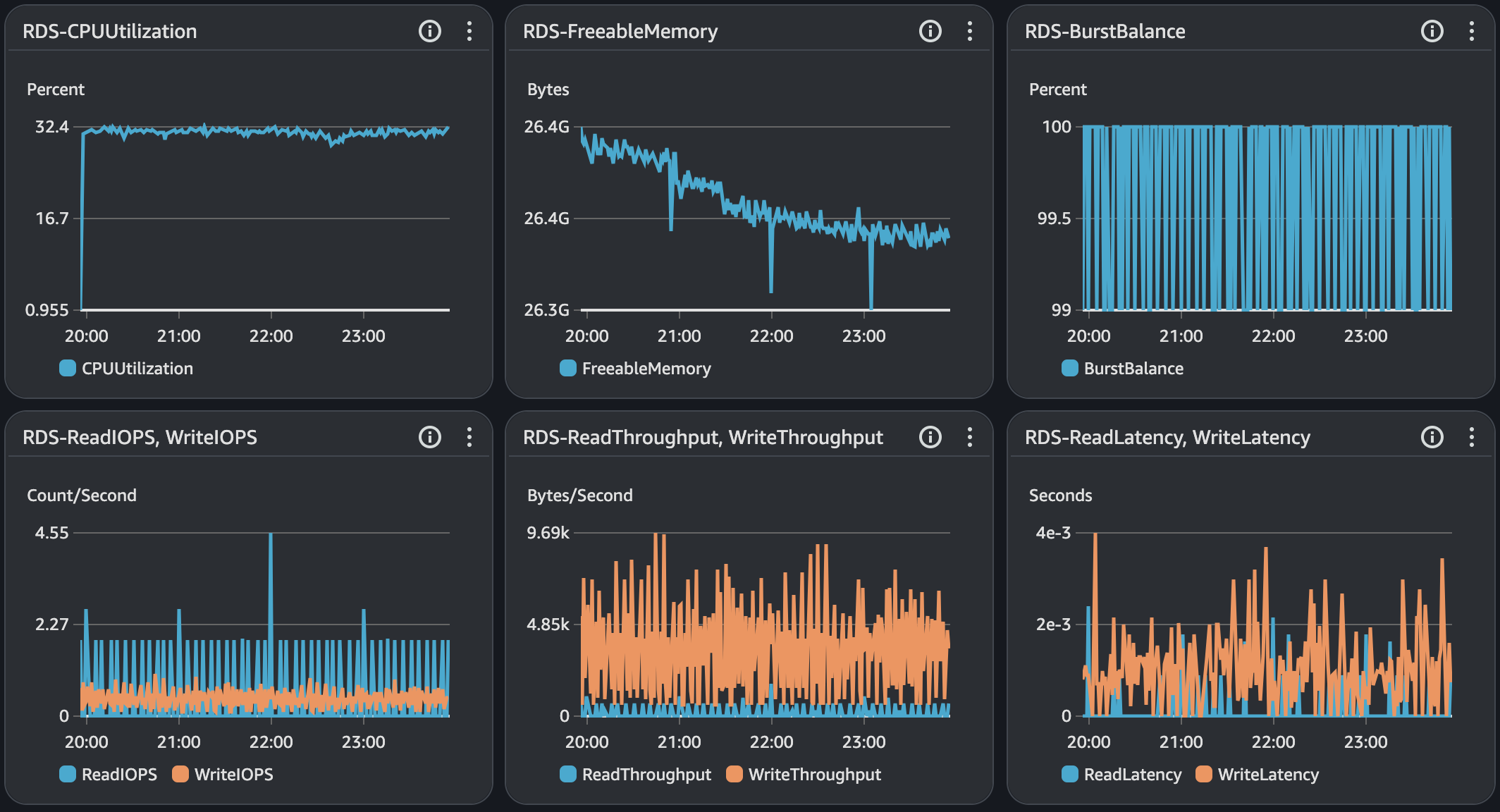
내구성 테스트 결과 분석
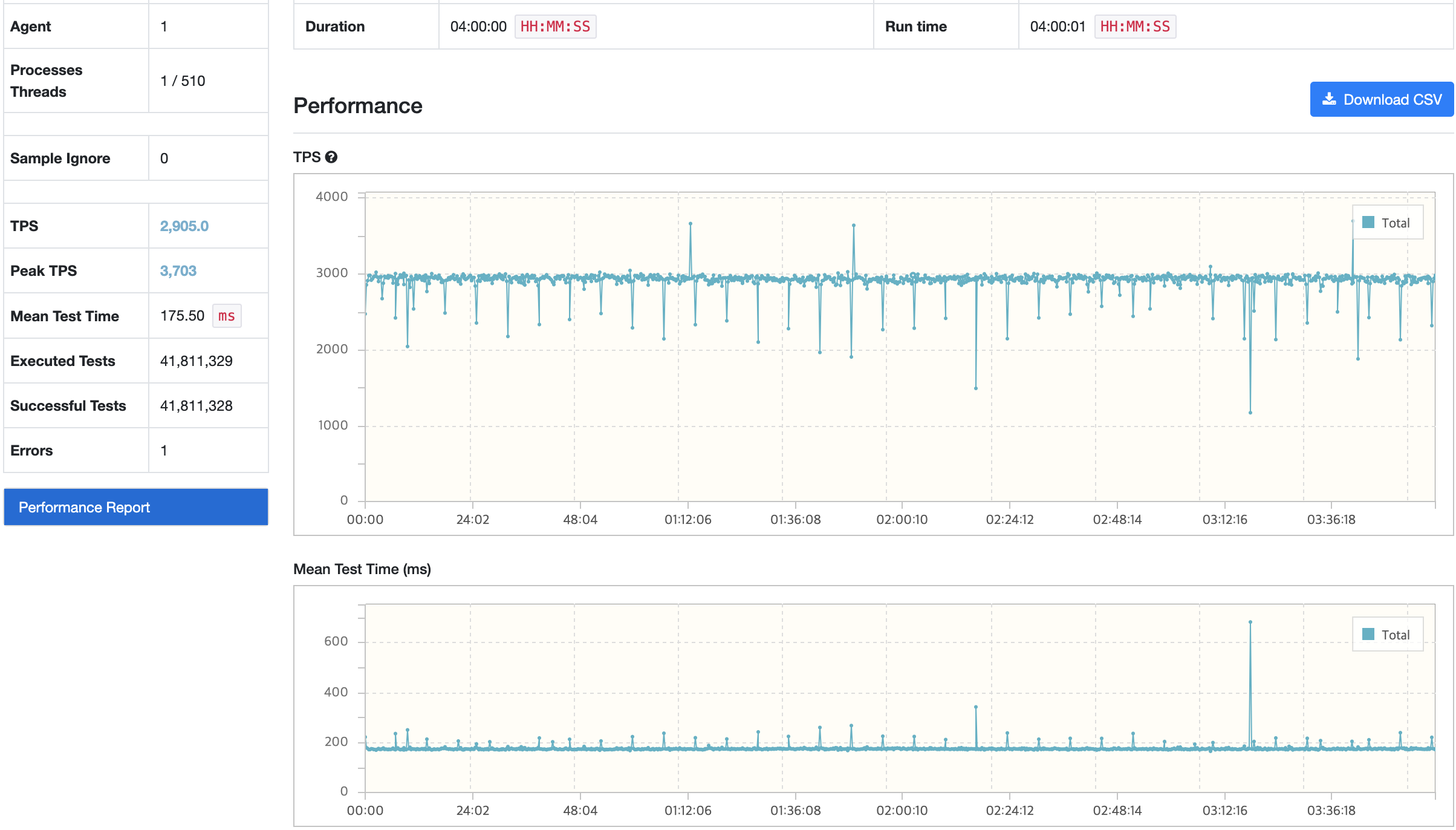
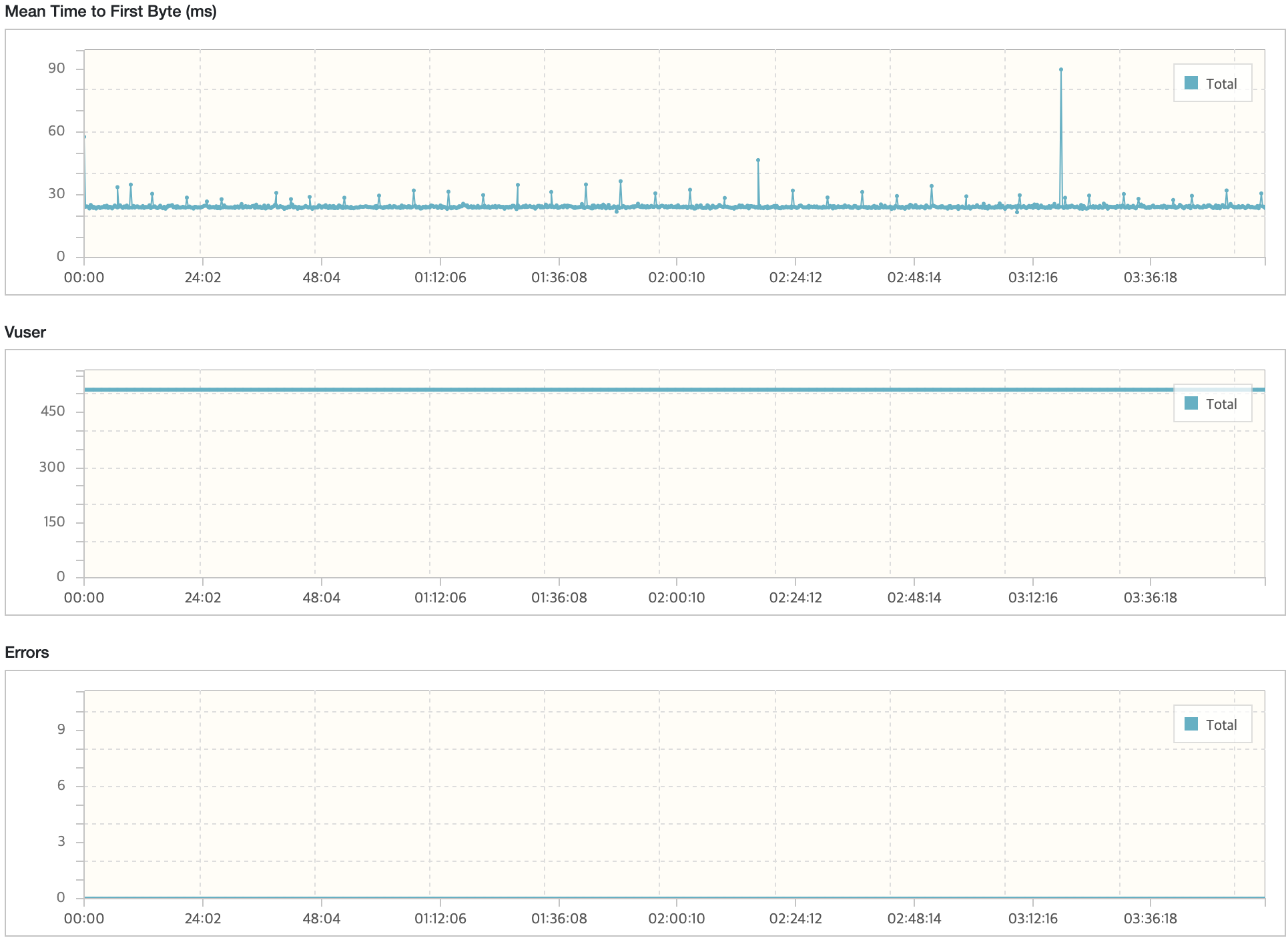
모든 시나리오에 대해서 내구성 테스트를 진행했을 때 목표 TPS, Response Time을 만족하고 있으며 에러 발생률도 0%에 가까운 수준이다.
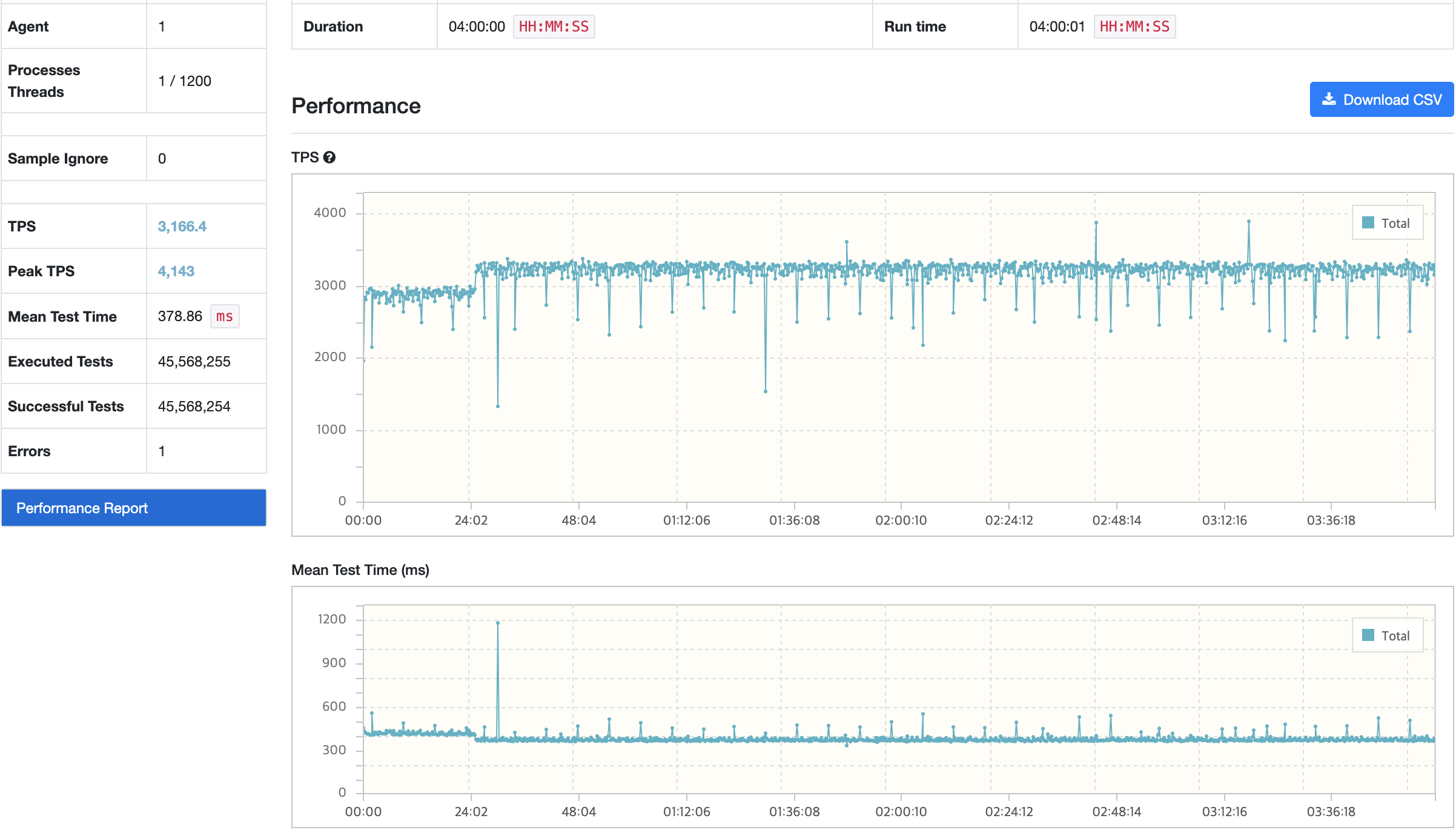
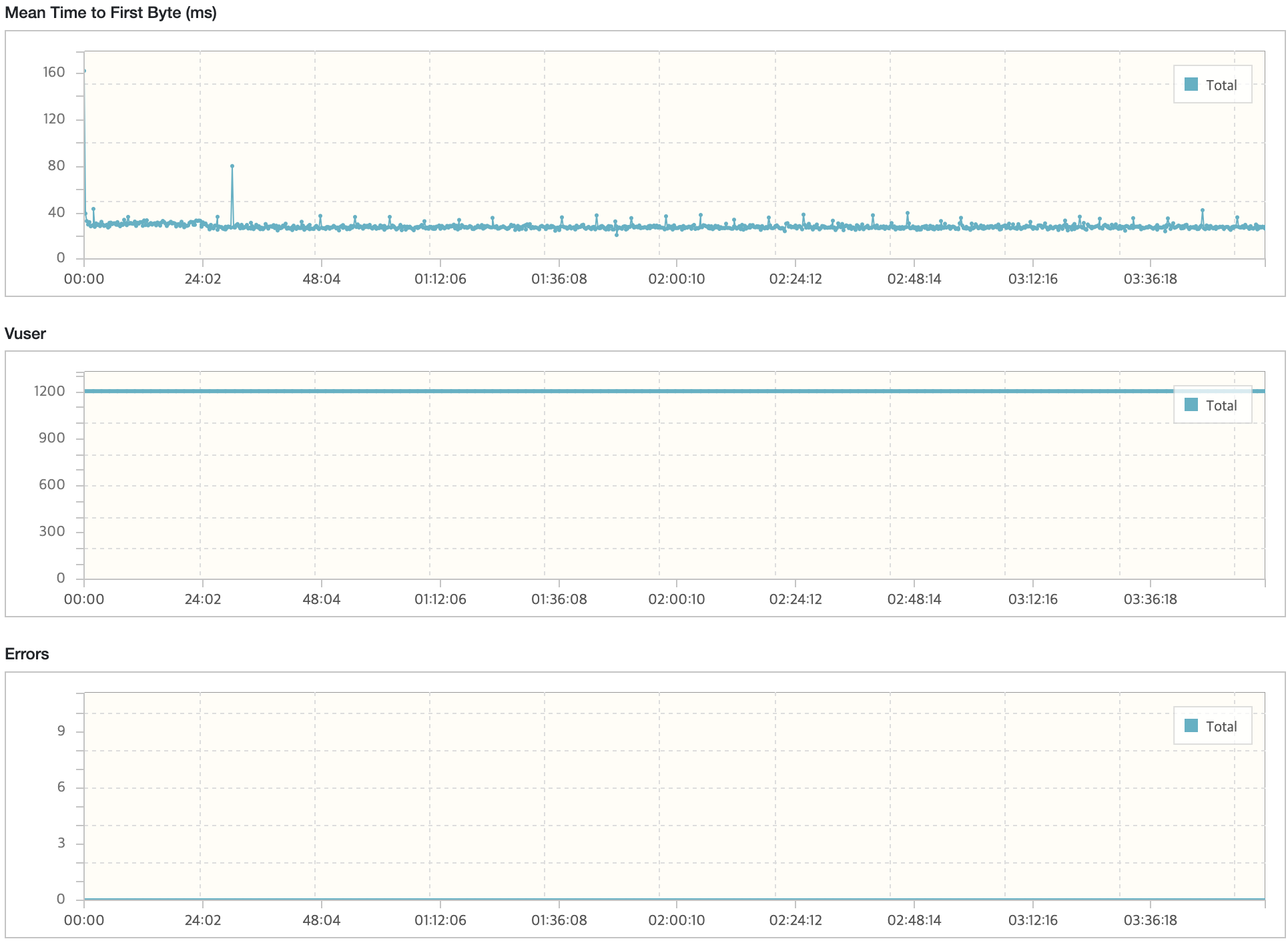
시나리오3에서 TPS가 감소하는 현상이 있지만 목표 TPS(40), 응답시간(500ms)를 만족하고 있다. 그렇지만, 시나리오1,2에 대해서는 TPS가 주기적으로 감소하는 현상이 발생하고 있다. 토큰 재발급으로 인해 테스트가 잠시 일시중지되어 TPS와 응답시간이 감소하는 부분이 있지만 포함되지 않는 시점에도 목표 수치를 만족하지 못하는 이슈가 있다.
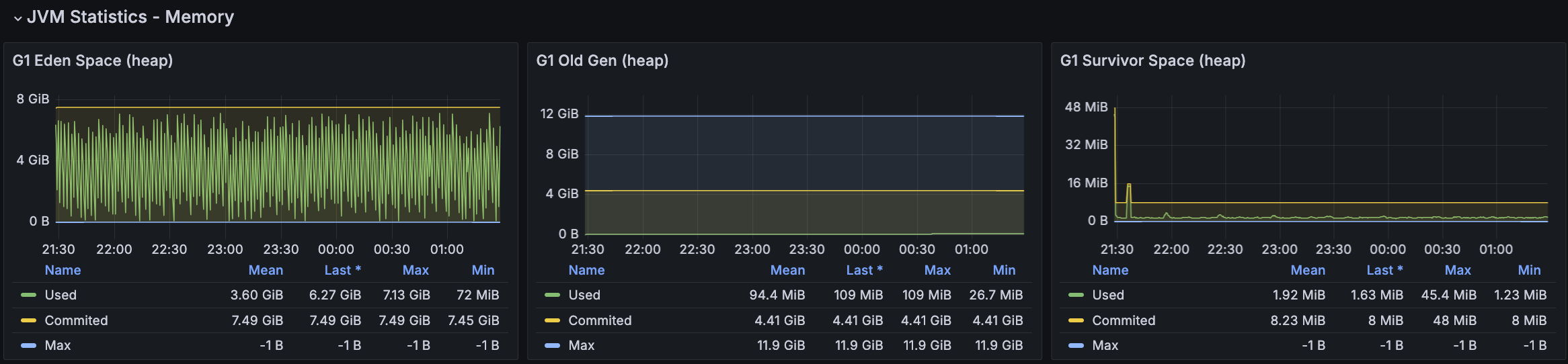
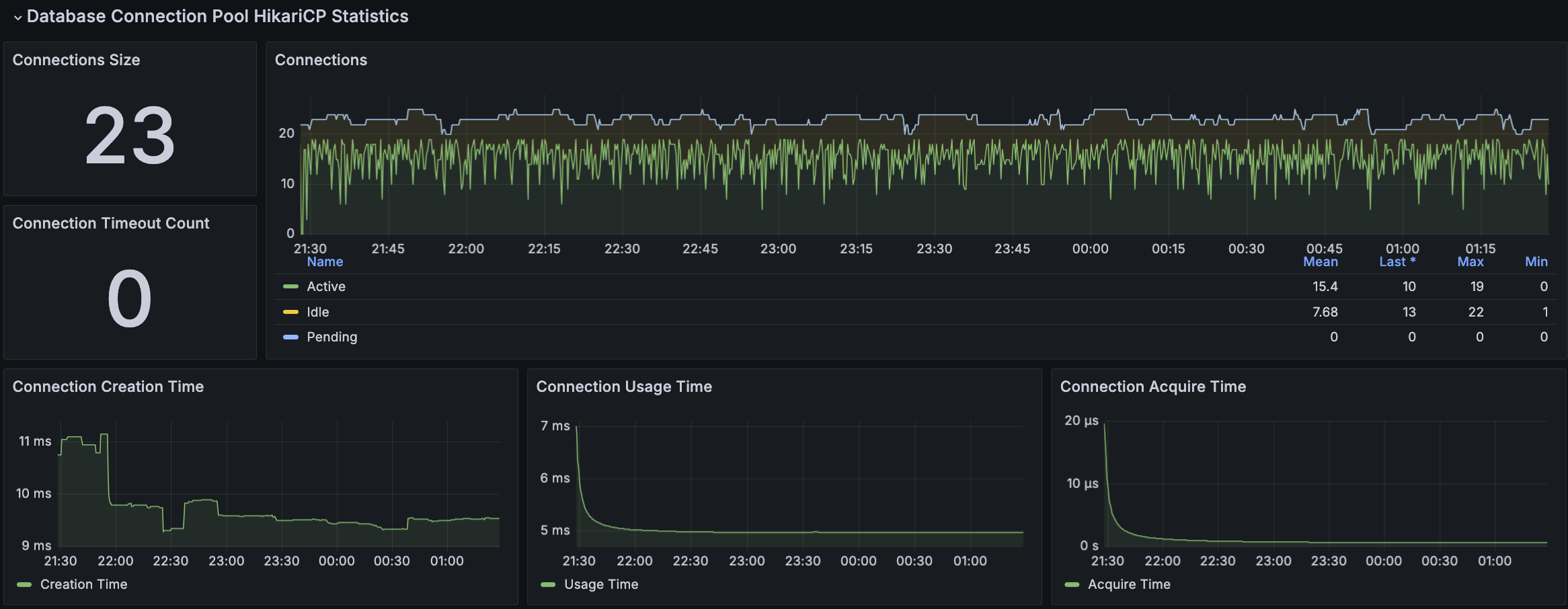
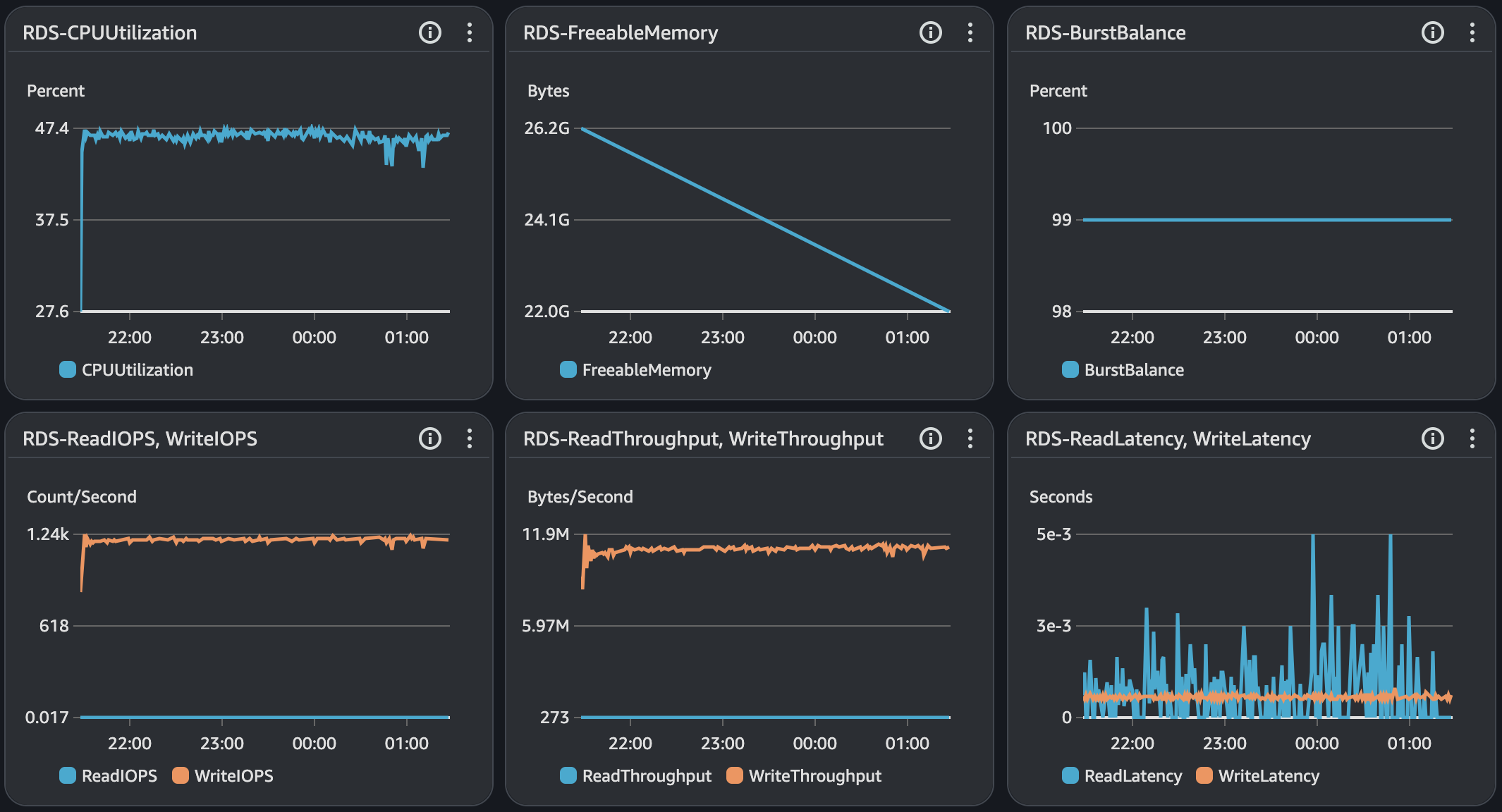
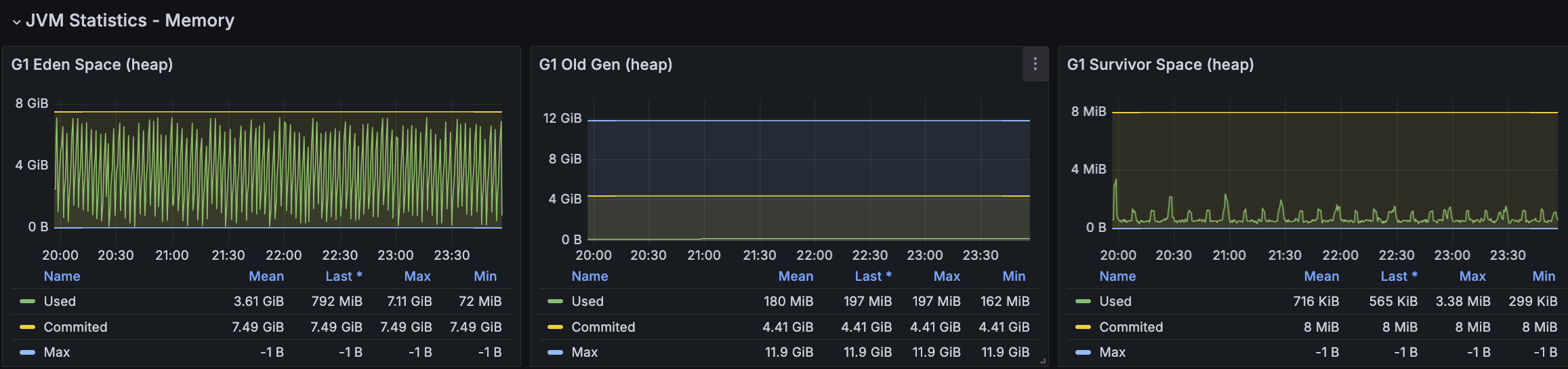
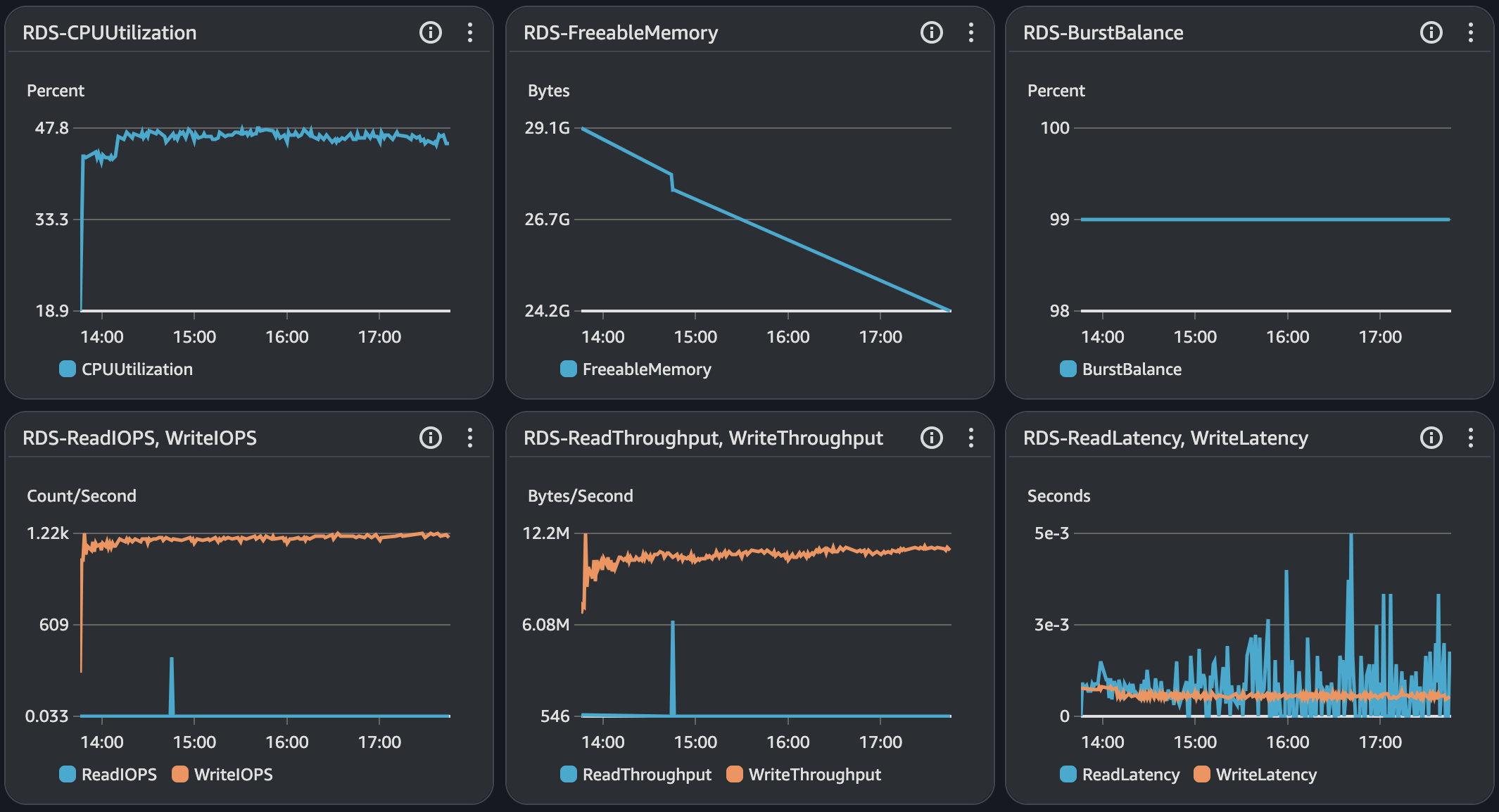
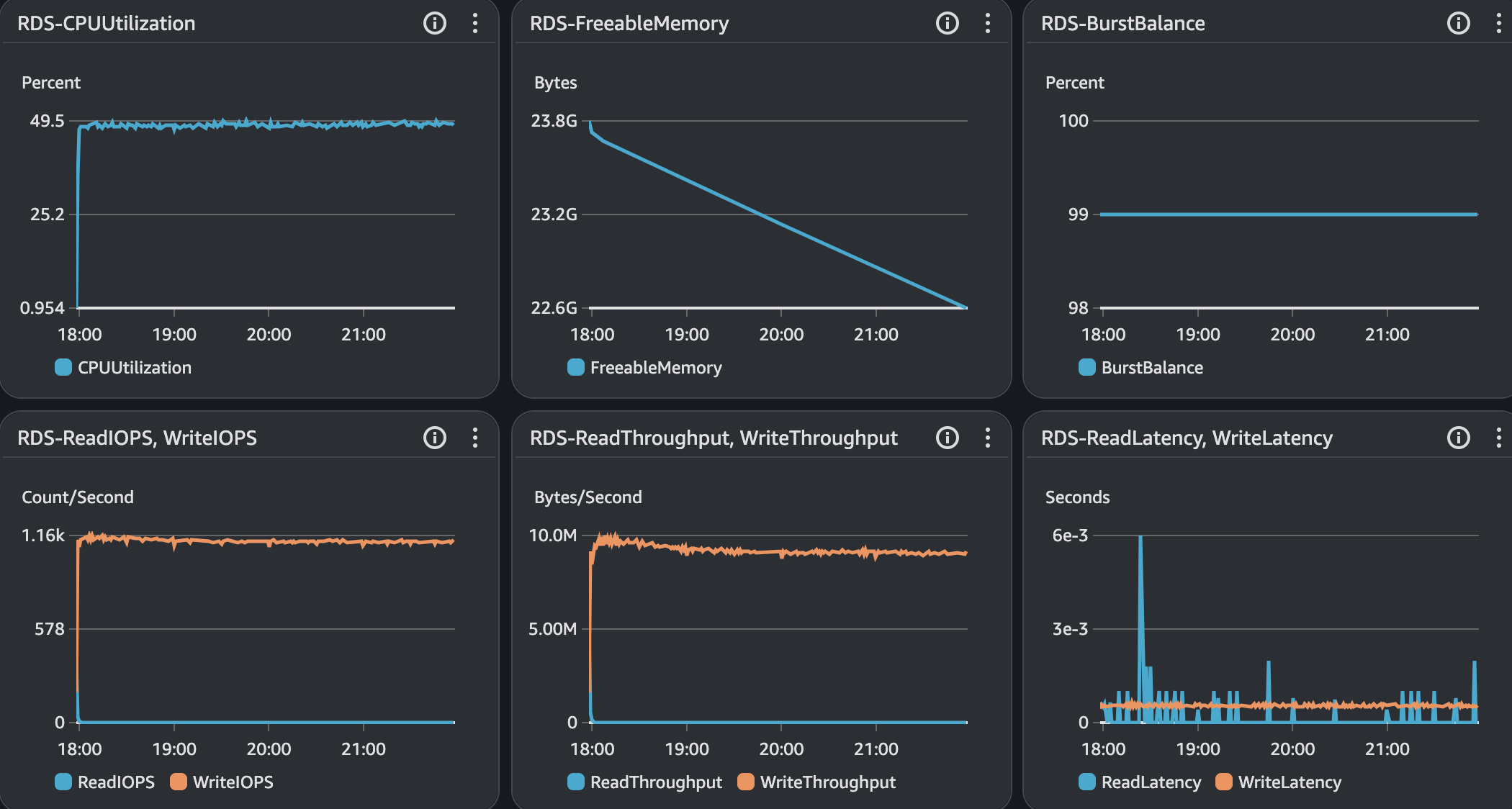
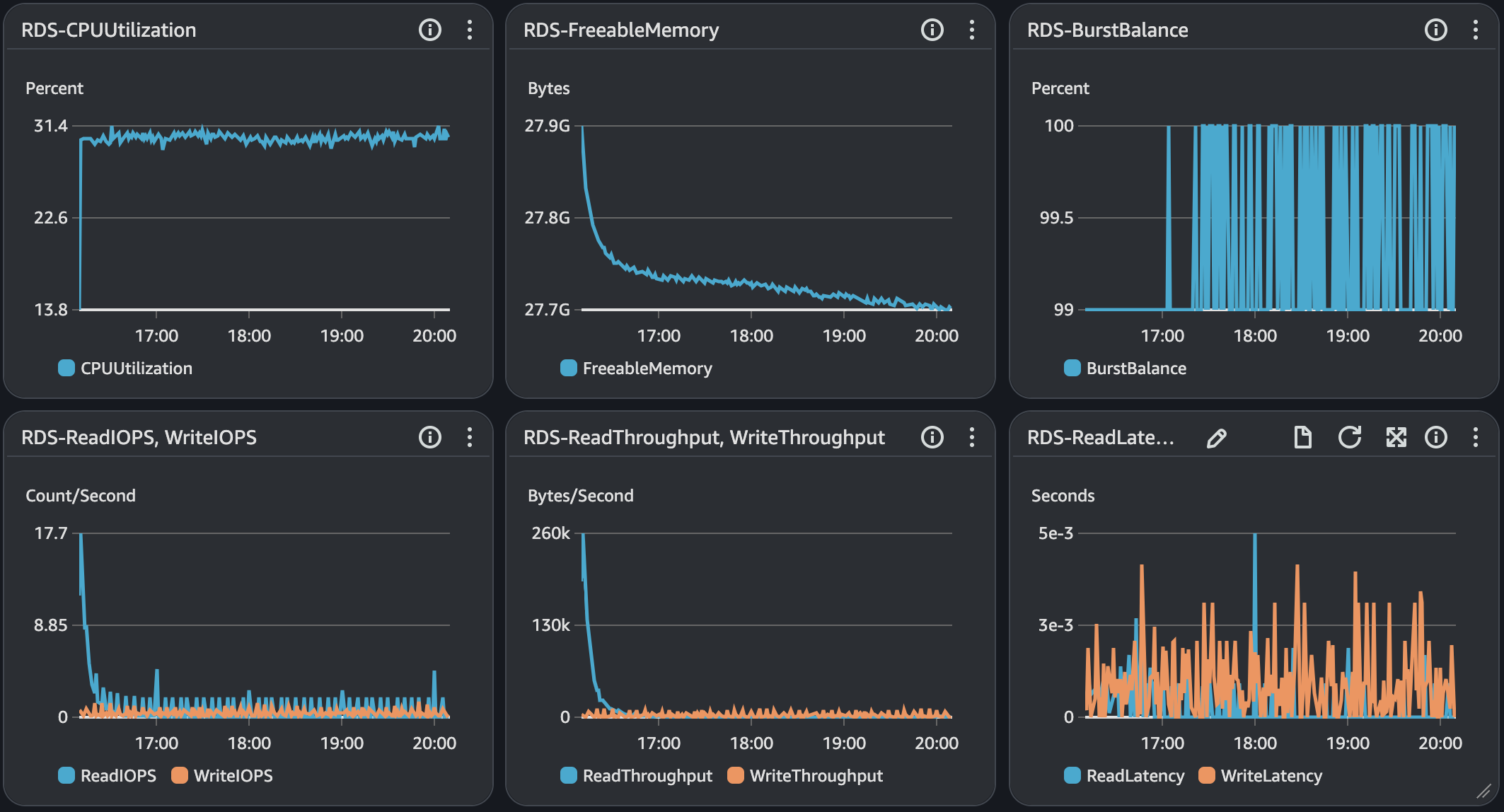
API 서버 및 DB 서버의 경우 CPU 부하가 과도하게 발생하지 않으며 Load Average는 할당된 만큼 사용률을 보인다. CPU 부하에 대해 찾아보면서 할당된 코어를 최소 70%의 사용률을 보이는 것이 안정적이다. 현재 서버의 기준으로 보면 5 ~ 7이다.
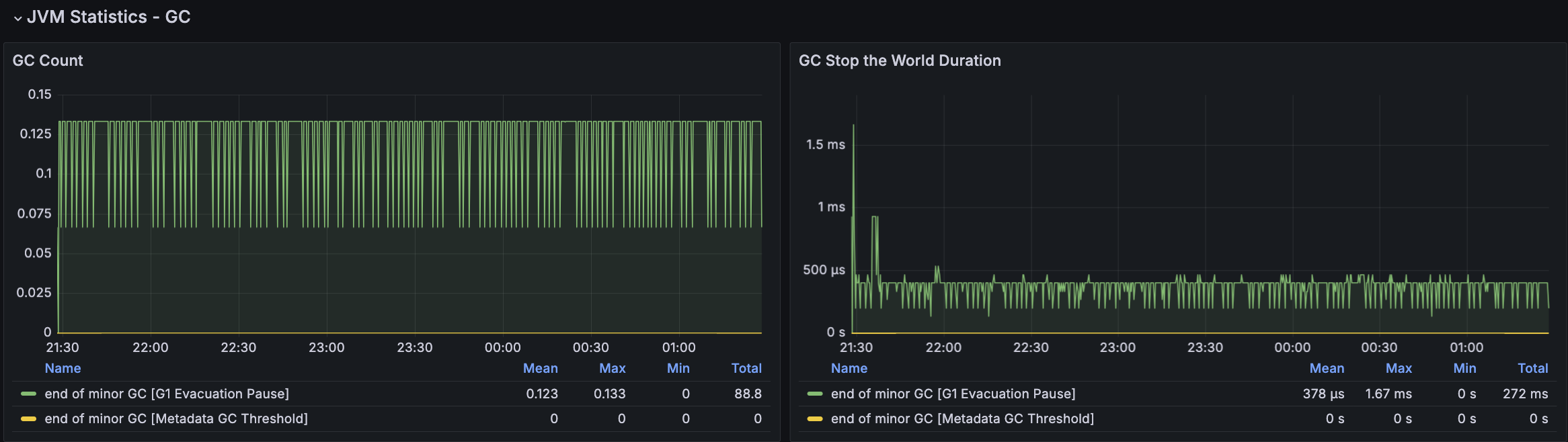
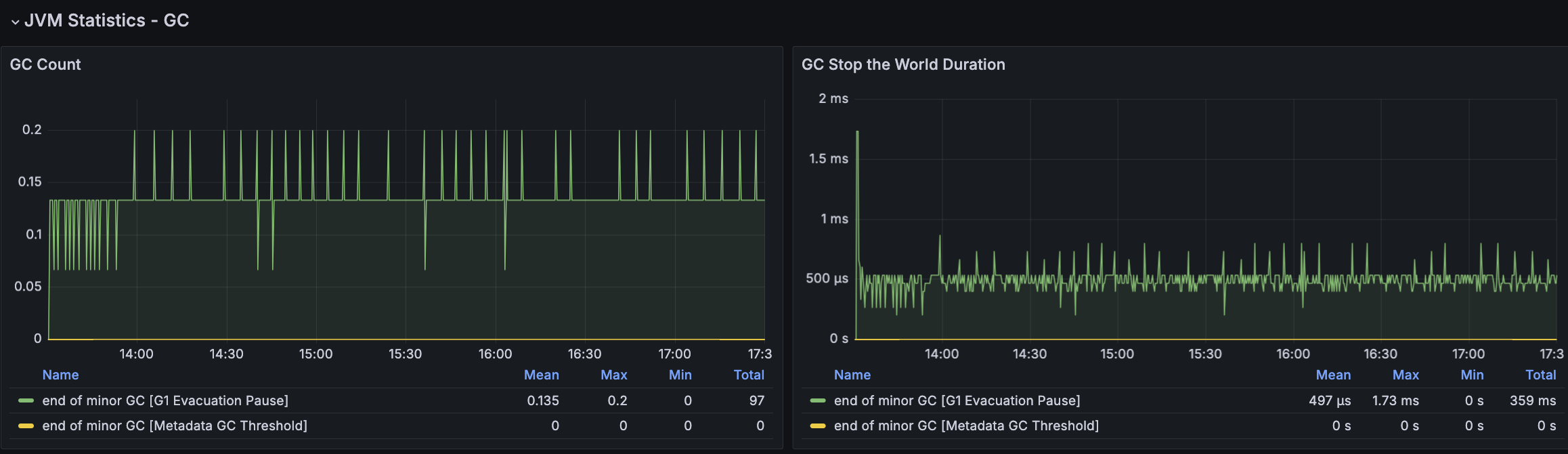
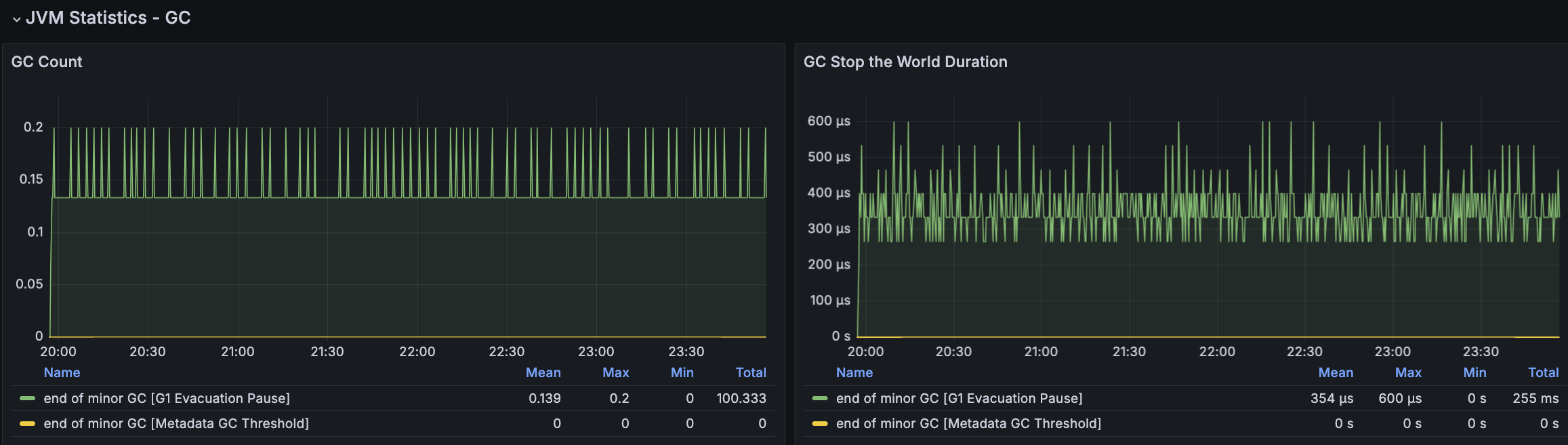
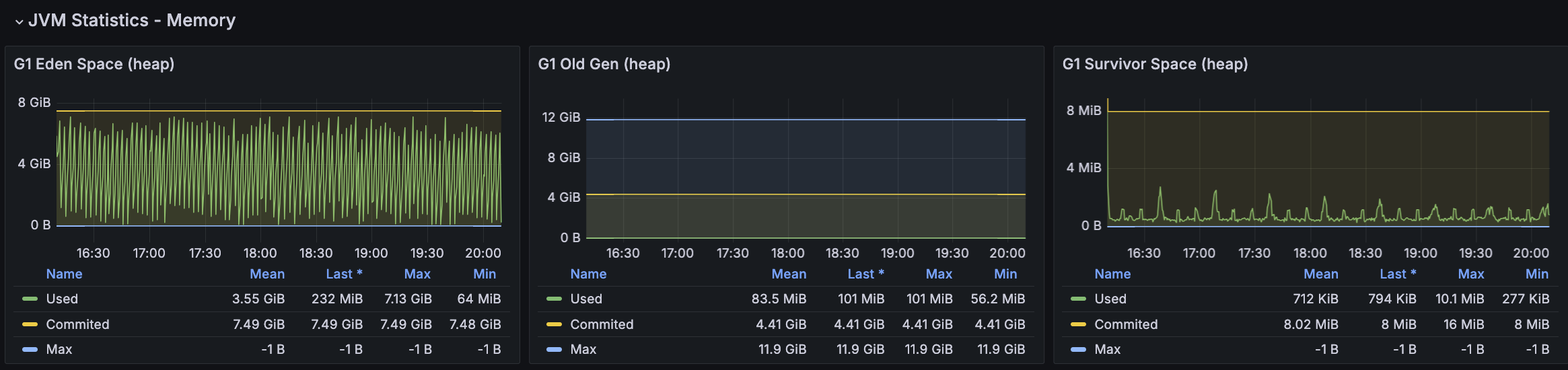
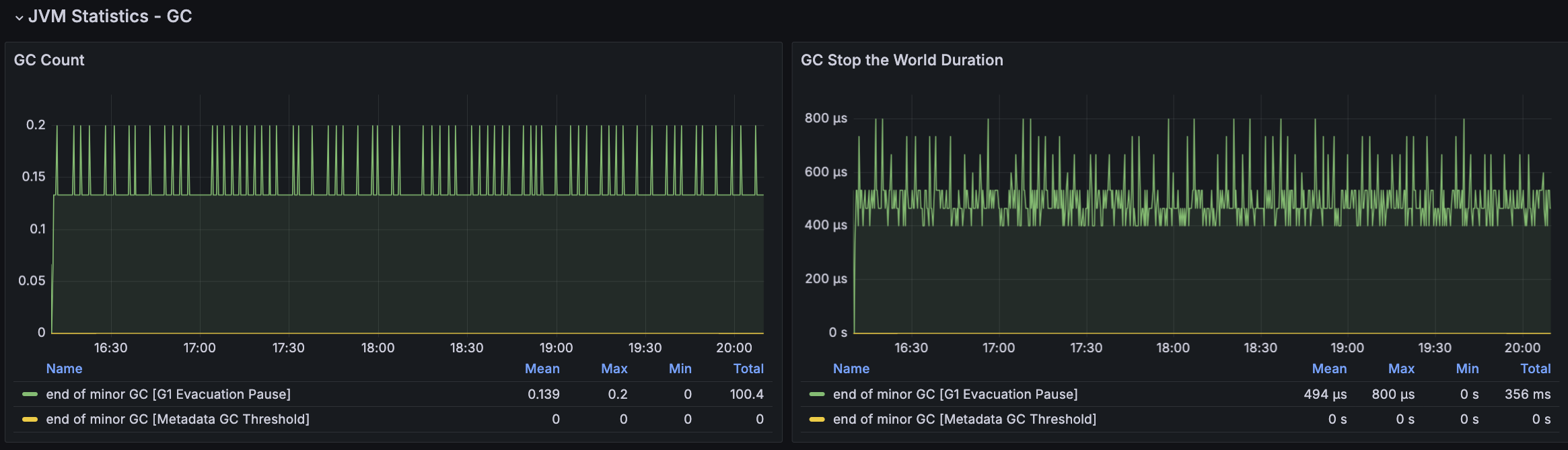
모든 시나리오에 대해서 평균 Load Average는 안정권에 들고있기에 서버 Scale Up/Out을 할 필요는 없어보인다. 다만, GC의 STW를 확인했을 때 주기적으로 증가하고 있으며 TPS가 감소와 STW 증가 주기가 비슷하다는 점에서 성능 개선 방안으로 GC 튜닝이 필요하다고 본다.
GC 튜닝
G1(Garbage First) GC
현재 시스템에서 사용중인 GC 알고리즘은 G1(Garbage First) GC이며, 튜닝에 필요한 옵션을 정리해보았다.
- G1HeapRegionSize : G1 GC에 사용되는 Heap 영역의 Region 크기를 설정한다.
- 기본적으로는 JVM은 최대 Heap 사이즈의 1/2048 만큼의 계산된 사이즈를 지정한다.
- 직접 설정을 할 경우 1 ~ 32MB 정도로 설정할 수 있으며, 2의 거듭제곱 값이여야 한다.
- Region Size가 증가되면 GC 작업의 시간이 길어질 수 있다.
- ParallelGCThreads : GC 발생시 병렬 작업에 사용되는 스레드 수를 설정한다.
- 사용 가능한 CPU 프로세스 수가 8 이하이면 해당 프로세스 수를 설정하며 초과하는 경우 5/8로 설정한다.
- ConcGCThreads : 동시 GC 작업에 사용되는 스레드 수를 설정한다.
- 동시 GC 작업 값은
ParallelGCThreads값을 4로 나눈 값이로 설정한다.
- 동시 GC 작업 값은
- G1HeapWastePercent : 얼마나 많은 Region이 낭비되어도 가능한지를 결정한다. Heap을 낭비해도 좋다고 판단하는 값이며 Mixed cycle의 종료 시점을 결정한다. (default: 5)
- 값이 클수록 Mixed GC 빈도가 감소하여 GC의 효율성이 좋아지나 Full GC의 위험성이 증가한다.
- 값이 작을수록 Mixed GC 빈도가 증가하여 메모리 효율성 증가하나 GC의 오버헤드가 증가한다.
- G1MixedGCCountTarget : 한번의 Mixed GC 때 처리할 Region의 개수이며, 값이 적을 수록 Mixed GC가 여러 주기에 거쳐 가비지를 수거하므로 중단 시간은 길어지나 빠르게 Region를 비워주는 이점이 있다. (default: 8)
- 값이 클수록 한 번의 Mixed GC에서 적은 Region을 회수하여 GC Pause Time이 감소하나 Old Generation 영역 처리가 느리다.
- 값이 작을수록 한 번의 Mixed GC에서 많은 Region을 회수하여 GC Pause Time이 증가하나 Old Generation 영역 처리가 빠르다.
- G1ReservePercent : Heap 메모리의 일정 비율을 예약하여, Heap 메모리가 부족해지는 상황을 미리 방지하여 Full GC 발생 가능성을 줄인다. (default: 10)
- 너무 높은 값으로 설정하면 실제 사용 가능한 힙 메모리가 줄어들어 오히려 성능 저하가 발생할 수 있습니다
- TargetSurvivorRatio : Survivor 영역에 남아있는 객체의 목표 비율을 설정한다.
- Survivor 영역이 차게 되면 Old Generation으로 승격되는데 이 영역이 모두 차지 않도록 GC의 동작 시점을 조정하기 위해 설정한다.
- InitiatingHeapOccupancyPercent : G1 GC에서 Concurrent Marking 사이클을 시작하기 위한 Heap 점유율 임계값을 설정한다. (default: 45)
- 값이 너무 작으면 GC가 너무 자주 발생하여 오버헤드가 증가하고 애플리케이션 성능이 저하될 수 있다.
- 값이 너무 크면 GC 사이클이 늦어져 Full GC 발생 가능성이 높아지고, GC 지연 시간이 길어질 수 있다.
- UseStringDeduplication : Heap에 동일한 내용을 가진 문자열 객체가 여러 개 존재할 경우, String Deduplication을 통해 메모리를 공유하도록 중복 문자열을 제거하여 메모리 사용률을 줄인다.
첫 번째 GC 튜닝 및 테스트
- G1HeapRegionSize : 8M (자동설정)
- G1ReservePercent : 10 (기본값)
- G1HeapWastePercent : 5 (기본값)
- G1MixedGCCountTarget : 8 (기본값)
- UseStringDeduplication : 고정
- ParallelGCThreads : 6 (고정)
- ConcGCThreads : 2 (고정)
- InitiatingHeapOccupancyPercent : 60 → GC 발생률 감소를 위해 증가
- TargetSurvivorRatio : 70 → Survivor 영역을 더 활성화하여 GC 발생률 감소를 위해 증가
첫 번째 튜닝 후 간략 테스트 결과 및 분석
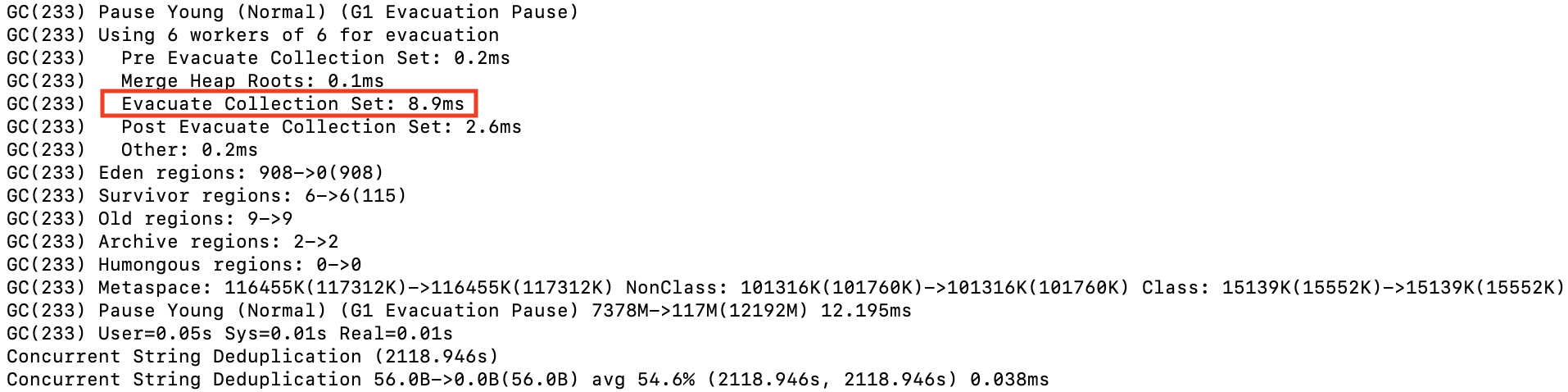
첫 튜닝은 GC 발생률을 낮추어보려 했지만 TPS가 감소하는 현상은 여전히 있었다. 해당 시점에 GC 로그를 확인해보니 아래와 같이 Mixed GC에 연관있는 Collection Set(수집대상 Region 집합)의 소요 시간이 크게 증가하고 있었다.
두 번째 GC 튜닝 및 테스트
- G1MixedGCCountTarget : 8 → 12
- InitiatingHeapOccupancyPercent : 60 → 45
Mixed GC로 인한 STW를 줄이기 위해 G1MixedGCCountTarget값을 늘려 보았다. G1HeapWastePercent 또한 Mixed GC 빈도에 영향이 있으나 Full GC의 위험성으로 기본값 5를 유지했다.
InitiatingHeapOccupancyPercent의 경우 값이 커질수록 GC 지연 시간이 길어진다는 점에서 기본값으로 변경하였다.
두 번째 튜닝 후 간략 테스트 결과 및 분석
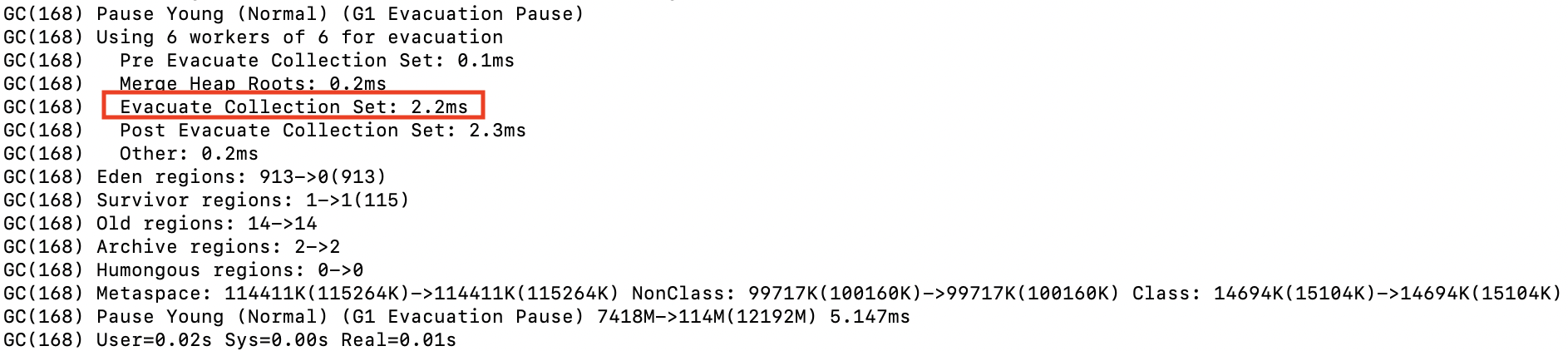
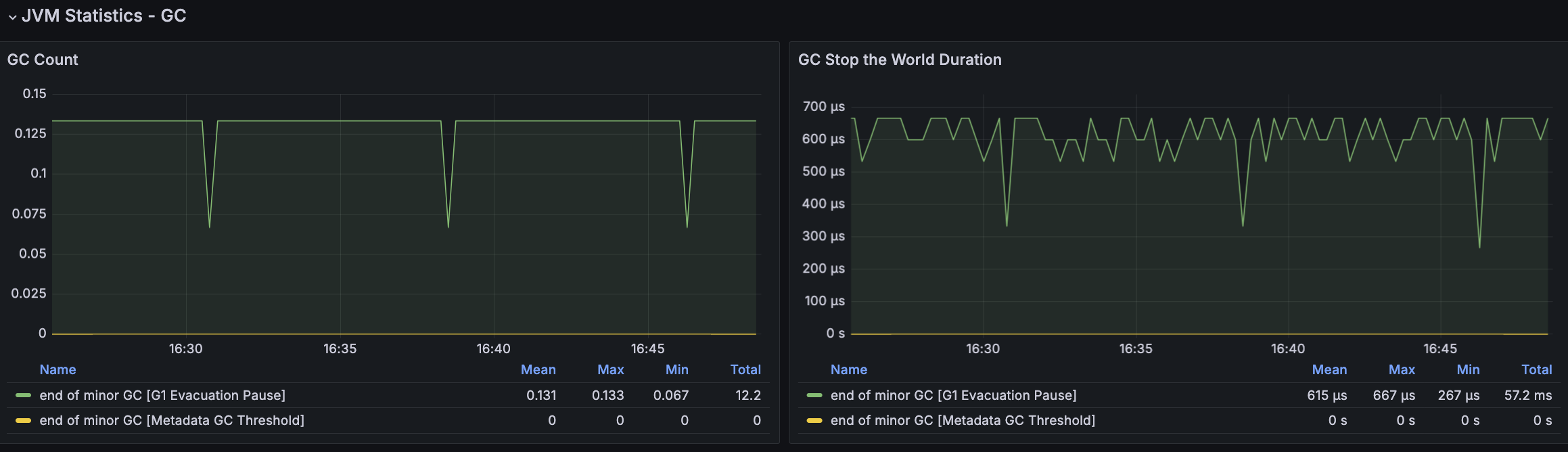
Collection Set(수집대상 Region 집합)에 대한 높아도 약 2ms 정도로 유지되었고 STW가 주기적으로 증가하는 현상도 없어졌으나, TPS가 주기적으로 급격히 감소되는 현상은 유지되고 있었다.
GC 튜닝 후 내구성 테스트
시나리오1
nGrinder
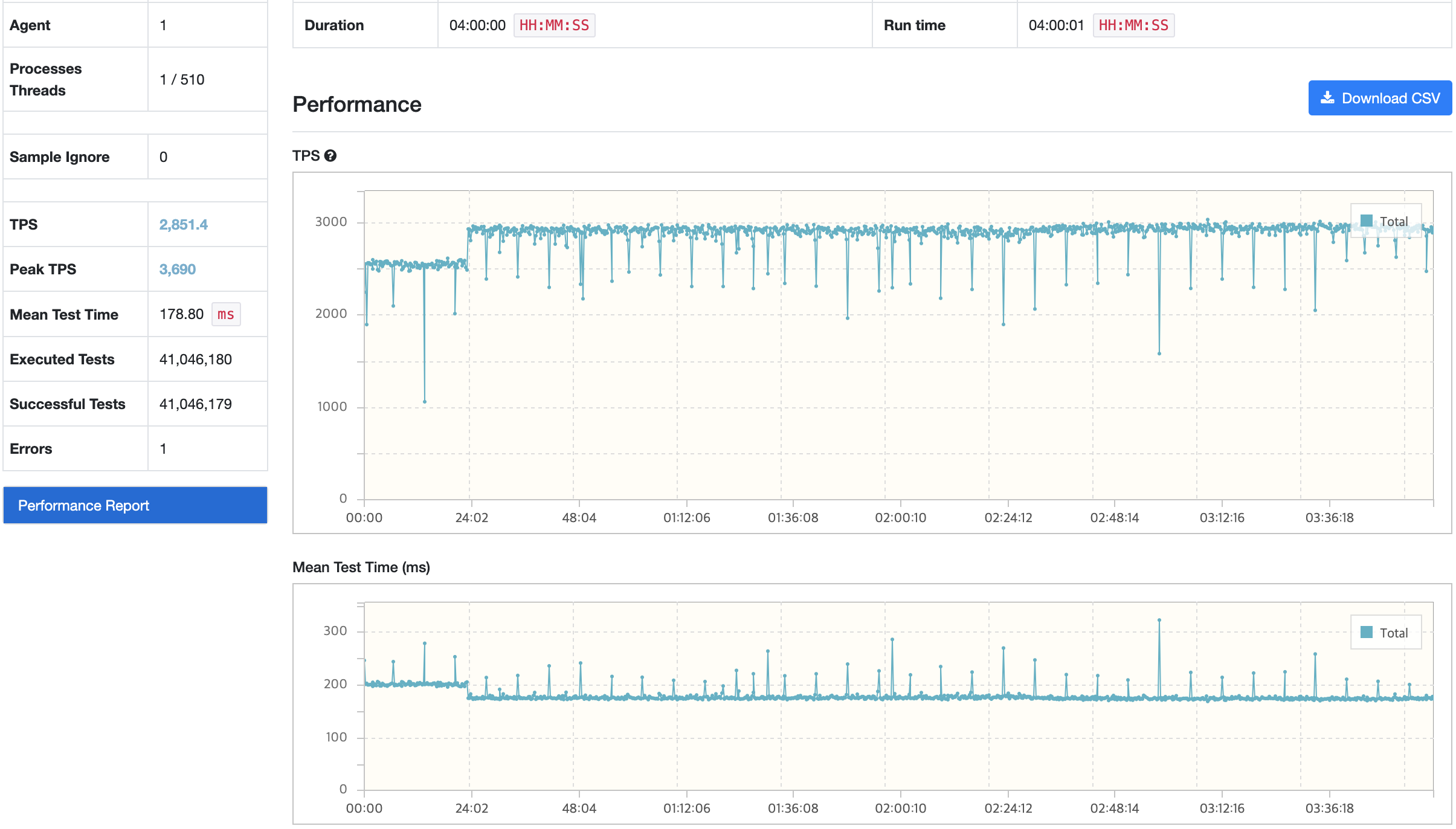
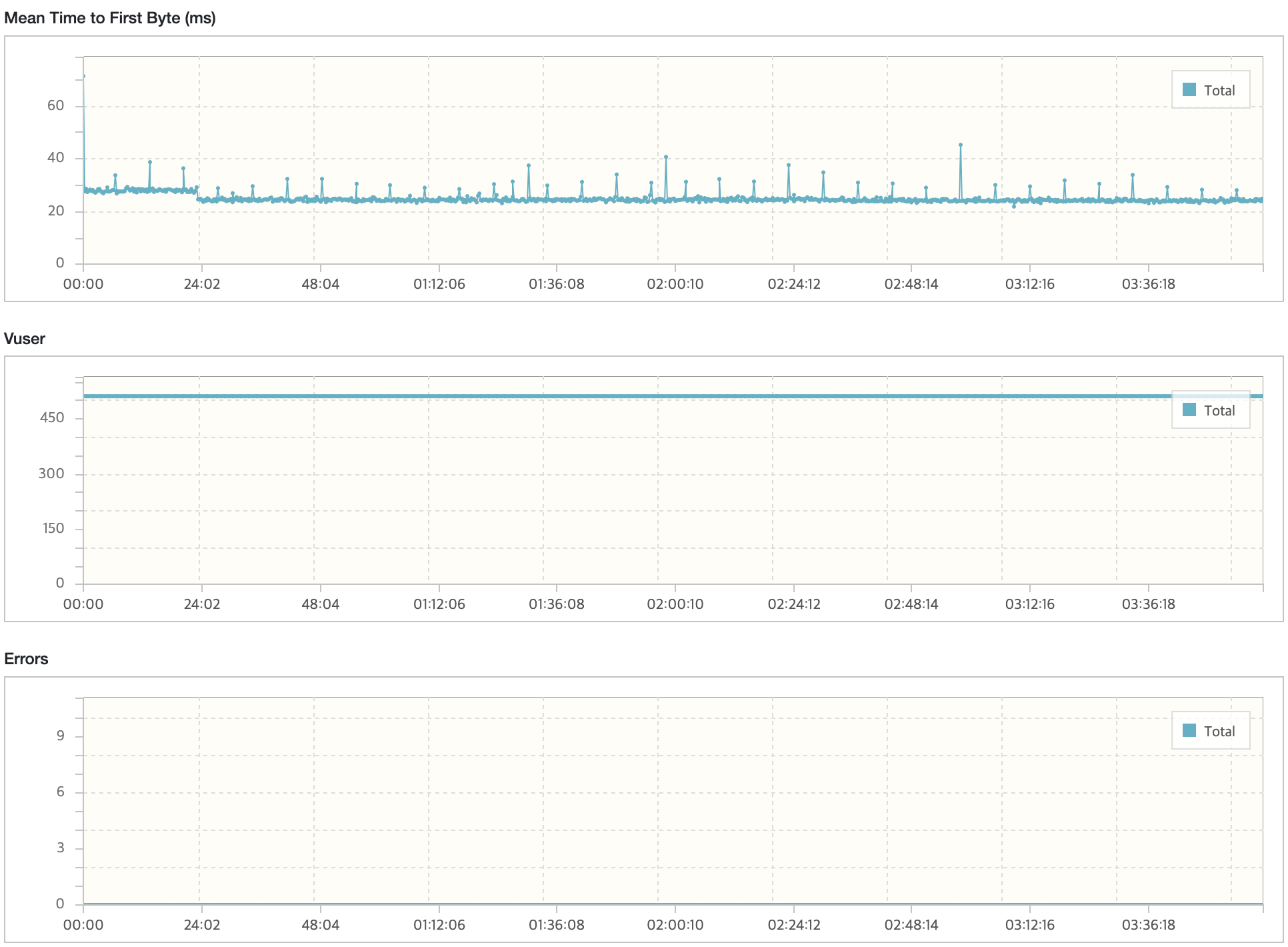
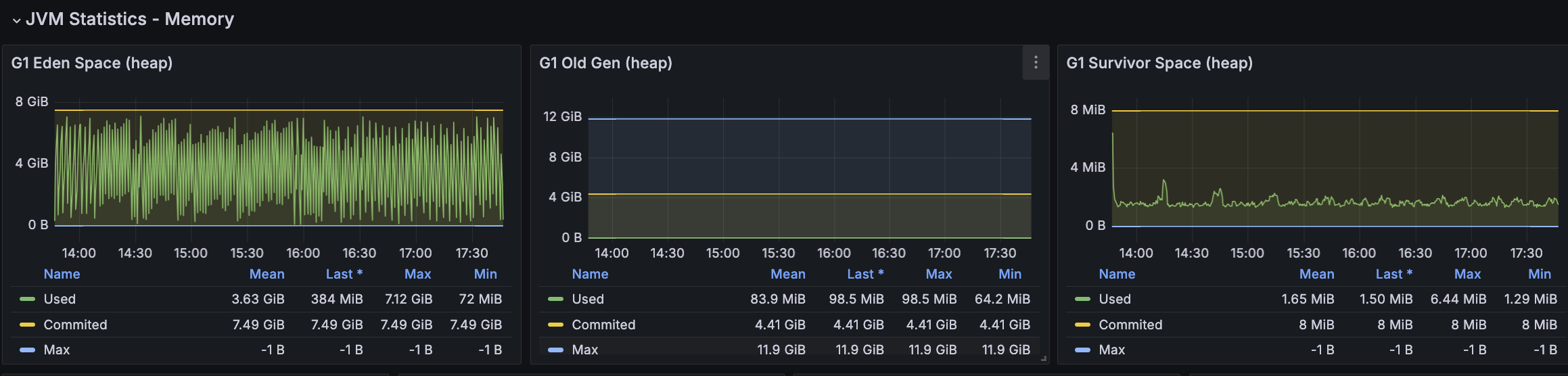
API 서버

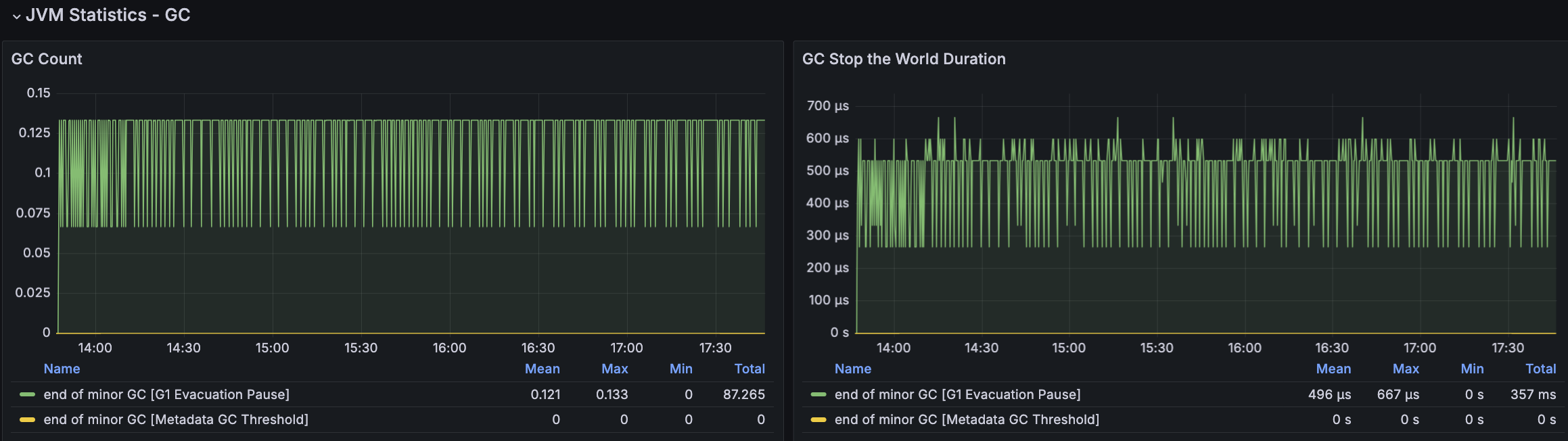
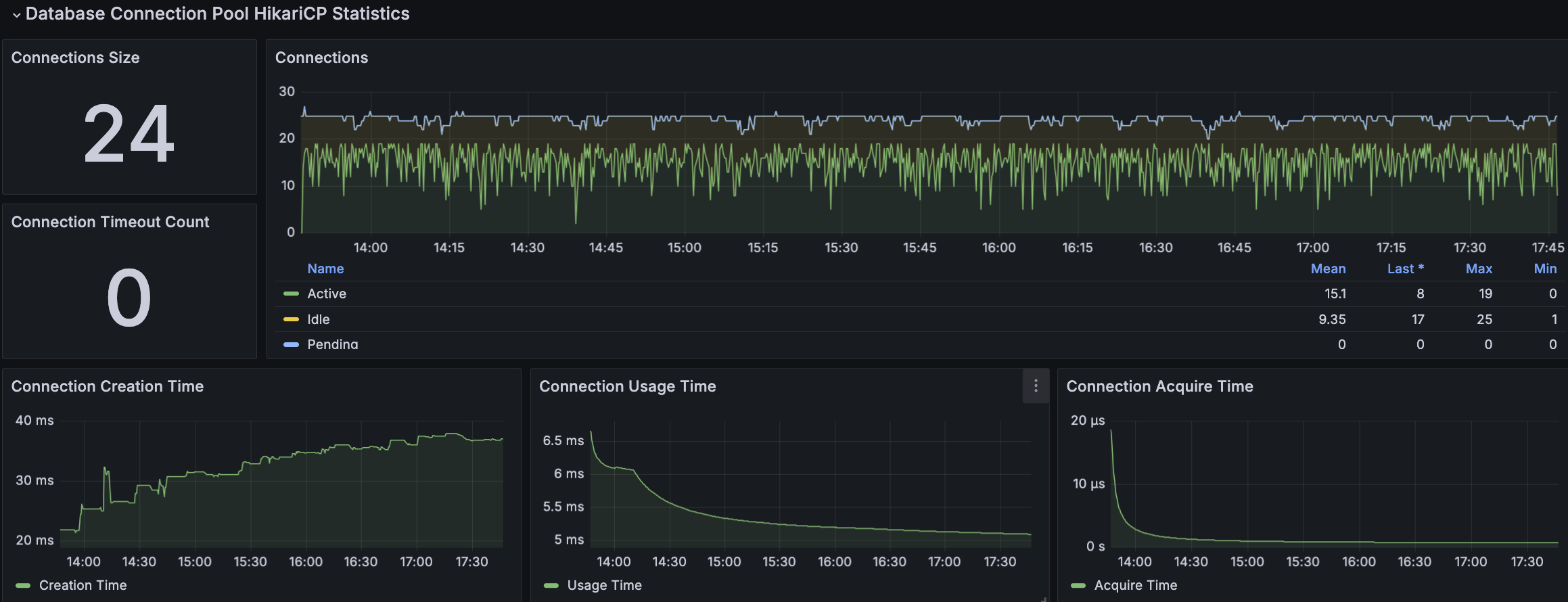
RDS - MySQL
시나리오2
nGrinder
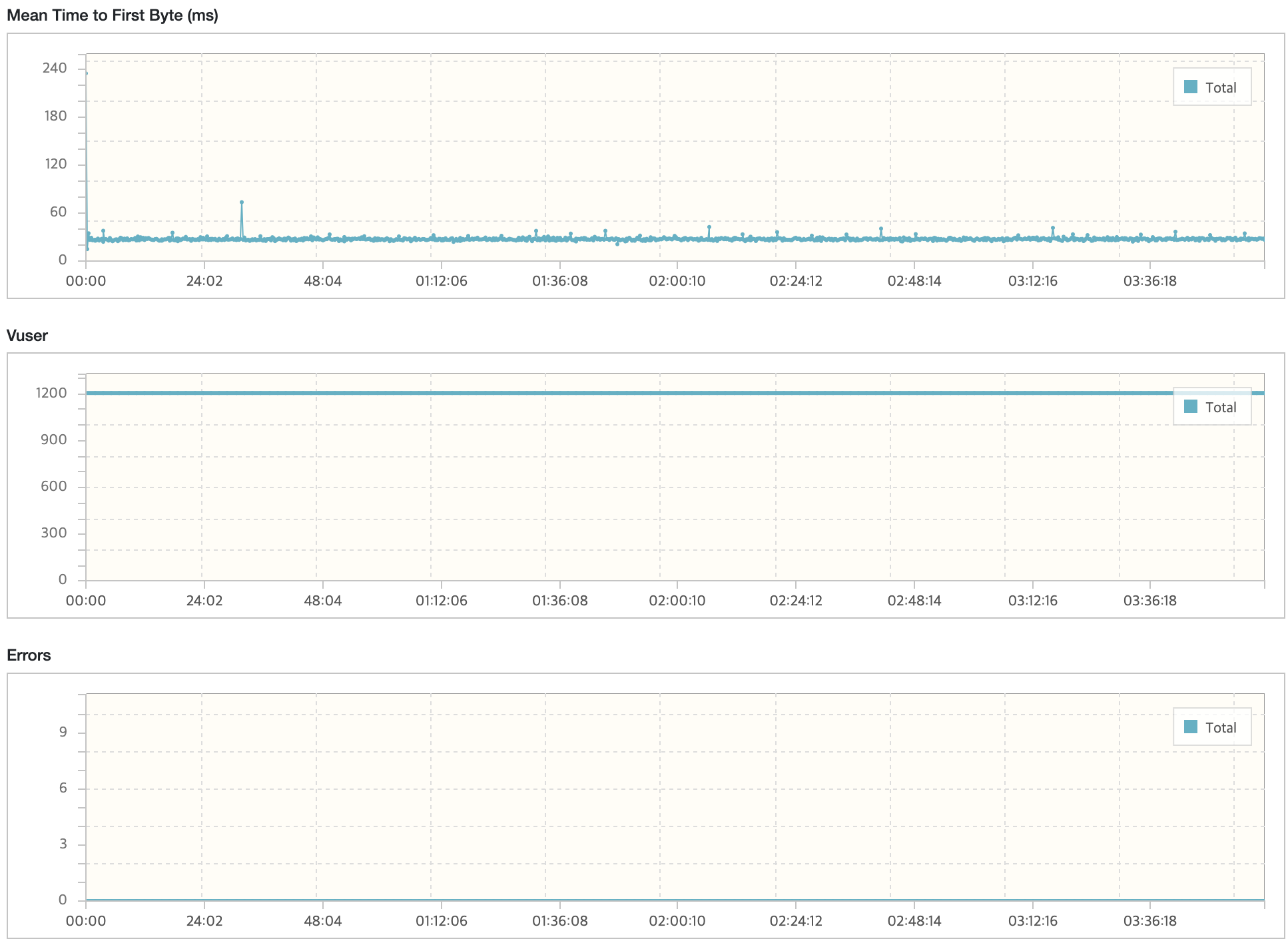
API 서버

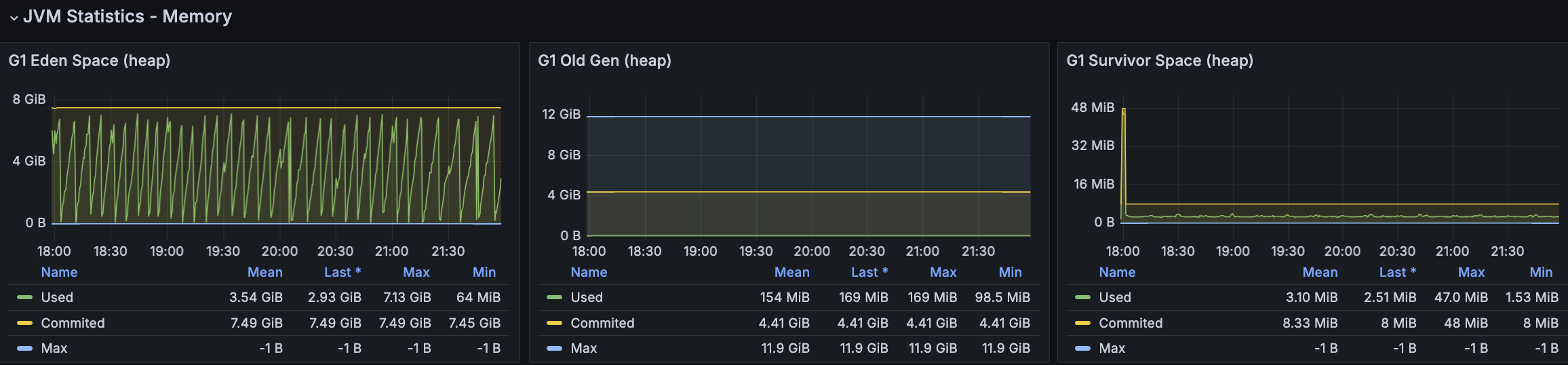
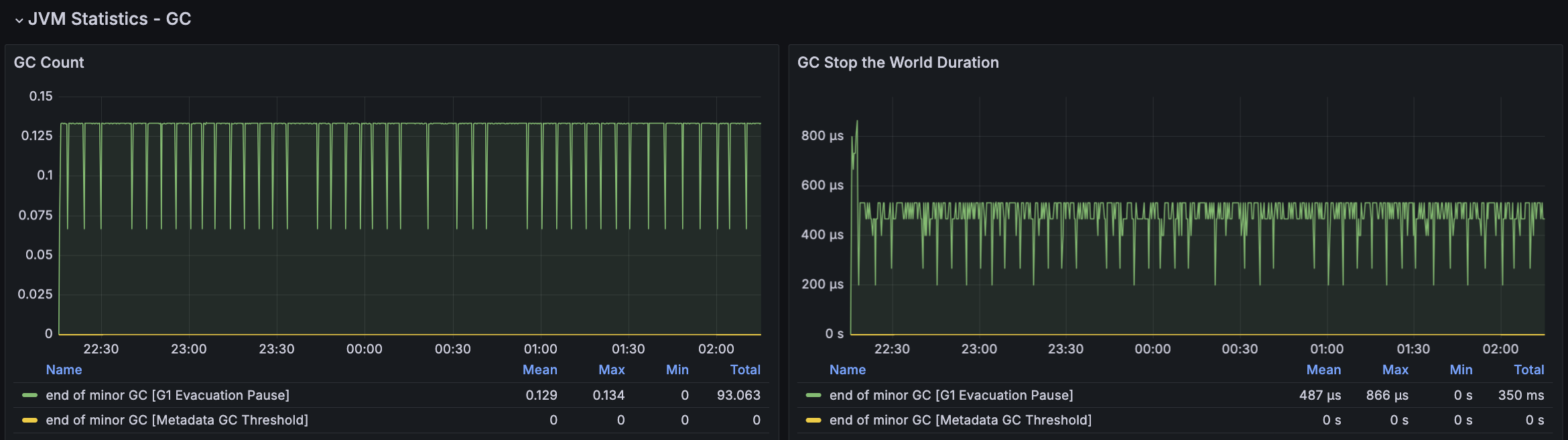
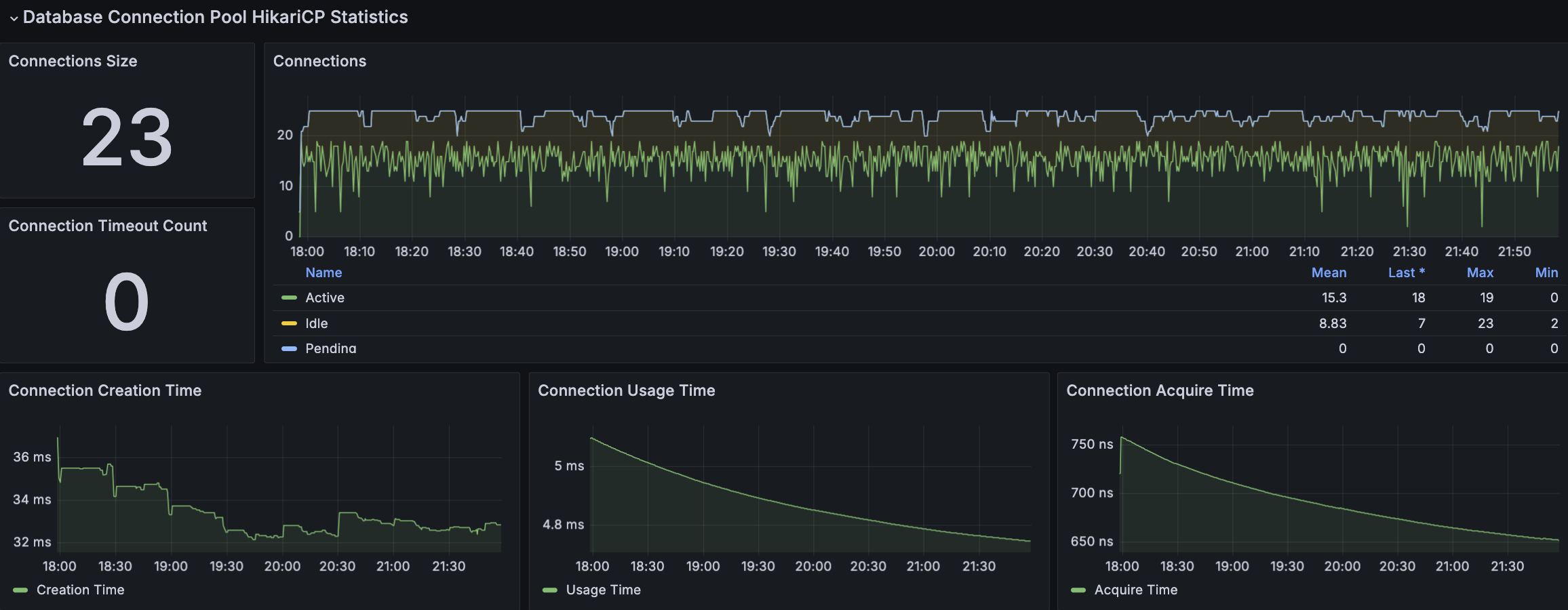
RDS - MySQL
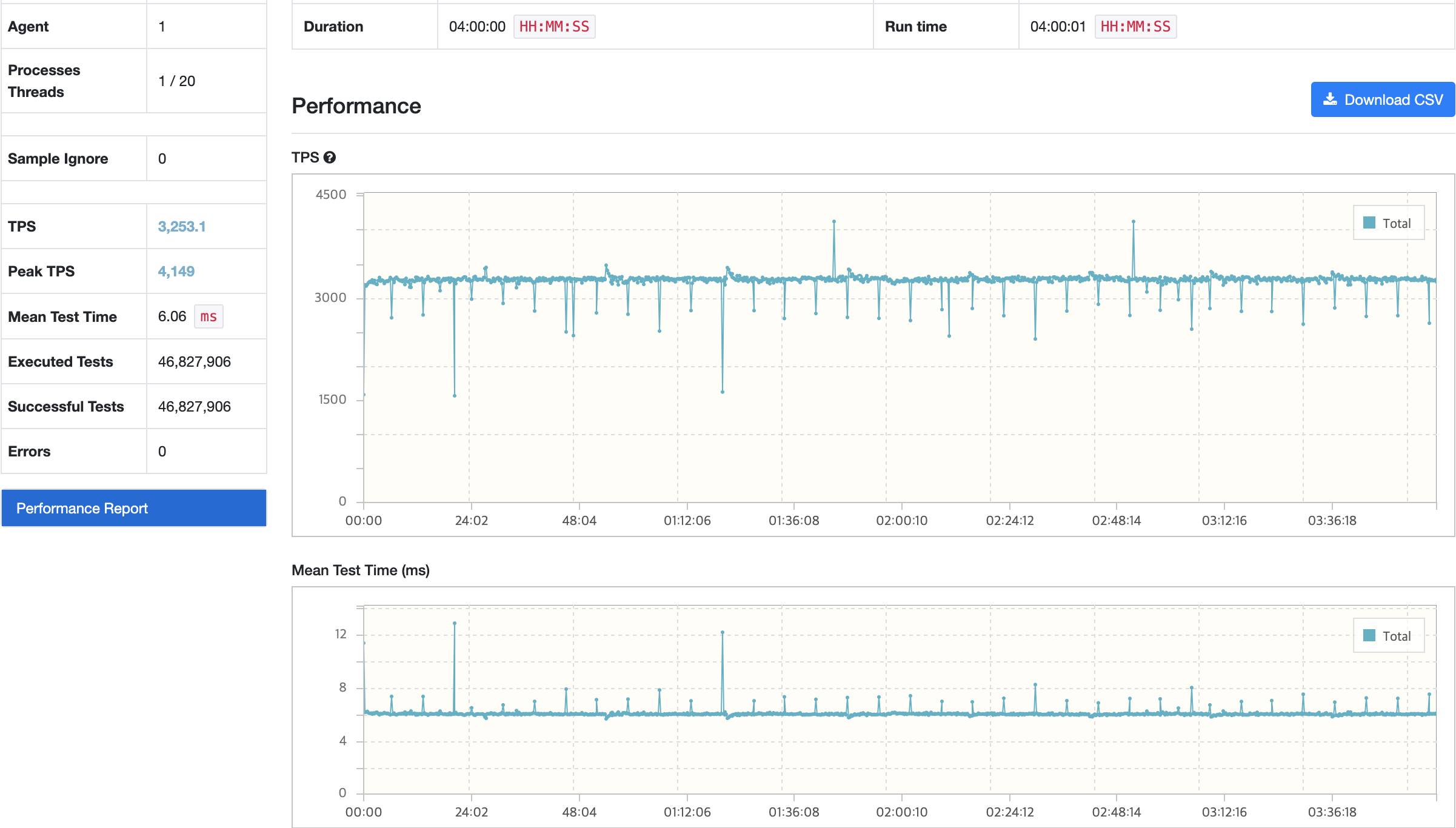
시나리오3
nGrinder
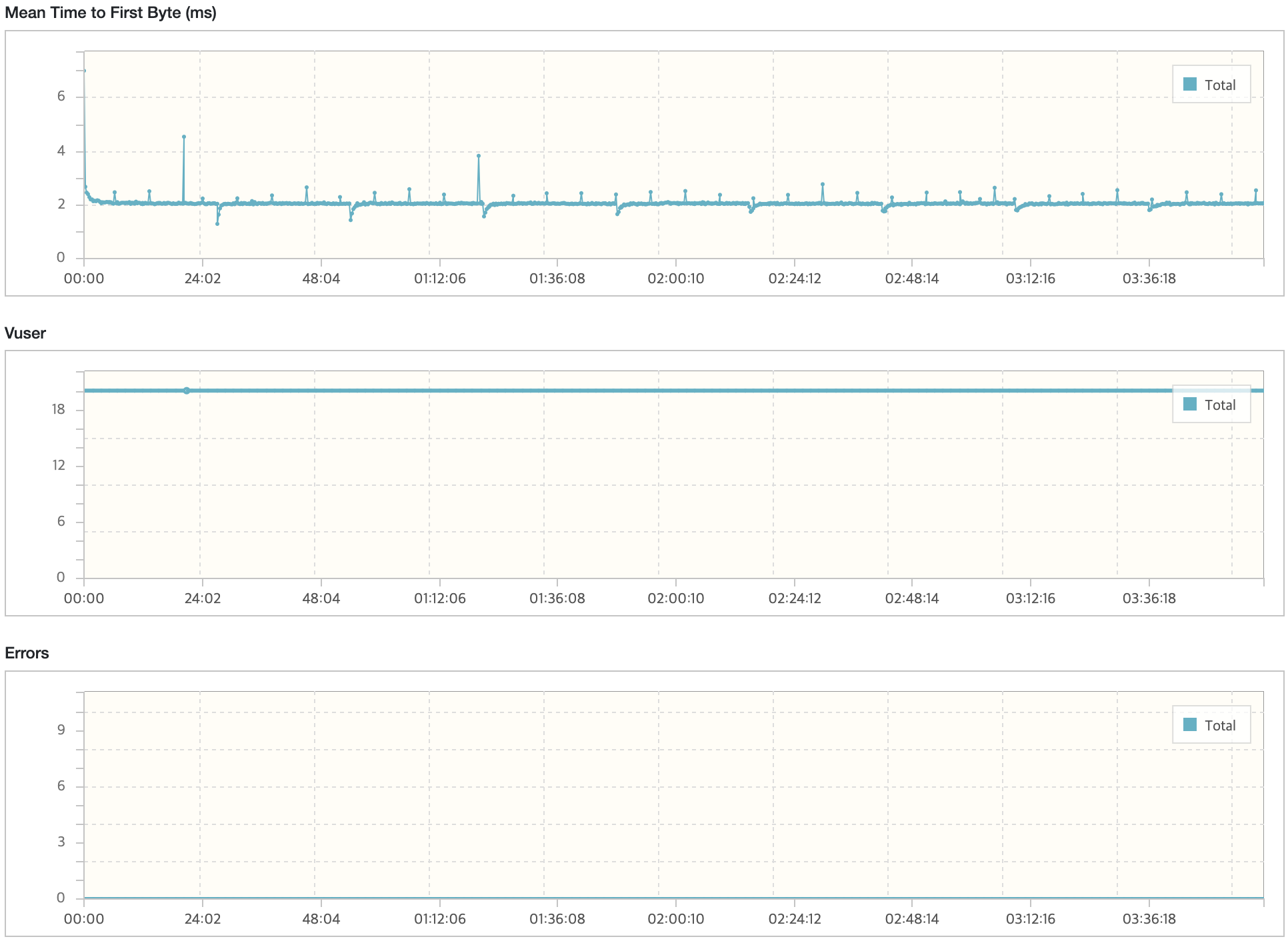
API 서버

RDS - MySQL
결과 분석
시나리오1 비교
| 구분 | TPS/Peak TPS | Response Time(ms) | CPU 사용률/부하율 (API 서버) | GC 발생률/STW(µs) | CPU 사용률/IOPS (RDS - MySQL) |
|---|---|---|---|---|---|
| GC 튜닝 전 | 2905/3703 | 175.5 | 54.3/5.28 | 0.123/378 | 47/1250 |
| GC 튜닝 후 | 2851/3690 | 178.8 | 53.9/5.15 | 0.121/496 | 47.8/1210 |
시나리오2 비교
| 구분 | TPS/Peak TPS | Response Time(ms) | CPU 사용률/부하율 (API 서버) | GC 발생률/STW(µs) | CPU 사용률/IOPS (RDS - MySQL) |
|---|---|---|---|---|---|
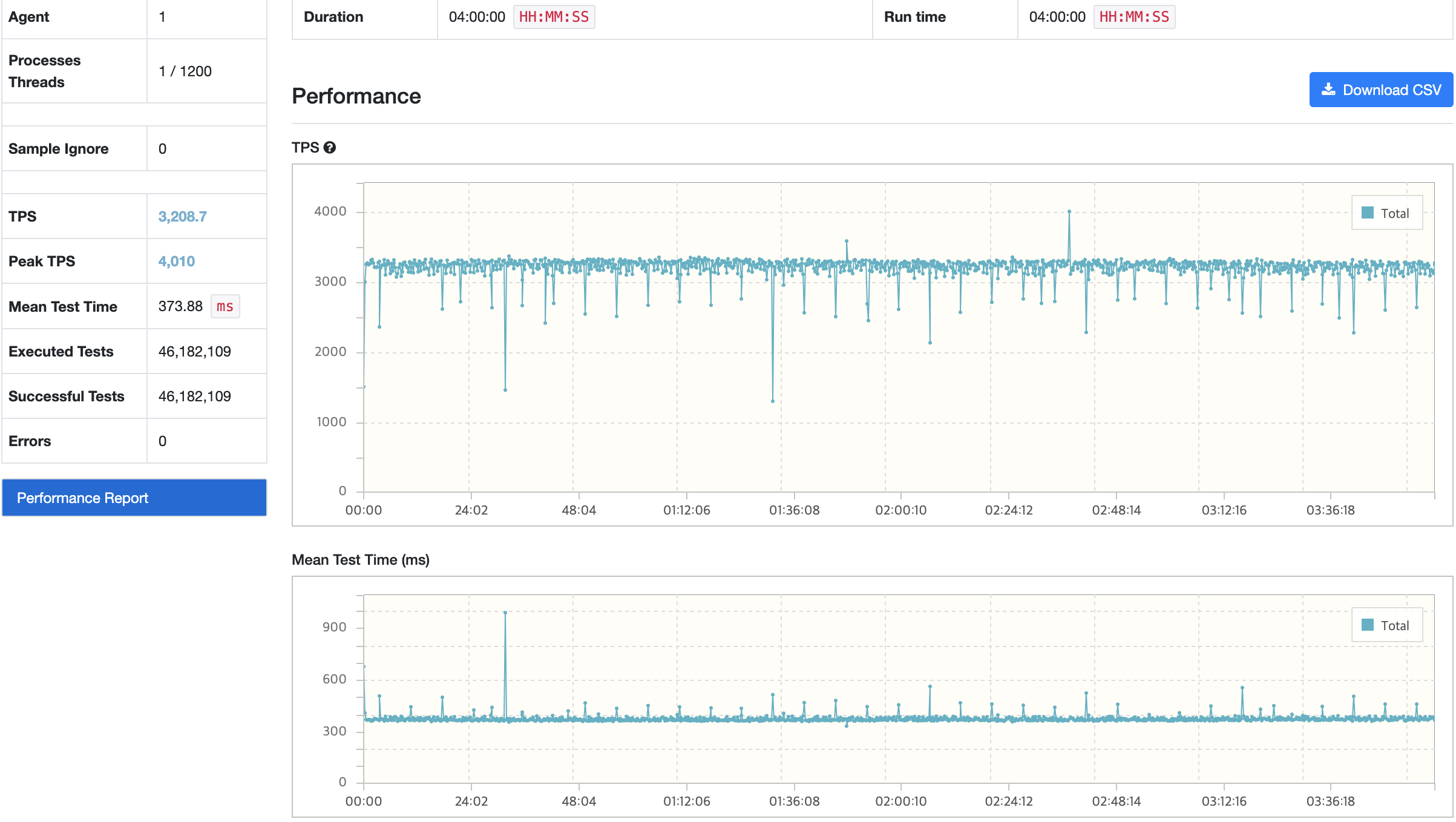
| GC 튜닝 전 | 3166.4/4143 | 378.86 | 58/5.41 | 0.135/497 | 49/1150 |
| GC 튜닝 후 | 3208.7/4010 | 373.88 | 59.6/5.48 | 0.129/487 | 49.5/1160 |
시나리오3 비교
| 구분 | TPS/Peak TPS | Response Time(ms) | CPU 사용률/부하율 (API 서버) | GC 발생률/STW(µs) | CPU 사용률/IOPS (RDS - MySQL) |
|---|---|---|---|---|---|
| GC 튜닝 전 | 3223.4/4089 | 6.11 | 62/5.72 | 0.139/354 | 32.4/2.5 |
| GC 튜닝 후 | 3253.1/4149 | 6.06 | 59.5/5.48 | 0.139/494 | 31/2.5 |
시나리오 전체에 대해서 GC 튜닝 전과 후에 대한 평균적인 수치는 차이가 없는 수준이다. 자세하게 보면 시나리오1에는 20분 이후 성능이 더 향상되었고 시나리오2에서는 시점별 목표 수치 미달성 발생률 감소 그리고 시나리오3은 CPU 부하가 감소한 것을 확인할 수 있었다.
급격하게 TPS가 감소하고 응답시간이 증가하는 시점의 경우 토큰 발급 및 재발급이 원인이였다. 처음에는 원인을 알 수 없었지만, 테스트를 여러번 반복해서 확인하면서 전체적인 Resquest Count가 줄어들고 토큰 발급 및 재발급 횟수가 증가한다는 점에서 원인을 확인할 수 있었다. 사용자의 서비스 이용에 대한 패턴을 고려하여 시나리오를 작성하다보니 발생하게 되었다.
마무리
내구성 테스트 과정에서 중점적으로 진행한 부분은 GC에 대한 학습과 튜닝이며, 이 과정이 가장 오래걸렸다. 처음에 GC 튜닝을 처음 시작했던 시점은 부하 테스트 때 였다. 생각해보면 불필요한 튜닝을 했다. 내구성 테스트에서 서버 Scale Up을 하게되면 GC 튜닝을 다시 해야하는 문제가 있고 테스트 또한 다시 진행해야 하기에 지연되는 문제가 있다. 그리고 GC 튜닝을 하는 것 보다 오히려 하지 않았을 때가 더 좋은 결과를 만들수도 있다.
결과적으로, GC 튜닝은 마지막 단계에서 진행하는 것이 옳다고 생각한다.
몇몇 기술 블로그를 보면서 GC 튜닝이 굳이 필요하지 않을 수 있다라는 글을 보기도 했다. GC에 대한 학습 전에는 JVM에서 메모리를 관리하는 기능이다보니 단순히 기본적으로 설정된 옵션과 값만으로 충분히 서비스를 운영할 수 있겠지에 대한 생각만 했었다. 하지만, 여러 케이스로 GC 튜닝과 테스트를 진행하면서 개선된 부분이 있었고 이에 튜닝이 필요하다고 생각했다.
GC 튜닝 전과 후를 비교할 때 리소스 사용률이 눈에 띄게 달라진 부분은 없지만 반복적인 성능 감소 이슈를 해결할 수 있었고, 목표에 만족하는 결과를 얻을 수 있었다.
VUser, RPS, TPS, Response Time 등 목표한 값으로 고정적인 트래픽으로 테스트를 했지만, 변화하는 트래픽 환경에서 비용을 줄이고 이슈 발생에 신속한 대응을 위해 인프라 재구성이 필요하다고 생각한다. 여행 플래너 주제로 보면 여행 시즌과 비시즌에 트래픽이 차이가 있다. 다음 글에는 주제에 따른 트래픽을 정리하고 인프라를 재구성하여 스트레스 테스트를 진행하고자 한다.