대용량 트래픽 경험해보기(10/14) - 부하 테스트
시나리오별 RPS 및 VUser 계산
- DAU : 25,000 (주제 및 분석 참고)
- RPS : DAU x 1명당 1일 평균 요청 수 / 86400(초)
- VUser : 목표 RPS * T / R
- T : 한번의 시나리오를 완료하는데 걸리는 시간(s)
- R : RPS
- 목표 Response Time : 500ms
- 목표 TPS : Active User / Response Time
- Active User는 VUser로 계산
시나리오1
로그인 → 여행 현황 조회 → 여행 정보 조회 → 여행 정보 추가 → 여행 정보 조회 → 여행 정보 수정 → 여행 정보 삭제
- 시나리오별 1명당 1일 평균 요청 수 : 7.5
- T(한번의 시나리오를 완료하는데 걸리는 시간) = 430초
시나리오2
로그인 → 여행 현황 조회 → 여행 정보 조회 → 여행 계획 현황 조회 → 여행 계획 추가 → 여행 계획 조회 → 여행 계획 수정 → 여행 계획 삭제 → 일별 여행 계획 거리순 정렬
- 시나리오별 1명당 1일 평균 요청 수 : 18.5
- T(한번의 시나리오를 완료하는데 걸리는 시간) = 1000초
시나리오3
로그인 → 여행 현황 조회 → 여행 정보 조회 → 여행계획 현황 조회 → 여행계획 조회
- 시나리오별 1명당 1일 평균 요청 수 : 11.5
- T(한번의 시나리오를 완료하는데 걸리는 시간) = 13.5초
시나리오 별 RPS, VUser, 목표 TPS
| 구분 | RPS/Peak RPS(안전계수 포함) | 평균 VUser/Peak VUser | 목표 TPS |
|---|---|---|---|
| 시나리오1 | 2.2/8.8 | 130/510 | 260/1020 |
| 시나리오2 | 5.4/21.6 | 300/1200 | 600/2400 |
| 시나리오3 | 3.3/13.2 | 5/20 | 10/40 |
API 서버 및 RDS 사양
| 구분 | API 서버 | RDS |
|---|---|---|
| OS/DBMS | Amazon Linux 2 | MySQL 8.0.33 |
| 인스턴스 유형 | t2.micro | db.t3.micro |
| vCPU | 1(1 Core) | 2 |
| Memory | 1GB | 1GB |
| Network | Low to Moderate | 최대 2,085Mbps |
| Storage | 12Gb | 100GiB(최대 300 IOPS) |
시나리오1 부하 테스트
평균 사용자 부하 테스트
- VUser : 130
- Random Up - 초기 VUser 10, 10초마다 VUser 20증가
트러블 슈팅
nGrinder
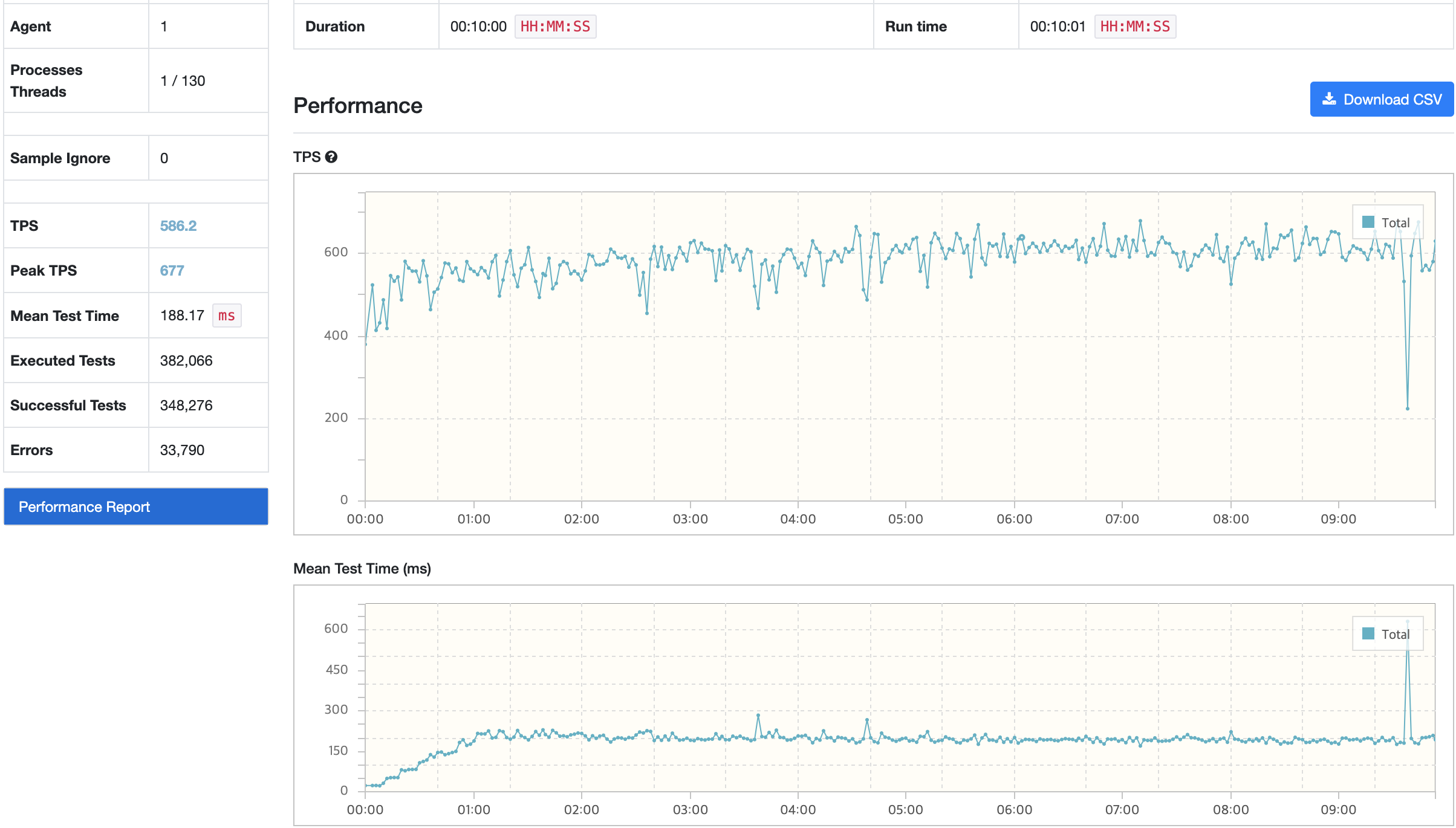
API 서버


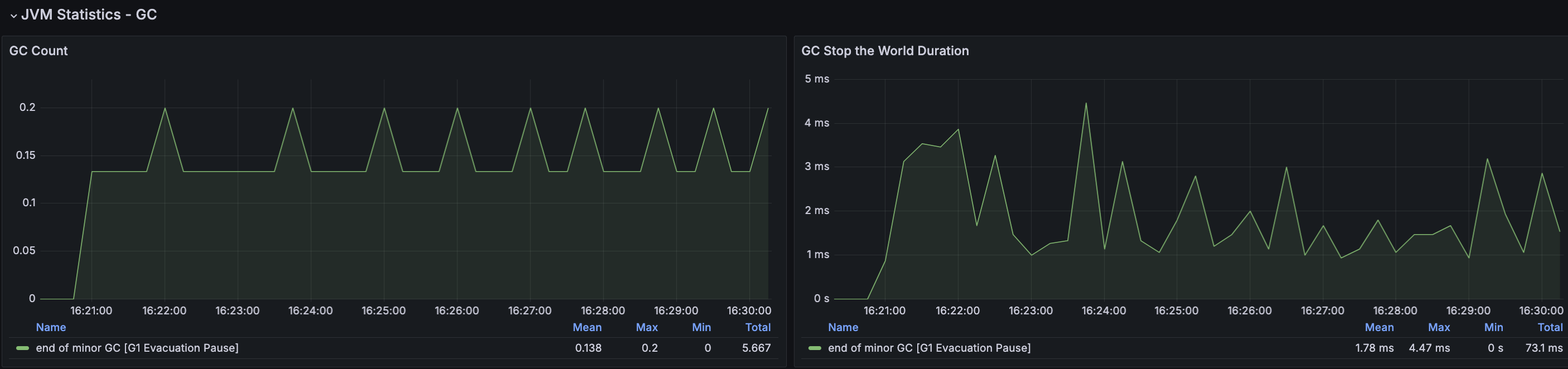

RDS - MySQL
문제 상황
TPS가 급격하게 감소한 수치의 경우 TPS는 220이고 MTT는 630ms이다. 목표한 TPS에 만족하는 수치이지만 MTT의 경우 목표 응답시간을 벗어났다. 목표 수치에 미치지 못한 것은 개선해야할 부분이지만 TPS가 급격하게 감소하는 것은 시스템에 큰 부하가 발생하는 것으로 수정할 필요가 있기에 확인해보았다.
원인 추론 및 분석
확실하게 눈에 띄는 부분은 CPU Load Average이다. 과도한 부하를 보이고 있고 이에 CPU 사용률도 증가하지만 제한된 70% 정도의 사용률을 보이고 있다. CPU 부하는 다양한 이유가 있어 우선 메모리 분석을 통해 메모리 누수가 있는지 확인해보았다.
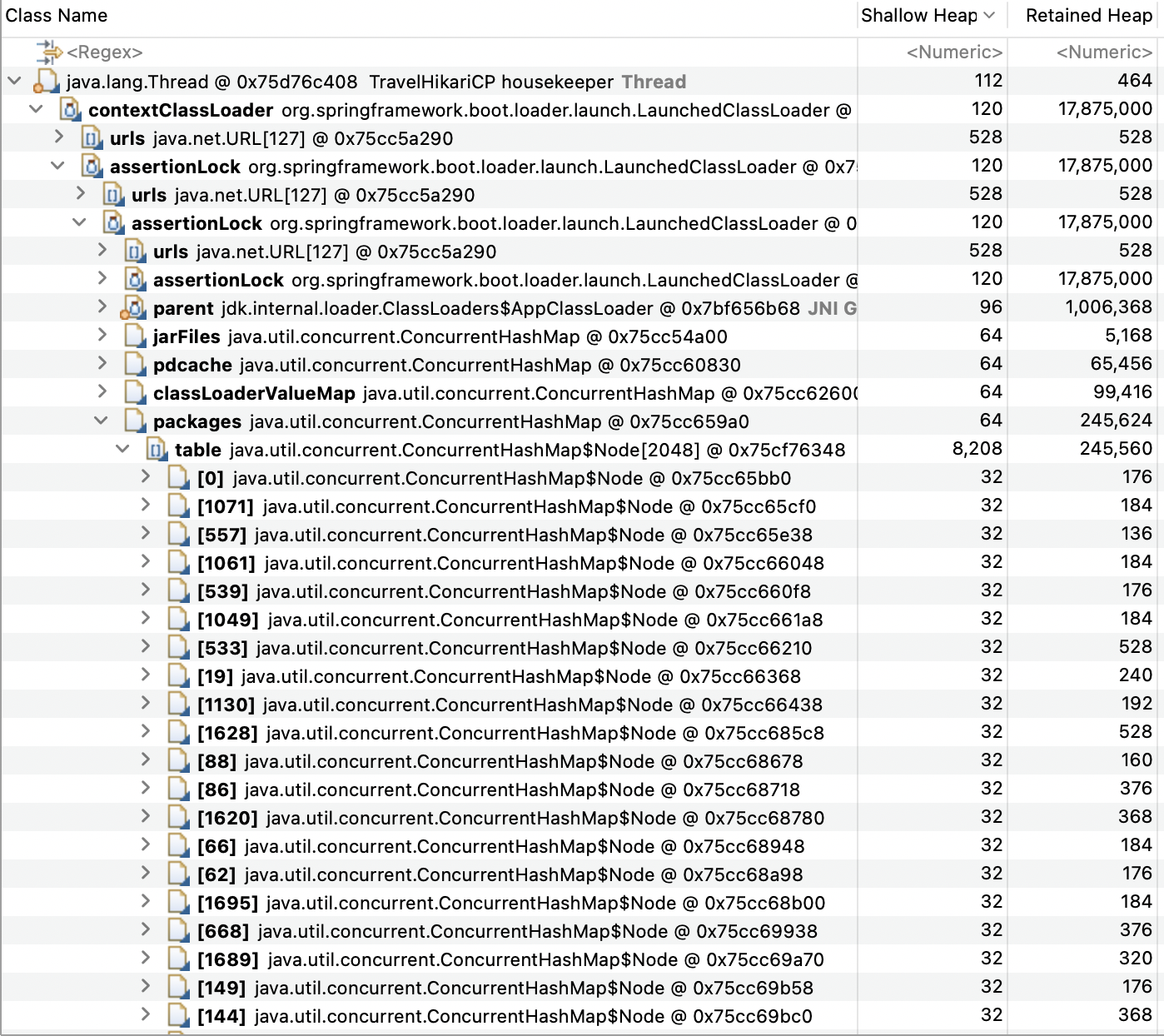
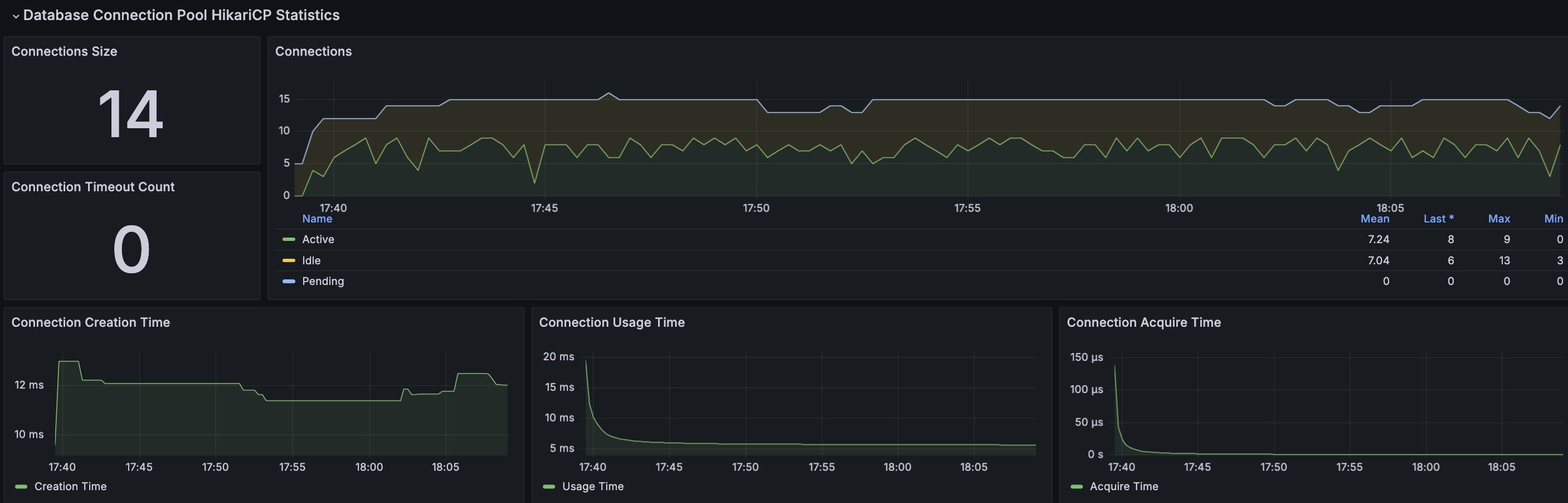
HikariCP가 메모리 누수에서 가장 높은 비율이다. 위 경우에 대해 찾아보았을 때 현재 테스트 결과에서 가장 알맞는 부분으로 설정한 Connection 크기 보다 더 많은 요청이 있는 경우 발생하는 것 같다라는 판단을 했다. 이에 설정된 Connection 수에서 평균 Pending수를 더한 수치로 재테스트 해보자
Max Connection Size : 50 → 80(Active 50 + Pending 30)
결과
nGrinder
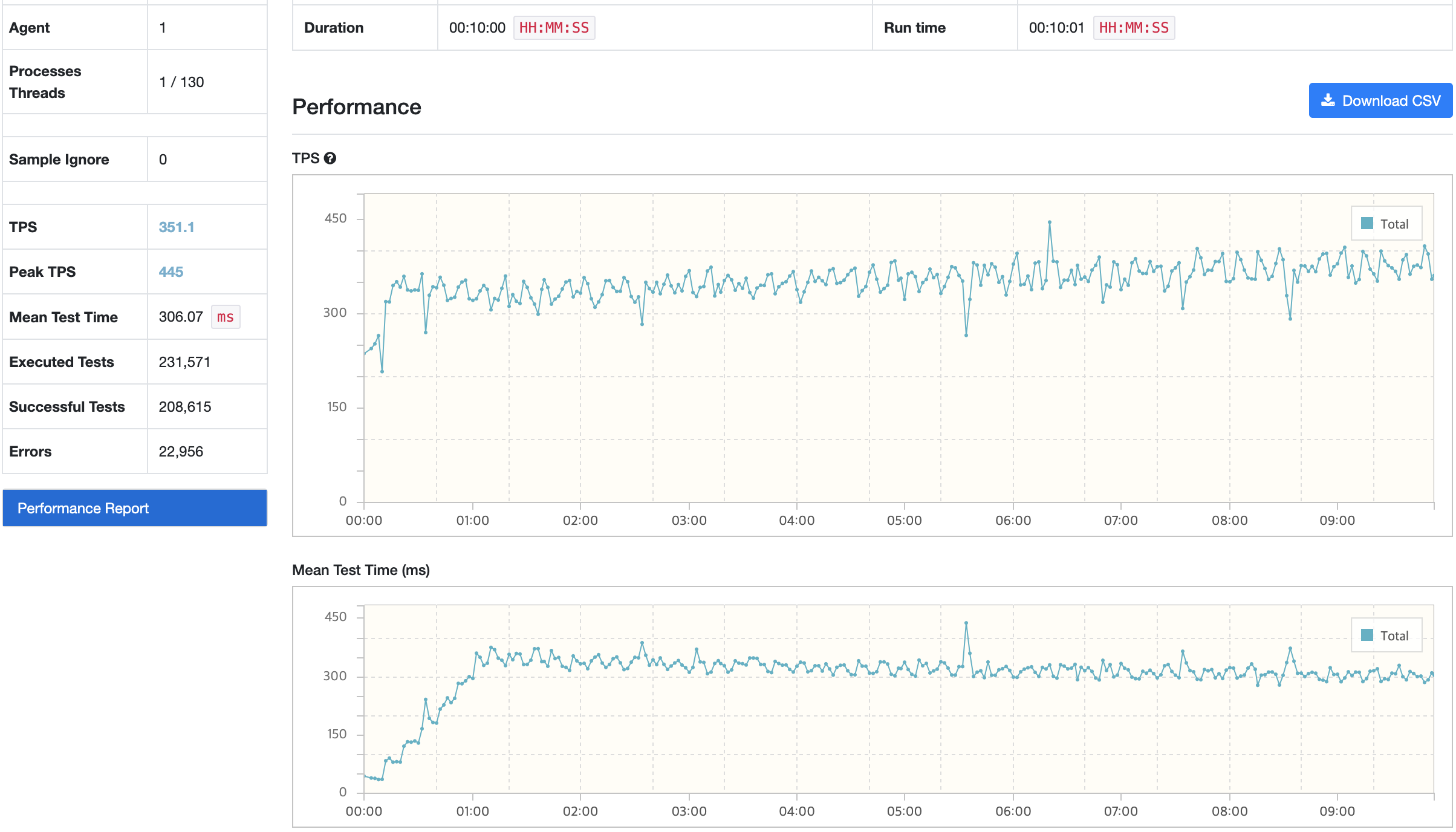
API 서버


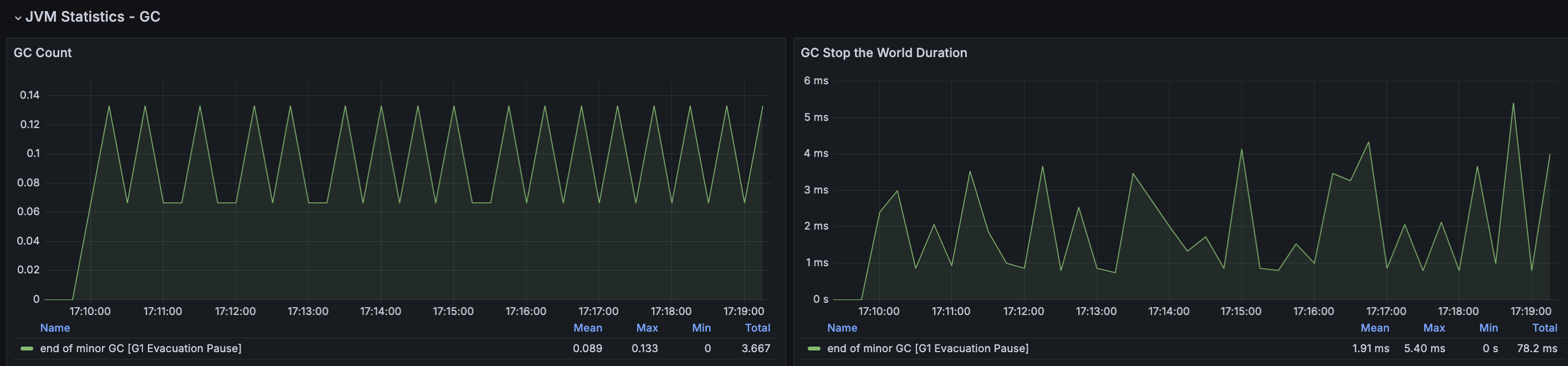
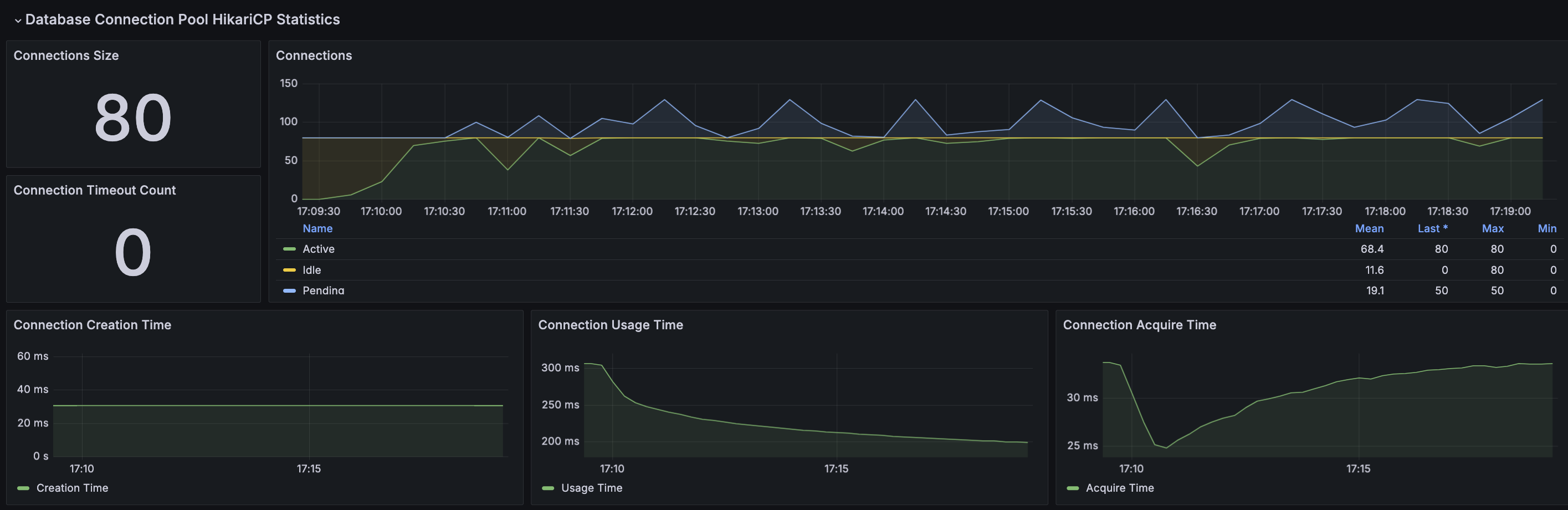
RDS - MySQL
결과 분석
요청이 지속될 수록 DB 연결을 대기해야하는 스레드가 쌓이게 되면서 특정 시점에 TPS가 급격히 감소하는 현상이 발생한 것으로 보인다.
CPU 부하율은 여전히 높지만 TPS와 MTT는 목표 수치를 만족하며 TPS가 급격하게 감소하는 현상도 발생하지 않았다.
Peak 사용자 부하 테스트1
- VUser : 510
- Random Up - 초기 VUser 10, 10초마다 VUser 50증가
VUser 510에 대한 시나리오 테스트 전에 앞의 트러블 슈팅에서 DB Connection 수를 약 2배로 증가한 후 테스트해보려 한다.
Max DB Connection : 80 → 150
테스트 결과
nGrinder
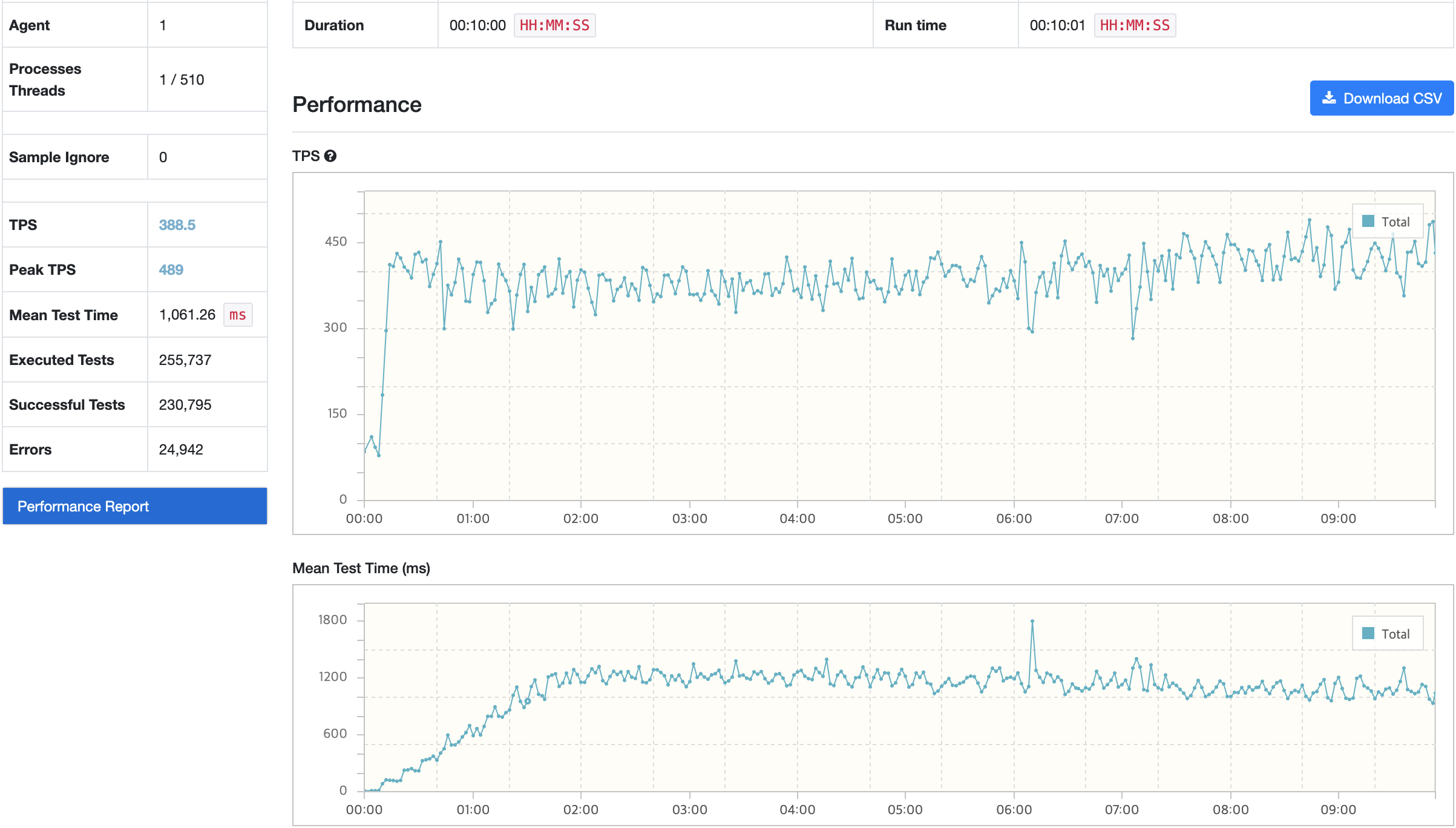
API 서버


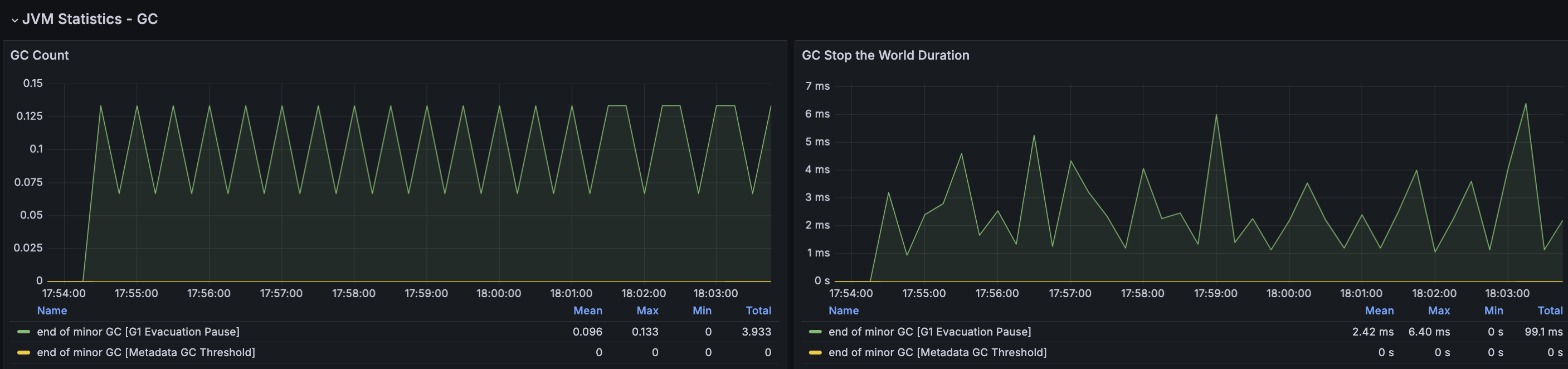
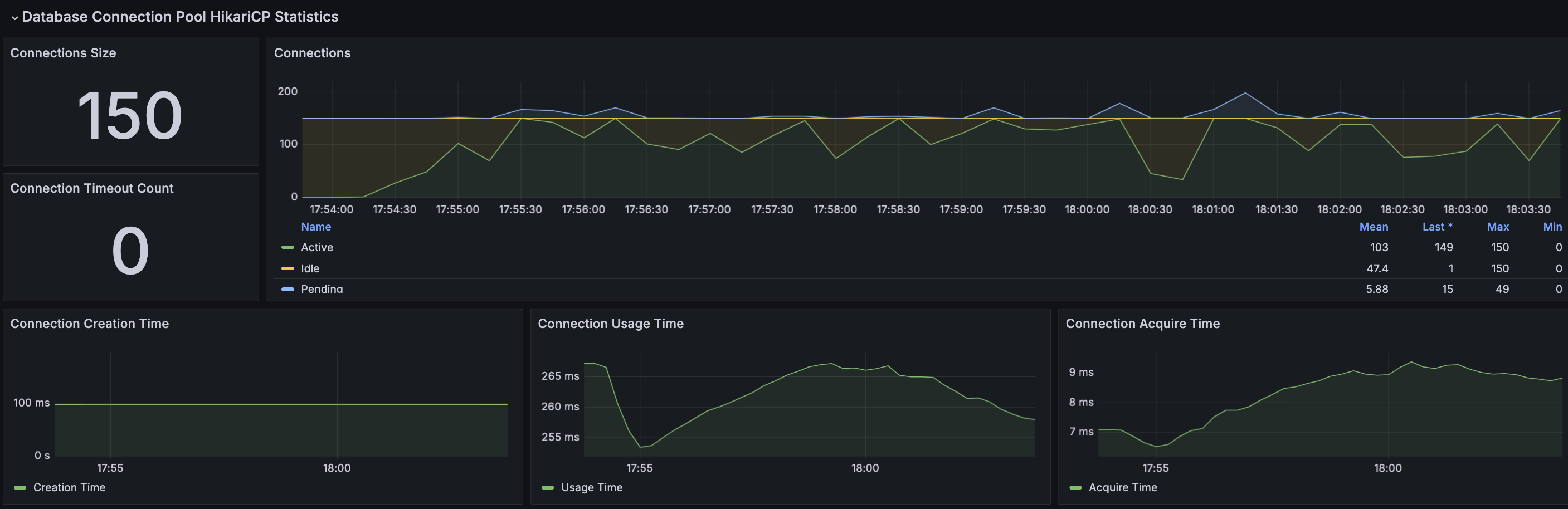
RDS - MySQL
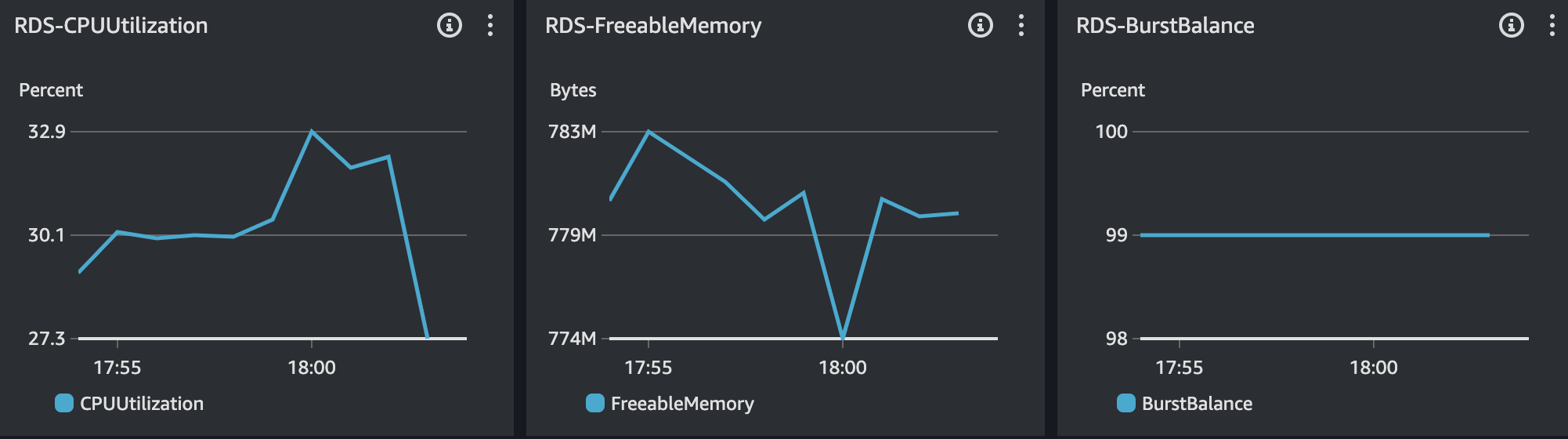
결과 분석
VUser 510으로 10분간 테스트 했을 때, TPS와 Response Time이 목표 수치에 만족하지 못한 상황이다. MTT의 경우 평균 테스트 시간이지만 Response Time으로 봐도 무관하다. 이에 응답시간을 줄이는 방법으로 아래 3가지 방법을 생각했다.
- Slow Query 확인 후 튜닝
- 처리량을 상승하기 위해서 Worker Thread 증가
- CPU의 Load Average가 과도하게 사용되고 있기에 서버 Scale Up/Out
위 3가지 경우에서 가장 우선적으로 확인해봐야할 부분은 1번 내용이다. 2번에 대한 내용의 경우 스레드를 증가시키지만, 결론적으로 CPU가 처리할 수 있는 양에 따라 더 나쁜 상황을 발생시킬 수 있다. 현재 200개로 되어 있지만, 오히려 더 증가 시키게 되면 Load Average가 더 증가하여 이슈를 발생시킬 수 있다고 판단한다.
Slow Query 확인
Slow Query를 확인했을 때 500ms 이상의 처리 시간을 보이고 있는 SQL 중 많이 의문이 생긴 쿼리는 이메일을 이용한 회원 PK 조회하는 단순한 쿼리였다. 이메일 컬럼의 경우에도 Unique Index가 걸려있는 것을 확인했다. 그리고 실행 계획의 경우에도 적합한 인덱스가 사용되고 있었다.
해당 쿼리를 더 튜닝할 수 있을까? 라는 생각을 해보았을 때 없다고 본다. 개선해야할 방법을 생각했을 때, Token 관리를 위해 사용되고 있는 In Memory DB Redis를 활용해보고자 한다. Spring에서의 2차 캐시를 이용해 사용할 수 있지만, 메모리 사용률이 증가하면 GC 발생률도 자연스럽게 올라가게 될 것이고, 이 것은 CPU에 더 부하를 준다는 의미이기 때문에 2차 캐시를 사용하는 것보다 Redis를 사용하는 것이 더 적절하다고 생각했다.
Redis 활용 전 고려사항
최대 752,703명 회원에 대한 회원 PK를 관리하기에 충분한 스팩인가?
- CPU 사용률 : 최대 4.5%
- 메모리 사용률 : 500MB 중 최대 2.7%
회원 PK는 건당 8Byte이며 752,703건에 대한 필요 용량은 5.74Mb이다. 모든 회원 PK를 관리한다고 했을 때 500MB 중 최대 1.2% 정도 사용률이 증가할 것로 보이며 CPU 사용률에서도 문제가 없다고 판단된다.
Peak 사용자 부하 테스트2
- VUser : 510
테스트 전 변경 사항
- 회원 PK 조회 후 Redis에서 추가 관리
- 테스트 시간 10분에서 30분으로 변경
테스트 결과
nGrinder
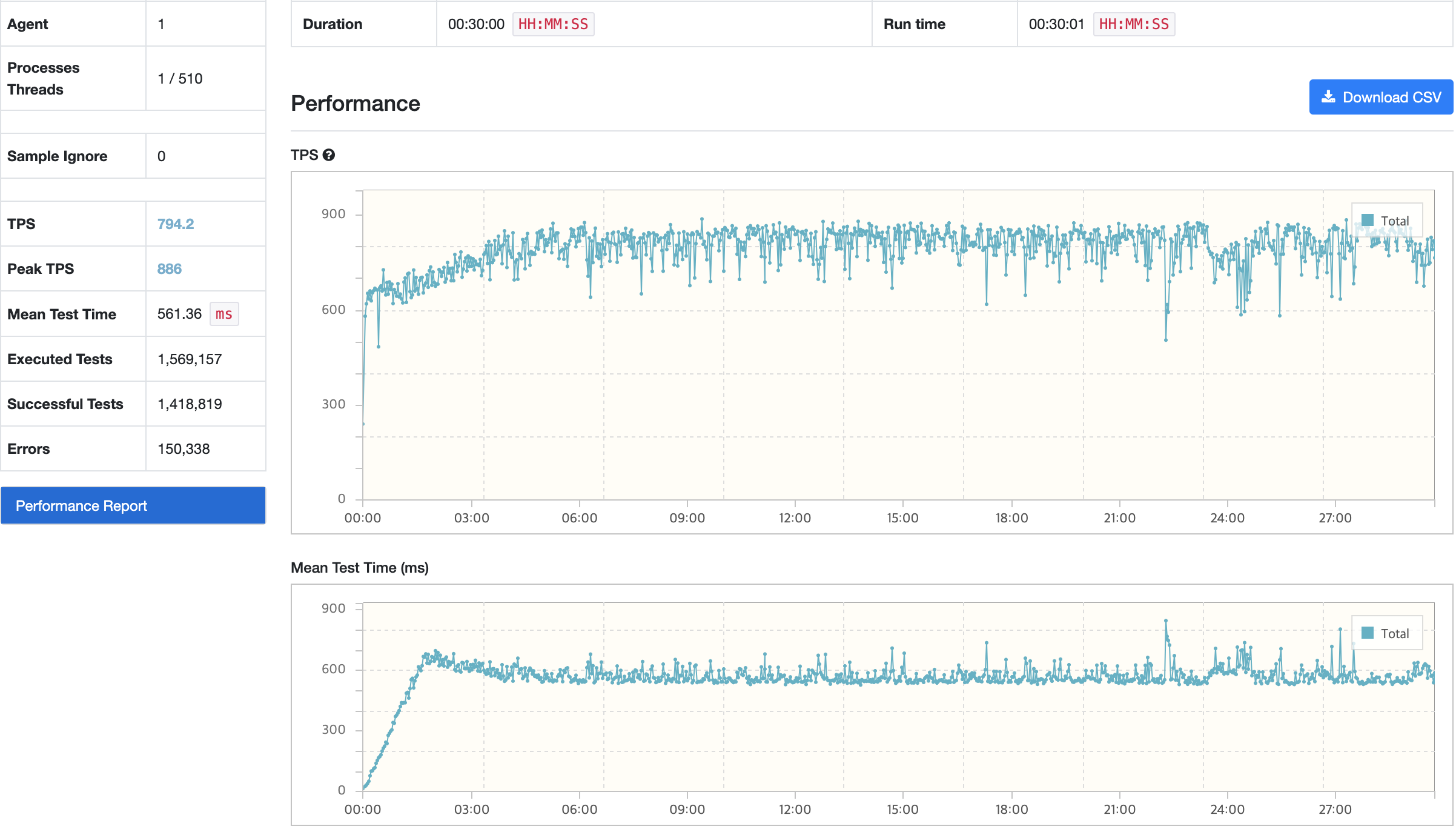
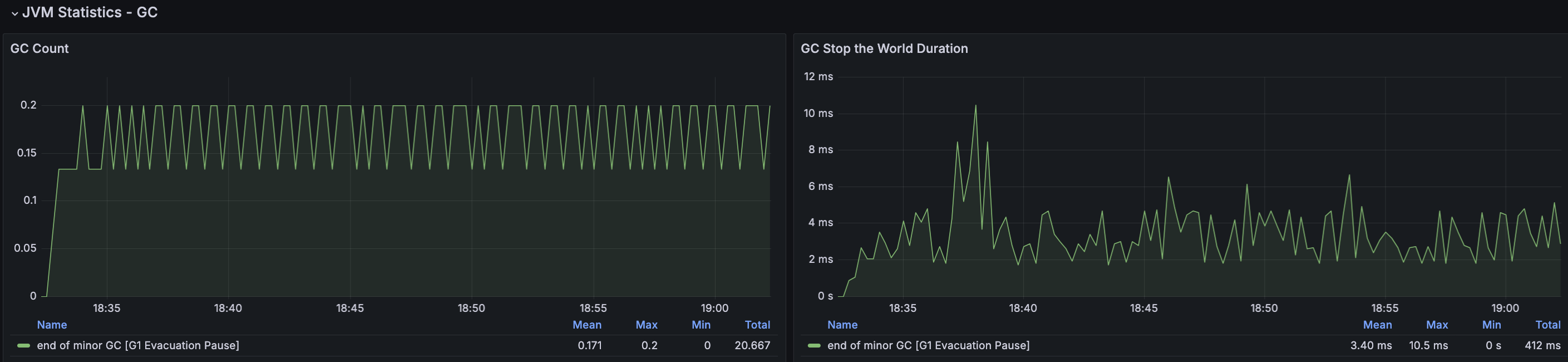
API 서버


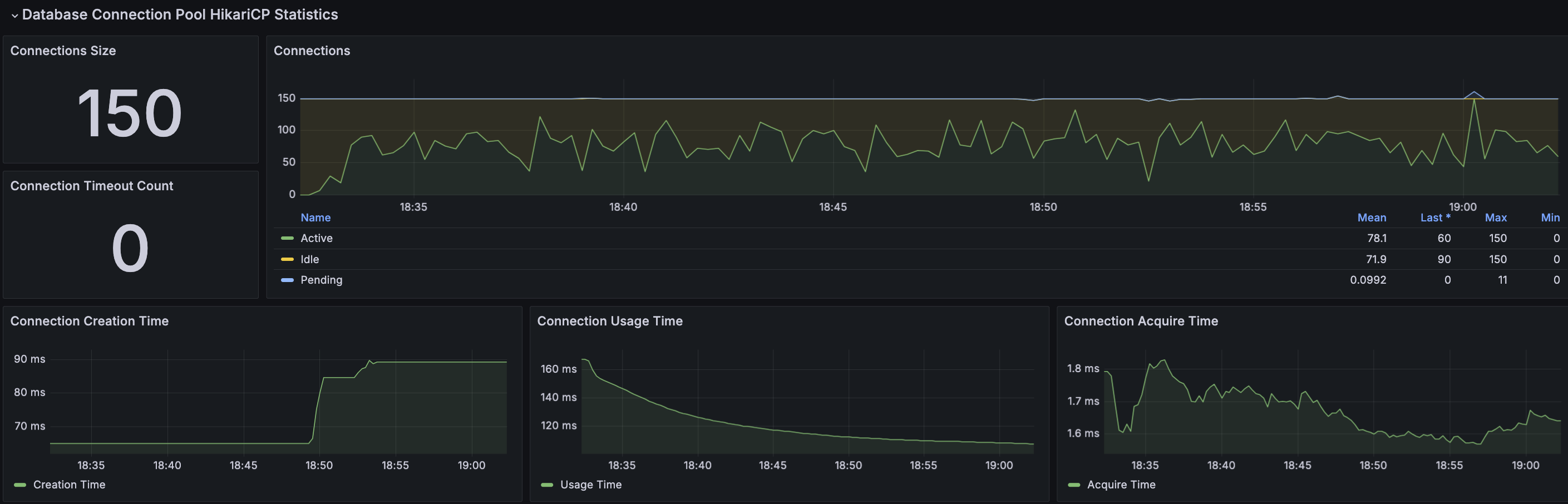
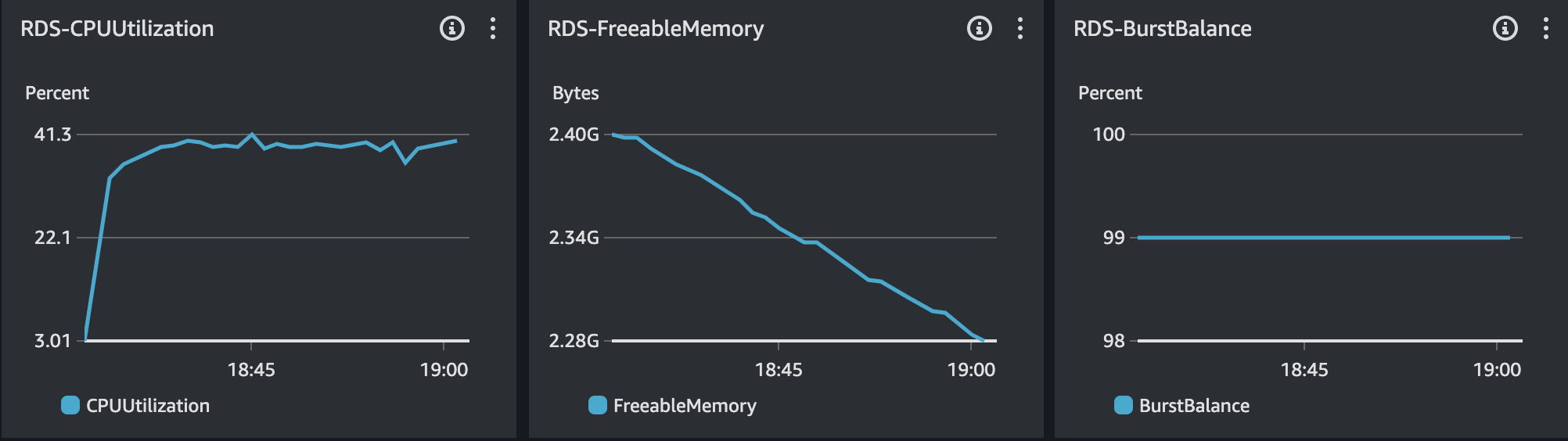
RDS - MySQL
Redis
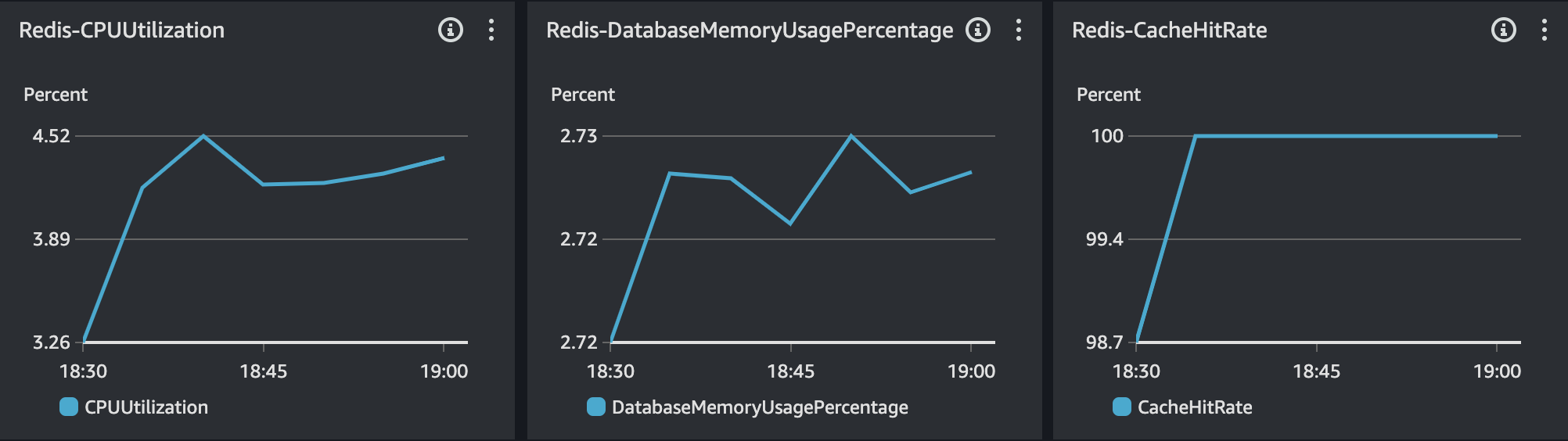
결과 분석
부하 테스트 과정에서 평균 목표 응답시간은 500ms 수준으로 맞춰졌다. Innodb 버퍼 사용률의 경우에도 약 30% 정도가 감소한 것으로 확인된다. 다만, 테스트가 지속되다보니 TPS가 크게 감소하거나 감소된 상태로 어느정도 지속되는 현상이 발생했다. 메모리 분석을 통해 누수원인을 확인했을 때 처리되지 못하고 대기중인 요청이 남아 있는 것으로 확인했다.
이점에서 이전 테스트 과정에서 고려한 3번의 서버 스팩을 향상시켜야 한다고 판단했다. 서버 확장에 대한 고려사항은 다양하다. 과도한 트래픽으로 서버 자체가 다운되는 현상 혹은 지연시간이 급격하게 증가하여 성능이 저하되는 현상 등
현재 테스트하고 있는 서버의 경우 CPU와 Memory 사용률을 제한한 상태로 Container를 운영하고있다. 그렇다보니 서버가 다운되는 현상은 발생하지 않았지만, 성능이 감소되는 현상으로 Tomcat Thread 스레드 조정 및 서버 확장이 필요해보인다.
API 서버 Scale Up
| 구분 | Before | After |
|---|---|---|
| 인스턴스 유형 | c5a.large | c5a.xlarge |
| CPU | 2(1코어) | 4(2코어) |
| Memory | 4GiB | 8GiB |
| Network | 최대 10GiB | 최대 10GiB |
| 비용 | 시간당 0.0860USD | 시간당 0.1720USD |
Tomcat Worker Thread 조정
Worker Thread = 초당 처리해야하는 요청 수 x 목표 응답시간
시나리오 1,2,3에 대해 가장 높은 시나리오의 경우 초당 처리해아하는 요청 수는 21.6이며, 목표 응답시간은 0.5s로 Worker Thread는 약 11이지만 여유 스레드를 추가적으로 할당하여 20을 기준으로 잡고 진행하기로 하였다.
Peak 사용자 부하 테스트3
테스트 결과
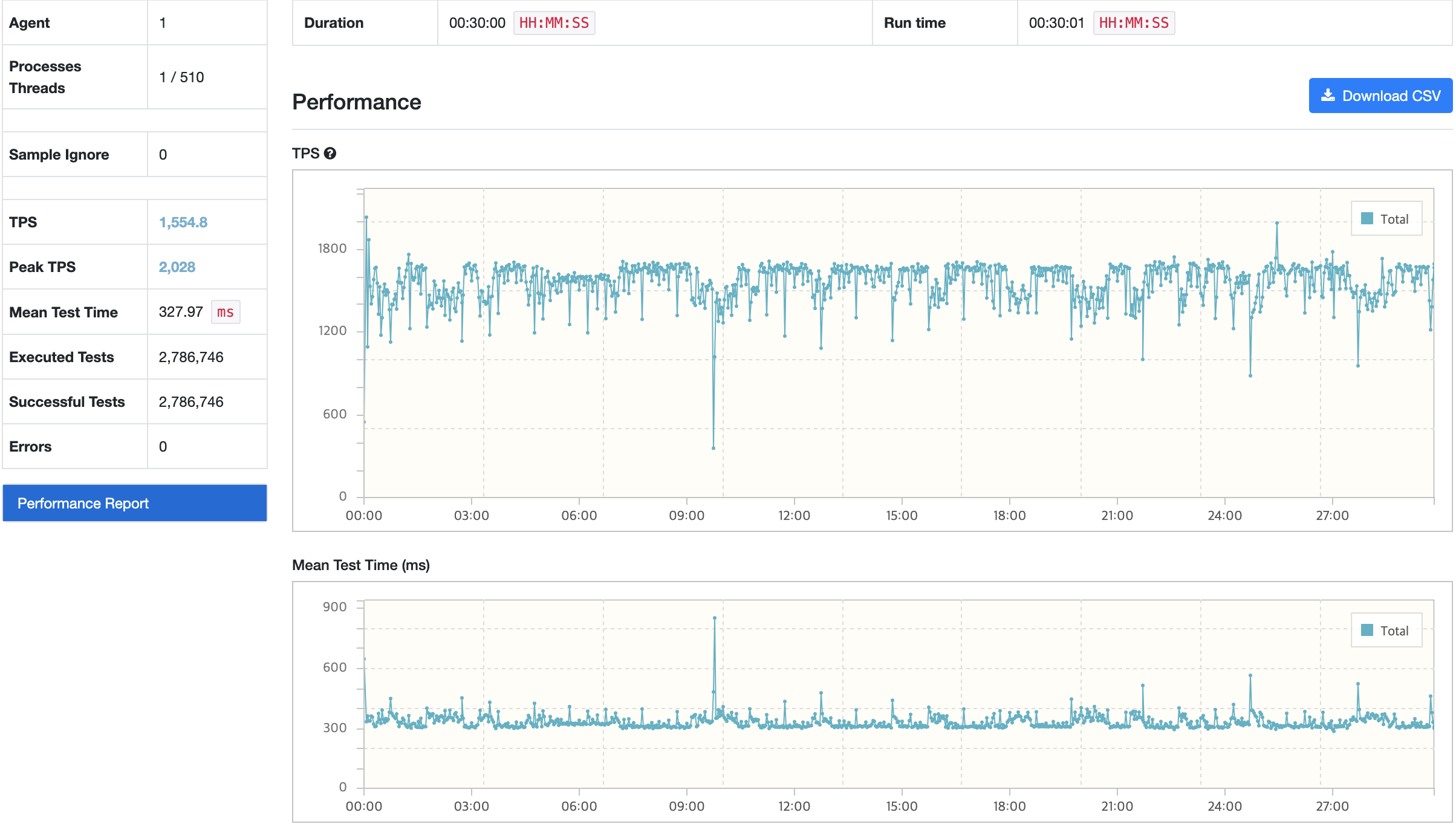

트러블 슈팅
문제 상황
CPU Load Average의 경우 Tomcat Worker Thread를 줄여 활성화 스레드를 감소하다보니 부하율이 감소했지만, nGrinder에서 주기적으로 TPS가 감소하는 현상이 발생하였고 한번 씩 큰 폭으로 감소하는 현상이 있다.
모니터링을 보았을 때 크게 이슈있가 있을만한 문제는 없어보였다. 메모리 분석의 경우에도 이전과 비슷하게 요청에 따른 이슈는 있었지만 이로 인해서 메모리 누수가 과하다고 판단되지 않았다.
원인 분석 및 추론
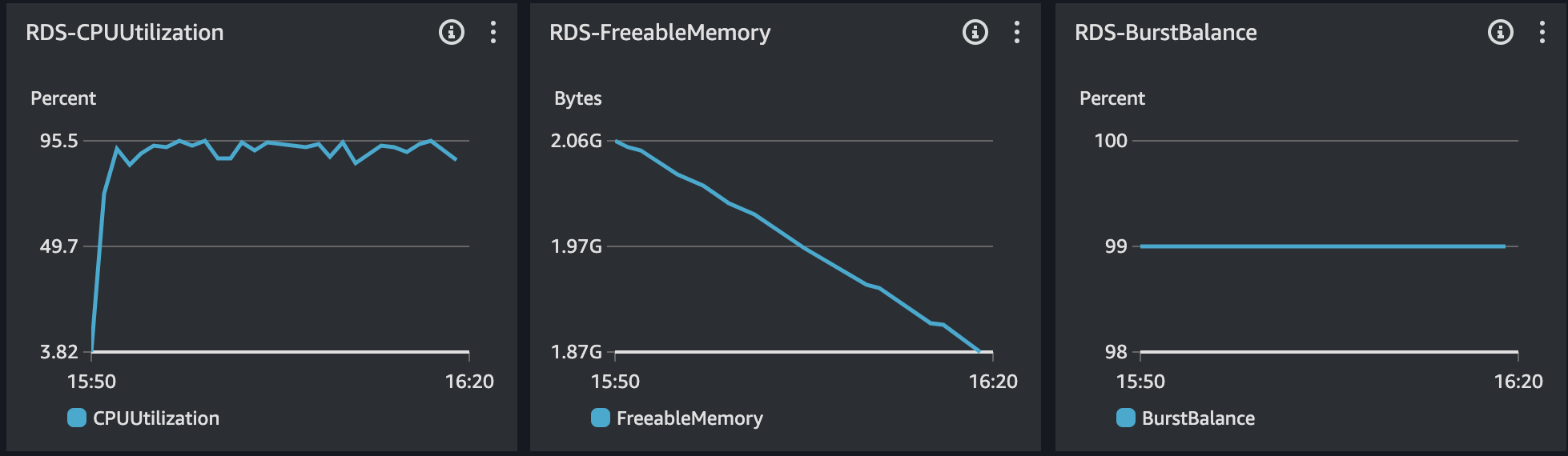
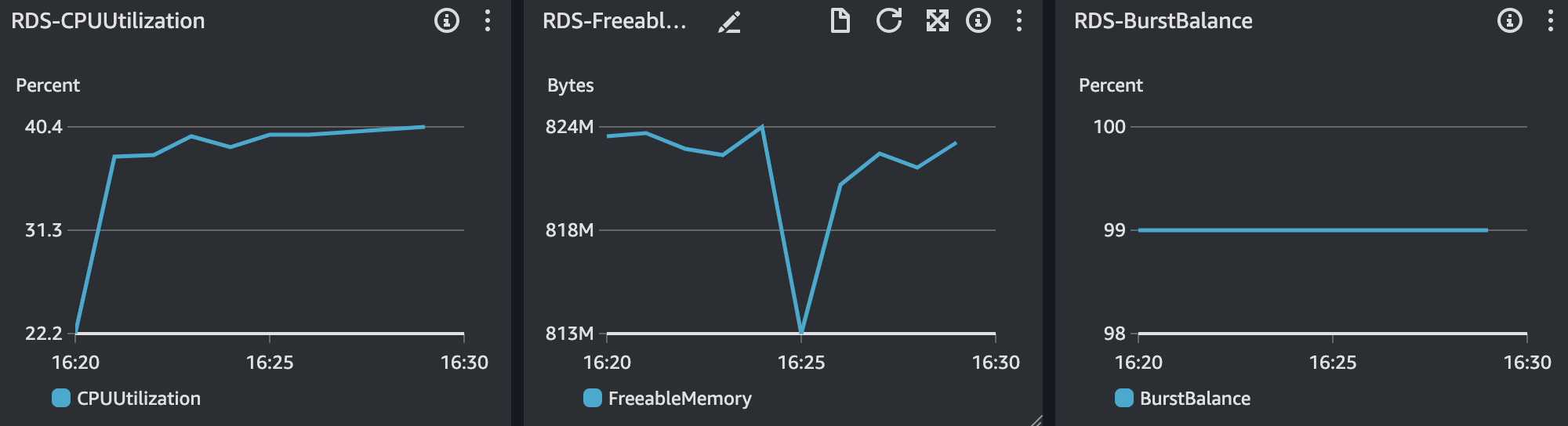
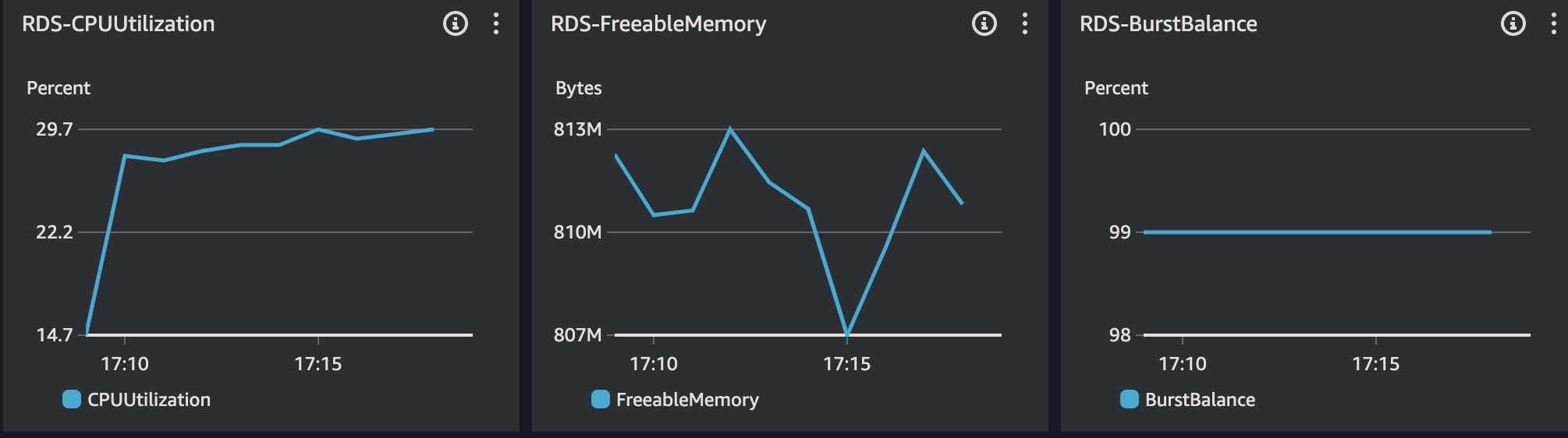
RDS 모니터링 결과는 위와 같다. CPU의 사용률이 급격히 증가하는 현상이 있다.
정리하면, DB 서버의 CPU 사용률이 급증하게 되면서 처리량이 감소되는 현상이다. 이 결과로 이전에는 보이지 않았지만, 아주 간단한 쿼리에도 Slow Query가 발생했다.
해결 방안
해결 방안으로 2가지가 있어보인다.
- MySQL 튜닝
- DB 서버 Scale Up
MySQL 튜닝의 경우 이미 처리를 한 상황이다. 수정한 파라미터는 아래와 같다.
- innodb_log_file_size : 128Mb
- innodb_flush_log_at_trx_commit : 1
- innodb_write_io_threads : 4
- innodb_read_io_threads : 4
- innodb_thread_concurrency : 8
- innodb_io_capacity : 200
- innodb_buffer_pool_instances : 4
데이터 추가, 수정, 삭제에 대해서도 튜닝 가능한 옵션이 innodb_flush_method, innodb_flush_log_at_trx_commit가 있다. 하지만, 성능 향상을 목적으로 두 옵션을 변경할 시 데이터 유실에 대한 우려가 있기에 변경하지 않았다. 데이터 또한 많은 것이 아니라고 판단하기에 DB 서버 Scale Up을 진행해야할 것으로보인다.
| 구분 | Before | After |
|---|---|---|
| 인스턴스 유형 | db.t3.medium | db.t4g.xlarge |
| vCPU | 2(1코어) | 4(2코어) |
| Memory | 4Gb | 16Gb |
| Network | 2,750Mbps | 2,750Mbps |
| 인스턴스 유형 | 시간당 0.104USD | 시간당 0.406USD |
MySQL 추가 튜닝
- innodb_log_file_size : 256Mb
- innodb_write_io_threads : 8
- innodb_read_io_threads : 8
- innodb_thread_concurrency : 12
- innodb_buffer_pool_instances : 8
결과
nGrinder
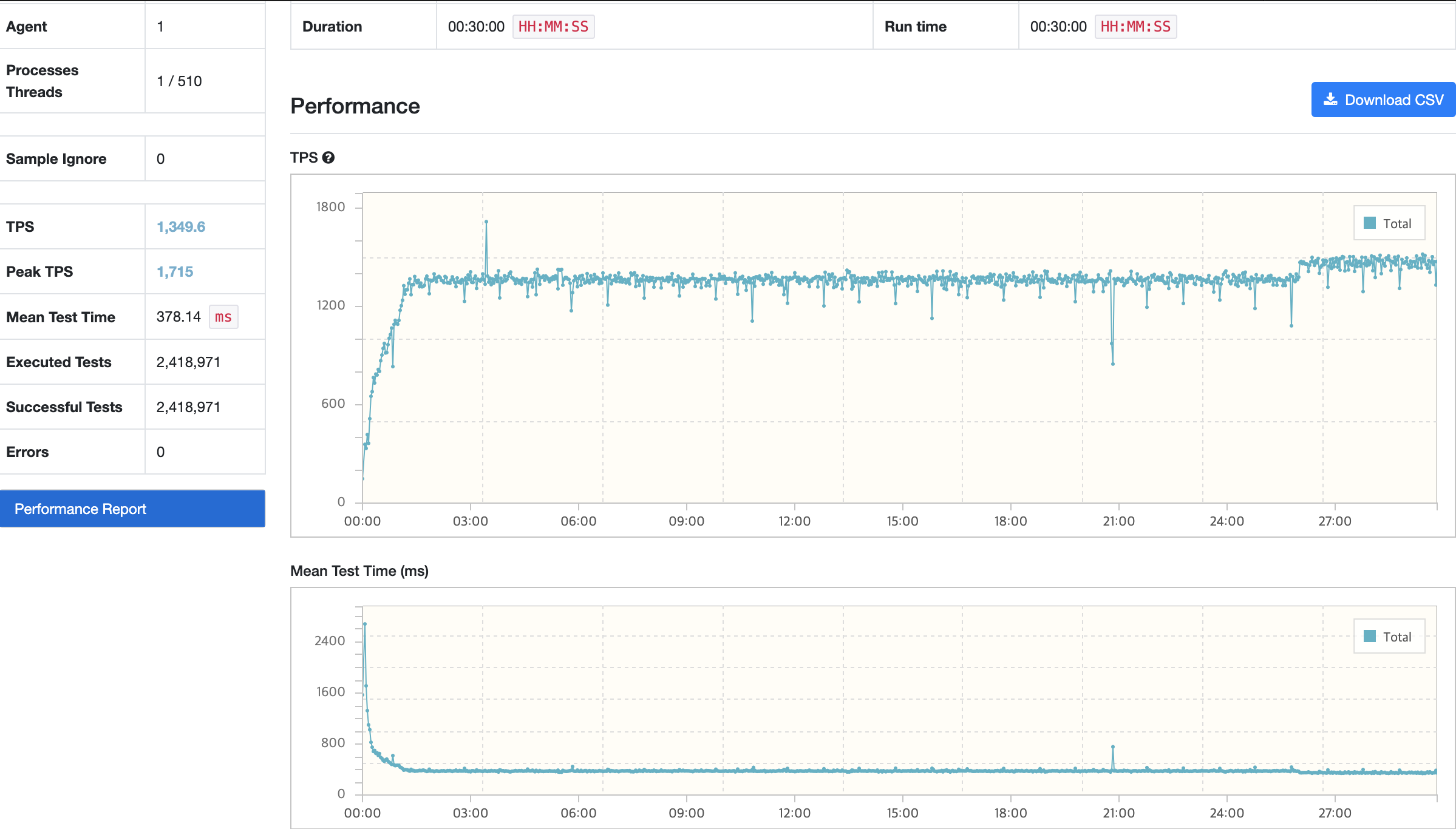
API 서버


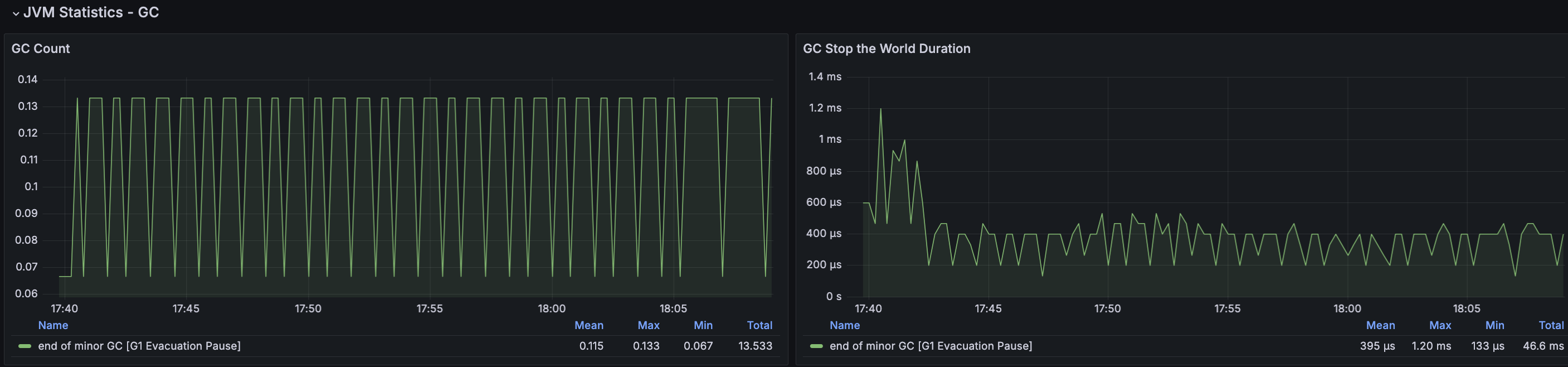
RDS - MySQL
- 30분동안 약 60MB의 스토리지 사용
결과 분석
테스트 과정에서 TPS가 크게 감소하는 부분이 있다. 이때의 MTT의 경우 750ms이다. TPS가 감소하고 응답시간이 증가하는 현상이 있었지만 주기적으로 감소하는 현상이 있거나 감소된 상태에서 유지되는 부분도 없기에 이슈는 없을 것으로 판단된다.
CPU Load Average도 안정적인 부하를 보이고 있으며 이로 인해 CPU 사용률도 50%정도로 지속적으로 유지중이다.
DB에서 중요한 부분으로 IOPS가 있다. 지난 테스트까지 깜빡하여 측정을 못했지만, 이번 테스트에서는 1000 ~ 1200사이에서 IOPS가 유지되며 이는 현재 설정된 범용 SSD 유형으로 400GB 정도이며 해당 IOPS에 맞도록 Storage 또한 변경하였다.
앞의 몇몇 테스트에서 에러 발생률이 약 10%정도 됐다. 오류 발생 원인을 확인했을 때 낙관적으로 인해서 발생하고 있었다. 이 문제를 어떻게 처리하지에 대한 고민을 많이 했다가 낙관적 락이기 때문에 어쩔 수 없지라는 생각으로 진행하고 있었다. 생각보다 너무 신경쓰여 다시 생각해보다가 가상유저가 결국 Thread이기 때문에 스레드 번호를 이용해서 하는 방식으로 해결할 수 있지 않을까? 라는 생각으로 테스트하였다. 결과적으로 낙관적 락이 발생하는 것을 해결했고 이번 테스트에서 에러가 발생하지 않도록 처리되었다.
시나리오2 부하 테스트
평균 사용자 부하 테스트
테스트 결과
nGrinder
트러블 슈팅
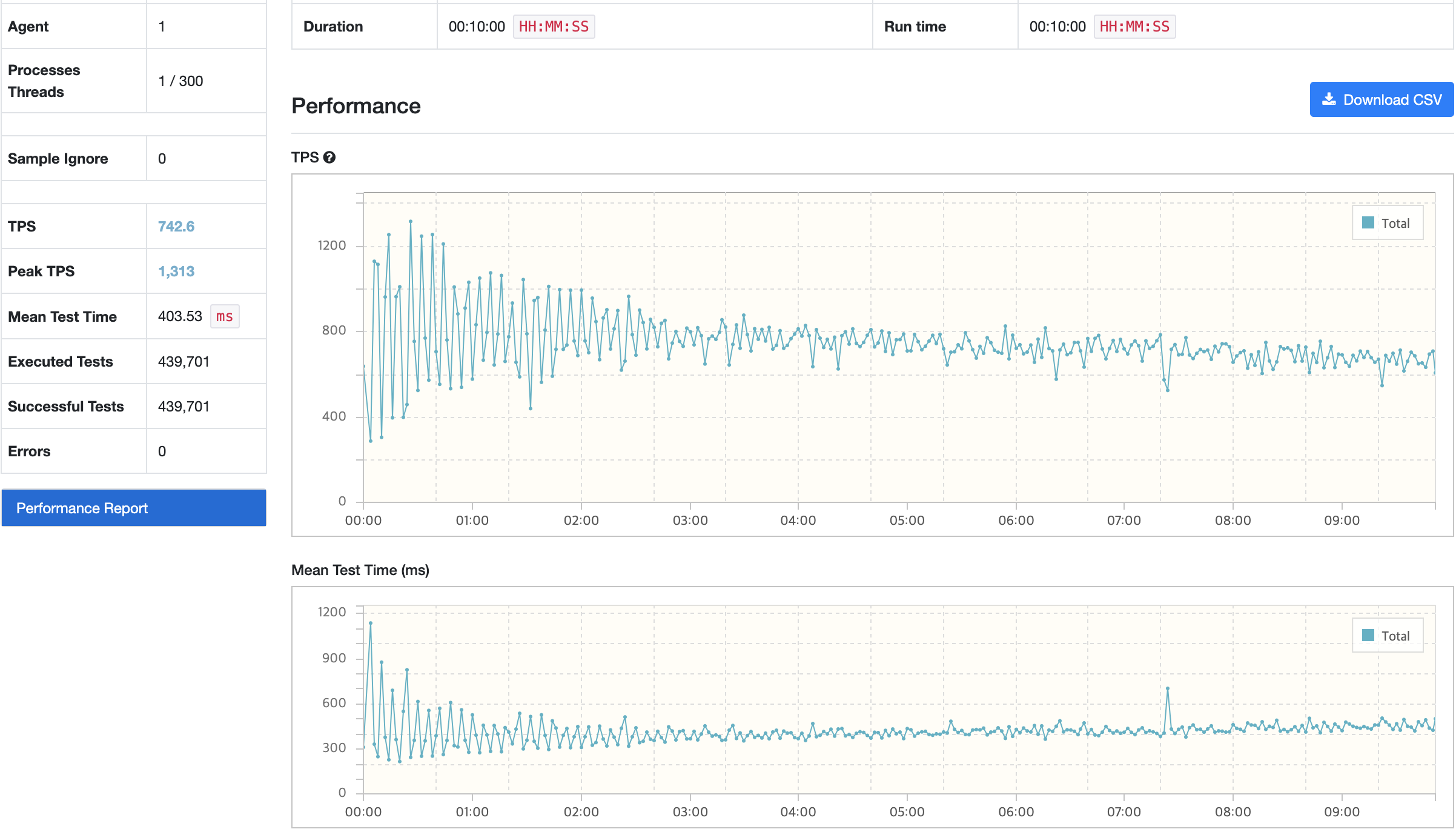
문제 상황
부하 테스트 결과를 보면 초기 TPS와 시간이 지날수록 측정되는 TPS의 폭이 큰 차이가 나는 것을 볼 수 있으며, 시간이 지날수록 TPS가 지속적으로 감소하는 현상이 발생했다.
원인 분석 및 추론
API 서버, MySQL 서버 그리고 Redis의 CPU, Memory 등 리소스 사용률의 경우 문제가 없었다. Grafana에서 Request에 대한 부분을 확인했을 때 특이한 것을 확인할 수 있었다.
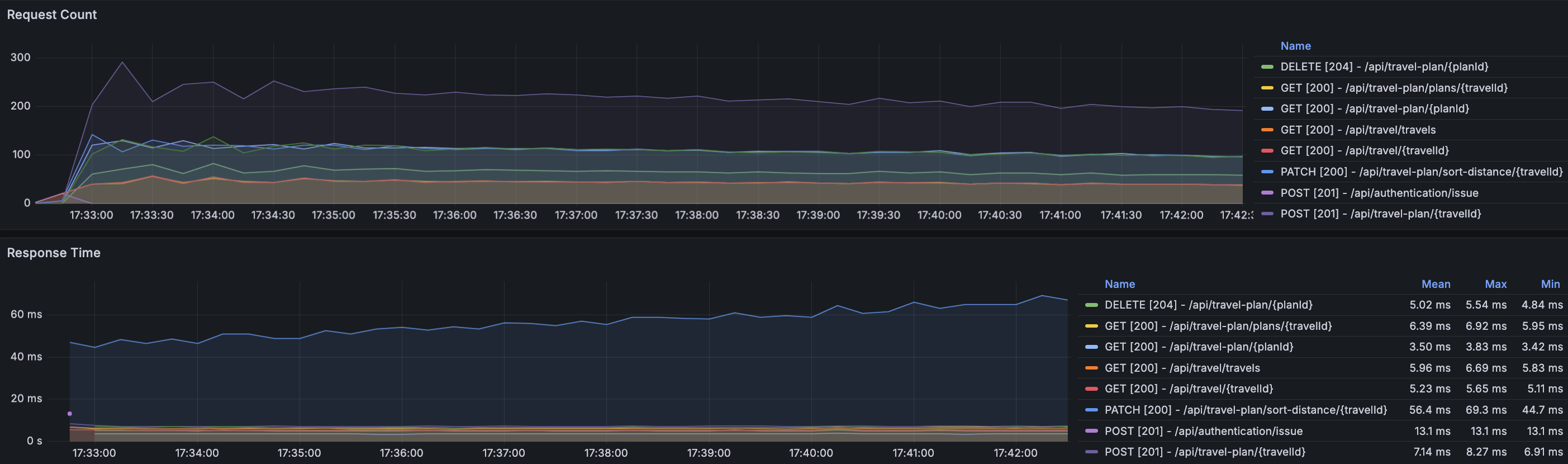
Request Count은 시간이 지날수록 감소하고 Request Time은 시간이 지날수록 증가하고 있는 API가 있으며 해당 API는 여행 계획 거리순 정렬이다.
해결 방안
여행 계획 거리순 정렬 API에서 어떠한 것이 문제인지 확인해보았다. 그리고 개선해야할 사항으로 아래 3가지 경우가 있었으며, 문제에 대한 해결방안은 아래와 같다.
- 정렬전과 후가 동일한 순서에도 Update 쿼리를 실행 → 거리순 정렬 API 동일한 순서 Update 제외
- Dirty Checking으로 한번의 수정에 DB Connection이 2번 발생 → Dirty Checking 여부에 따른 성능 재측정
- 하나의 여행 정보에만 여행 계획 데이터가 쌓이다보니 정렬해야할 데이터 상승으로 지연시간이 지속적으로 증가 → 여행 계획 추가 테스트 스크립트 제한 사항 추가하여 계획 추가 및 삭제 과정을 더 활성화
결과
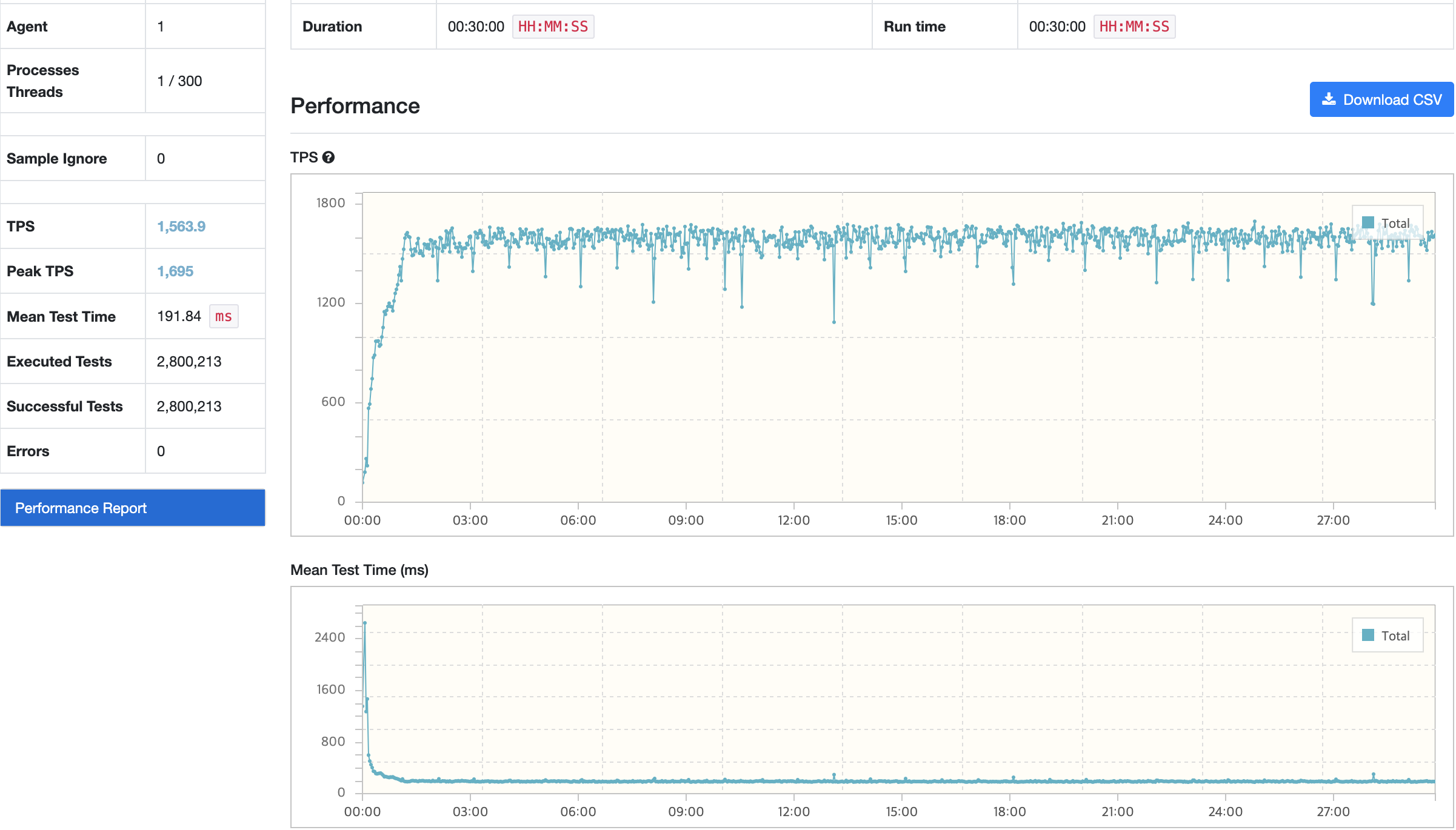
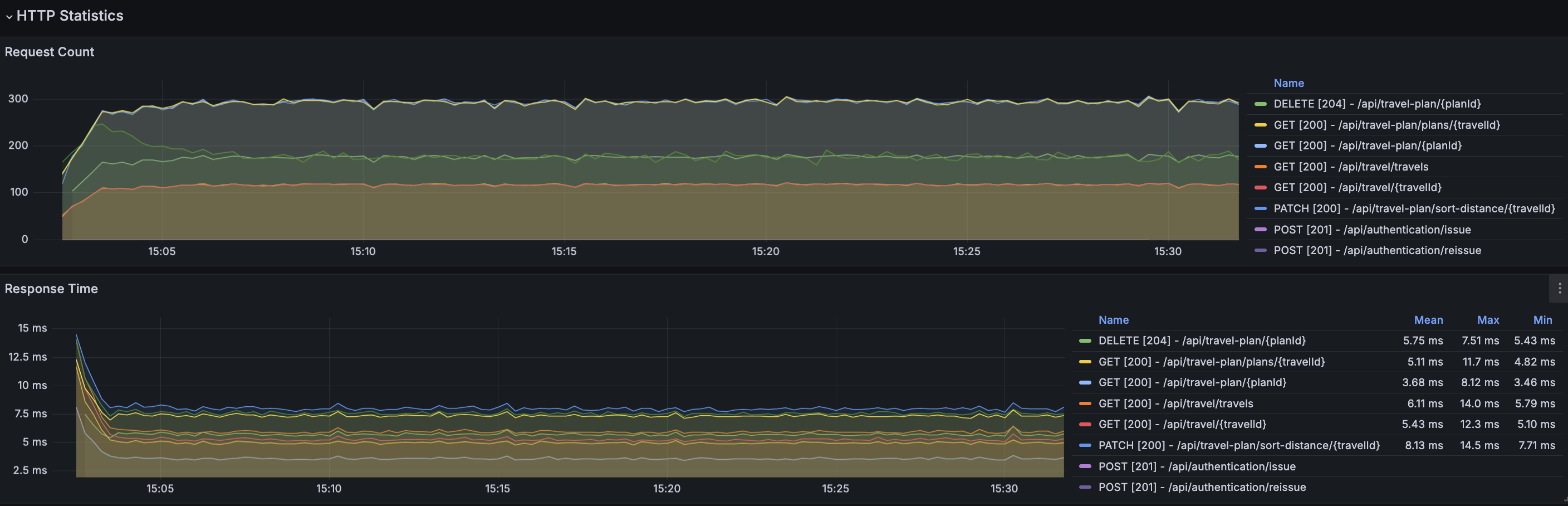
결과 분석
서버의 리소스 사용률은 전체적으로 안정된 사용률을 보이고 있다. 중간 과정에서 TPS가 눈에 띄게 감소하는 시점이 있지만, TPS, Response Time 또한 목표 수치에 만족하며 오류발생률도 0%이다.
3가지 해결방안에서 트러블 슈팅에 가장 큰 영향을 차지한 부분은 1번과 3번이다. 불필요한 로직이 동작하는 과정에서 DB 접근이 더 발생하였으며, 여행 계획에 대한 사용자 사나리오의 제한을 고려하지 않고 시나리오를 작성하여 발생하였다.
Peak 사용자 부하 테스트
테스트 결과
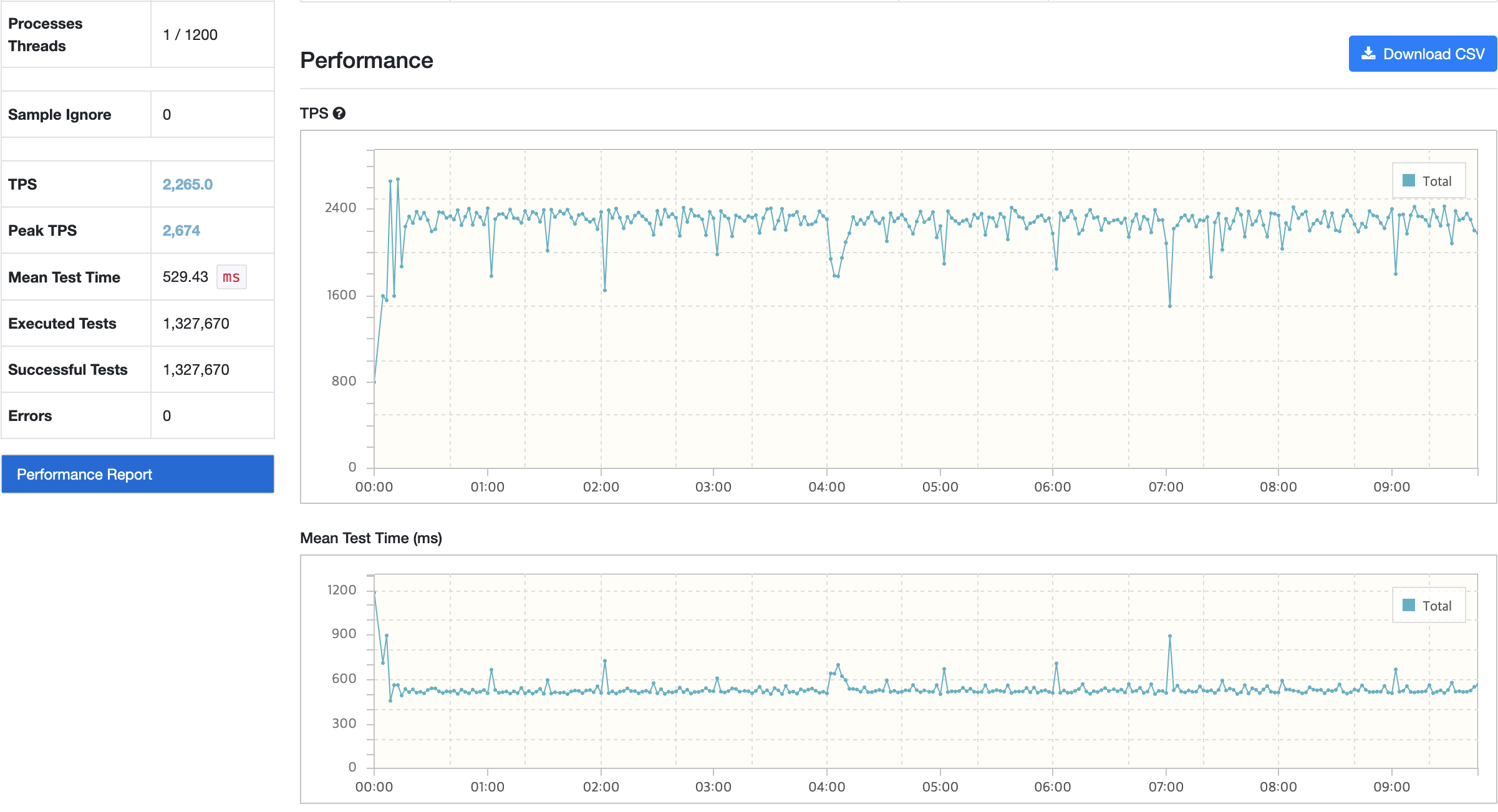
트러블 슈팅
문제 상황
시나리오2 Peak 사용자 부하 테스트 결과로 TPS와 Response Time의 경우 모두 목표 수치에 미치지 못하고 있다. 게다가, CPU 부하까지 발생하고 있다.

원인 추론 및 분석
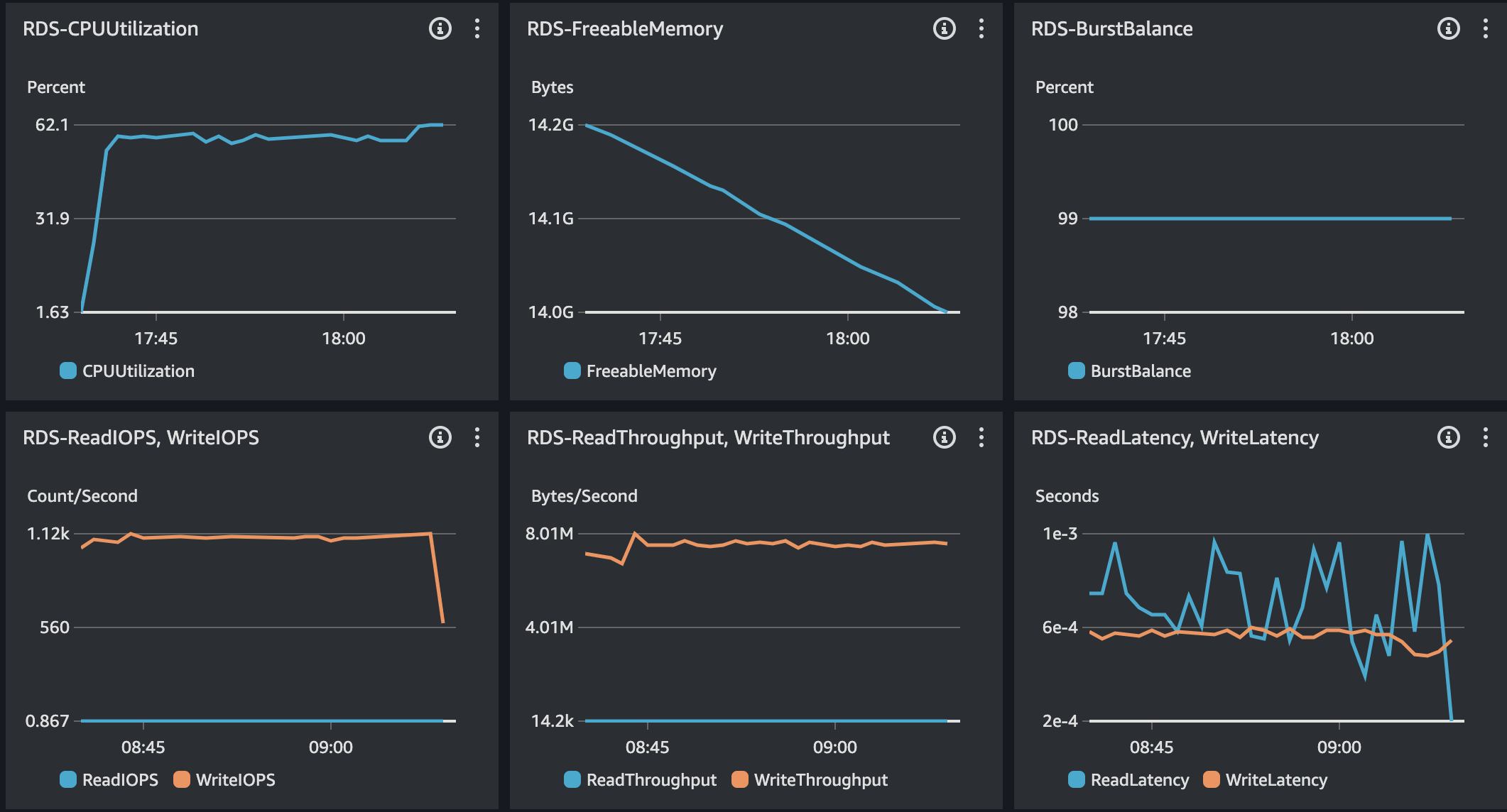
RDS를 보았을 때 CPU 사용률 75%, 메모리 사용률 약 25%, IOPS 1000에 있다. CPU 사용률의 경우 간당간당한 수준을 보이고 있지만, 다른 리소스의 사용률의 경우 안정적이다. 또한, Slow Query 발생하지 않았기에 DB에 대한 이슈는 없다고 본다.
API 서버의 CPU 외 다른 서비스에 대한 리소스 사용률은 약간 과하거나 정상적인 사용률을 보이고 있다. RDS의 CPU는 과한 부분이 있으나 결과적으로 Slow Query가 발생하지 않기에 추후에 고려해야할 대상으로 두었다.
마지막으로, 메모리 분석을 했을 때 Tomcat Thread에 작업 대기로 인한 메모리 누수 현상이 있다.
API 서버의 CPU 부하가 발생하는 점은 개선해야할 부분이지만, 과한 정도로 부하가 발생하는 것은 아니다. 그러므로, Thread의 대기를 줄이는 방안을 고려해보았다.
해결 방안
TPS, Response Time을 개선하는 방안으로 Spring Boot의 2차 캐시를 사용해보는 것을 생각해보았다. 캐시는 Storage와 비교했을 때 빠르다는 이점이 있다. 게다가, DB에 접근하는 것 부터 Latency가 발생하기에 2차 캐시로 개선을 할 수 있다고 판단했다.
다만, 2차 캐시의 경우 Memory, GC을 고려해야한다.
2차 캐시이 경우 Heap Memory를 사용하기에 캐시를 사용하면 자연스럽게 메모리 사용률이 증가할 것이다. 메모리 사용률이 증가하게되면 그만큼 GC가 더 발생할 수 있고 CPU, STW가 증가하는 현상도 있을 것이다.
결과
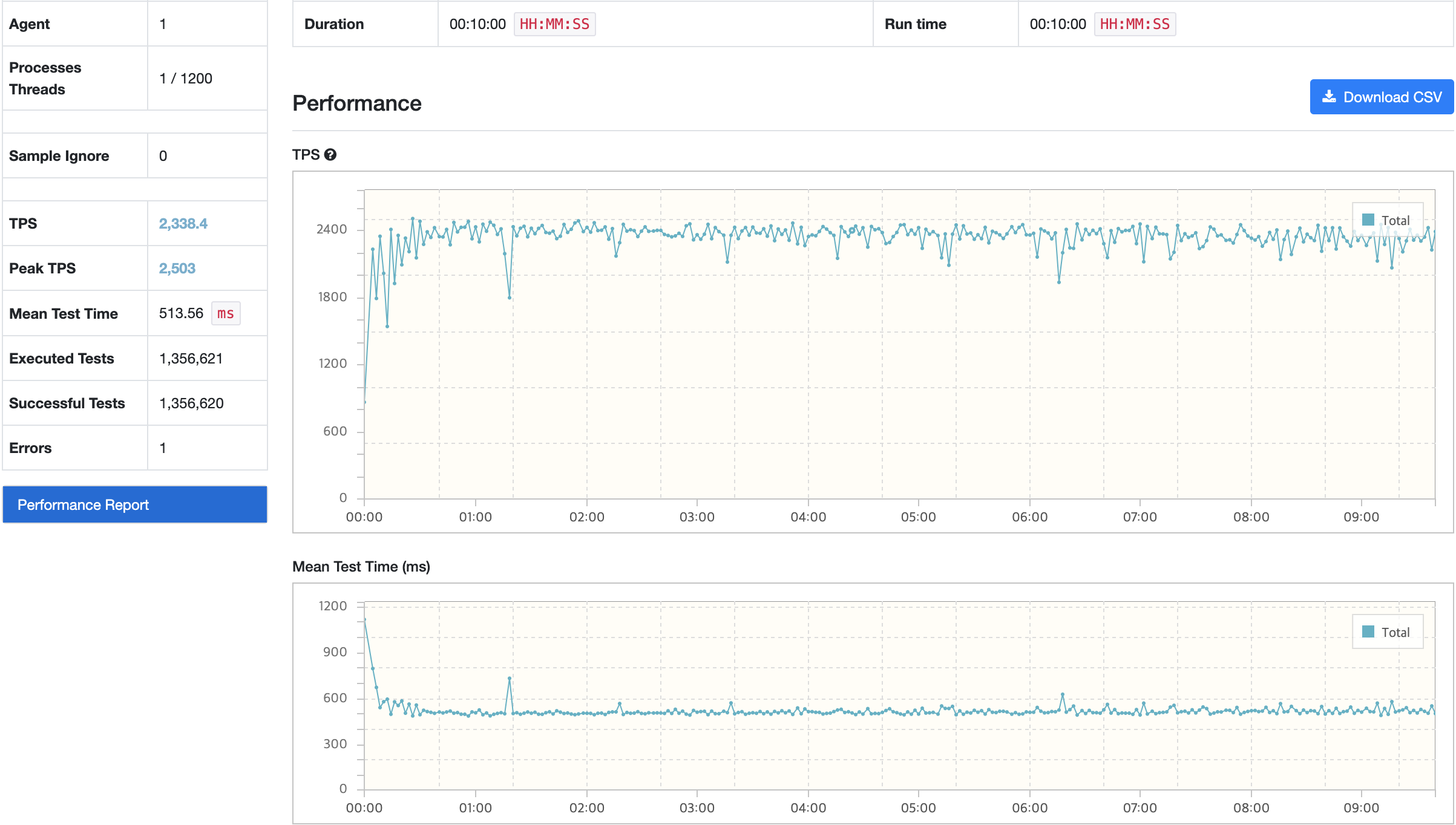

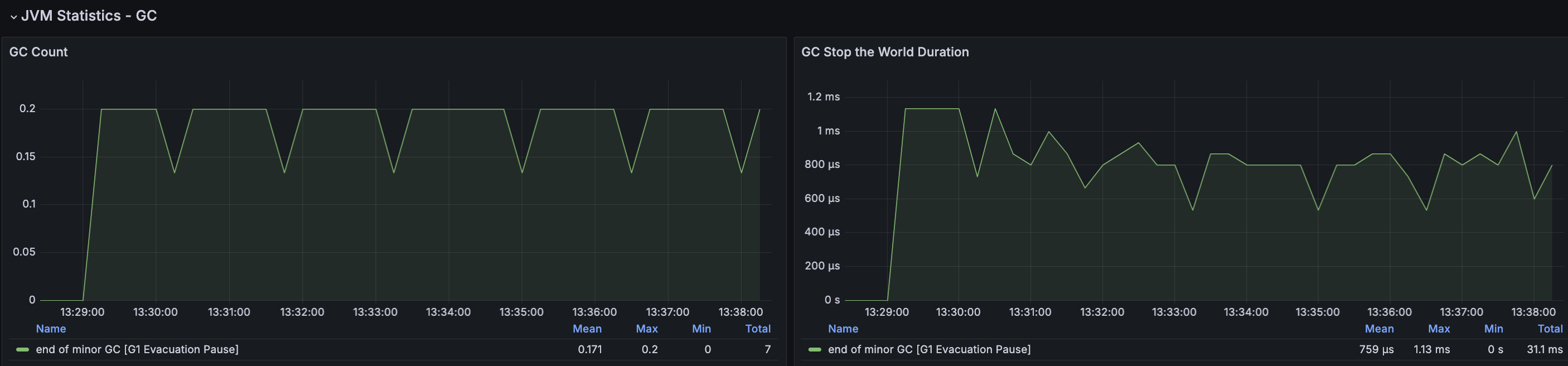
결과 분석
2차 캐시 적용 후 확인해보았을 때 아주 약간의 성능은 향상되었지만, 예상과 같이 GC 발생률이 약 50% 증가했고 STW가 증가하면서 CPU 부하가 더 발생하고 있다. 2차 캐시를 사용하는 점에서 특정 리소스 사용률의 경우 더 안좋아는게 당연하다고 생각했지만 눈으로 직접 확인하는 과정이 필요해서 테스트 해본 결과이다.
결과적으로, 해결이 되지 않았으며, 다른 방안으로 서버 Scale Up이 있지만, 마지막 시나리오3에 대해서 부하 테스트를 진행 후 고려해보려 한다.
시나리오3 부하 테스트
평균 사용자 부하 테스트
테스트 결과
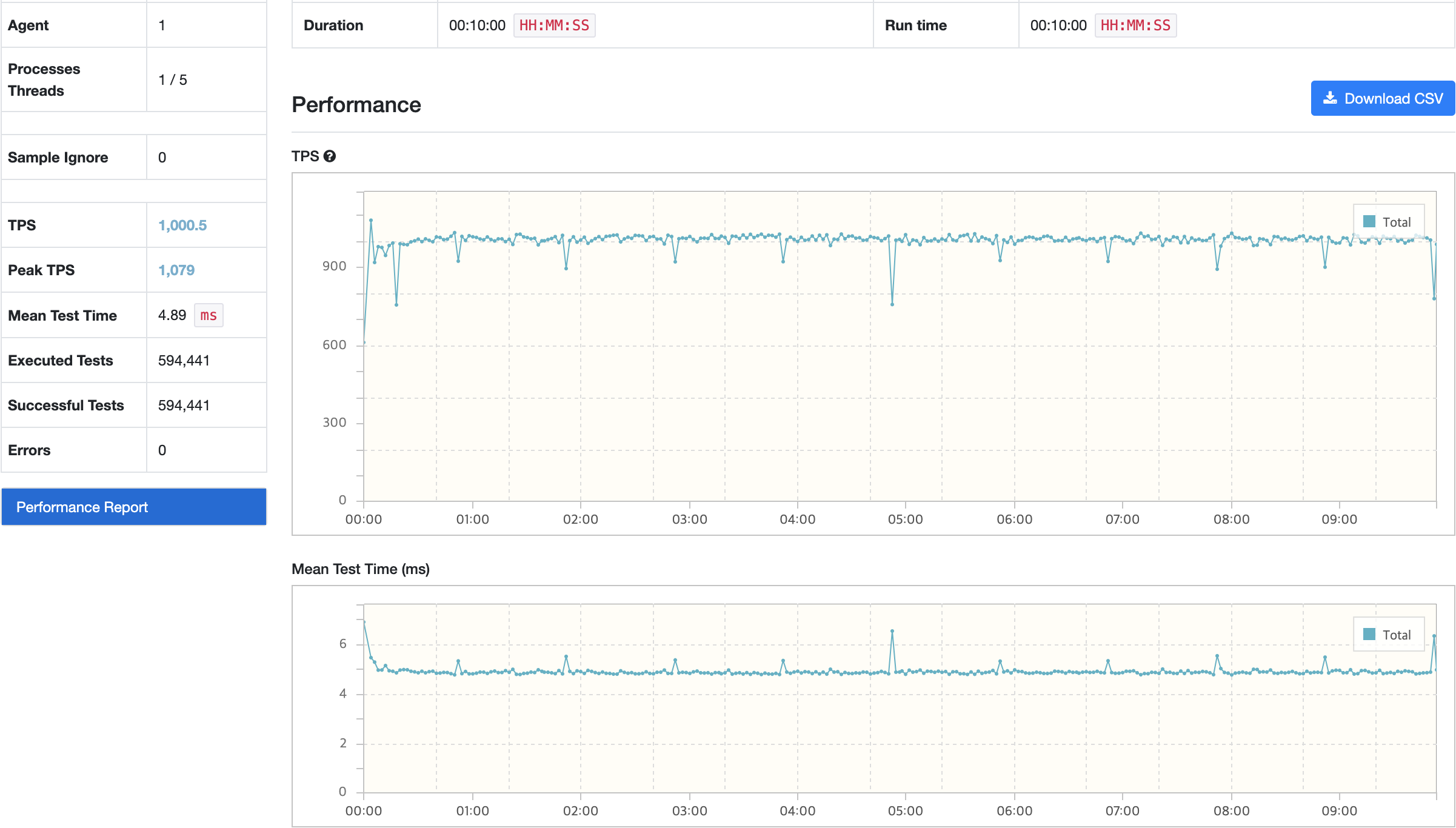
결과 분석
TPS, Response Time, 모든 서비스의 리소스 사용률의 경우 안정적으로 운영되고 있다.
Peak 사용자 부하 테스트
테스트 결과
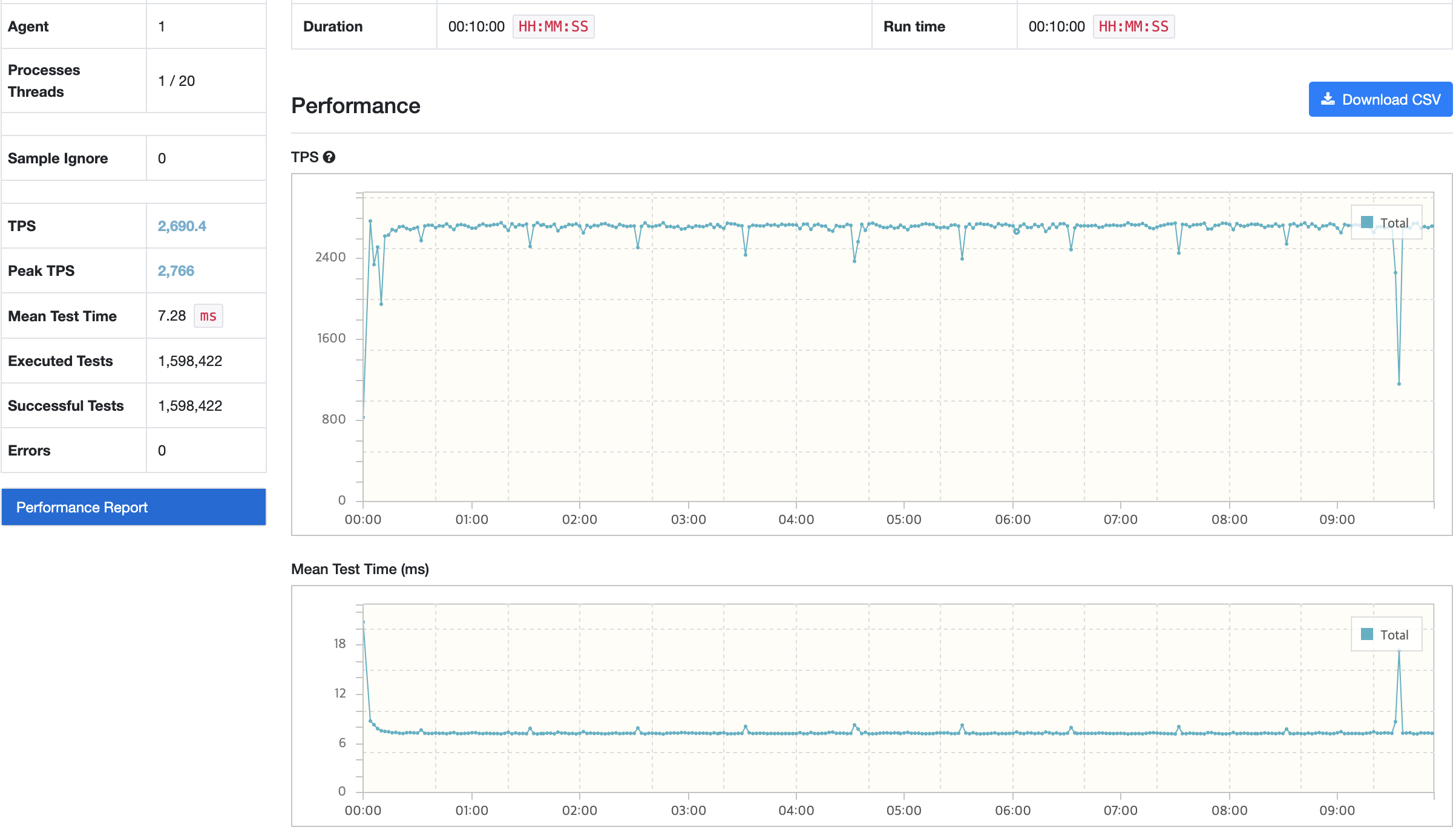

결과 분석
CPU를 제외한 리소스 사용률은 전체적으로 정상적인 사용률을 보이고 있다. 메모리 분석에서 시나리오2와 동일하게 Worker Thread의 대기로 메모리 누수가 발생하고 있었으며 시나리오2에서의 부하 테스트 과정에서 서버 Scale Up이 필요한 점을 고려해 API 서버 Scale Up이 필요하다.
시나리오2,3 - 성능 개선 사전 작업
API 서버 Scale Up
| 구분 | Before | After |
|---|---|---|
| 인스턴스 유형 | c5a.xlarge | c5a.2xlarge |
| vCPU | 4(2코어) | 8(4코어) |
| Memory | 8Gb | 15Gb |
| Network | 최대 10GiB | High |
| 비용 | 시간당 0.1720USD | 시간당 0.4540USD |
G1 GC 기본 튜닝
- Heap Memory 사용률 : 약 85%
- ParallelGCThreads : 4 → 6
- ConcGCThreads : 1 → 2
시나리오2,3 - 성능 개선 후 Peak 사용자 부하 테스트
시나리오2
테스트 결과
nGrinder
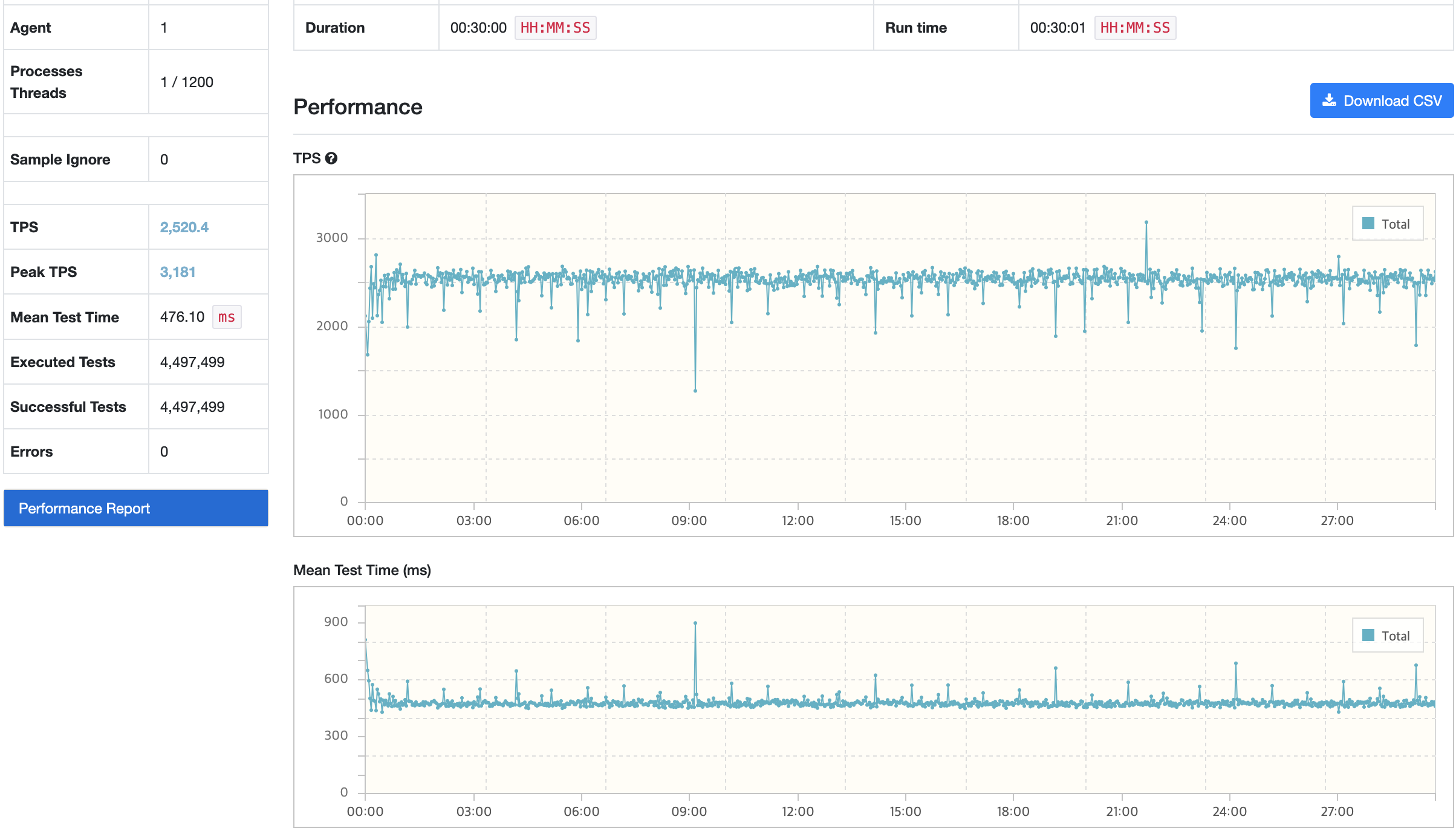
API 서버

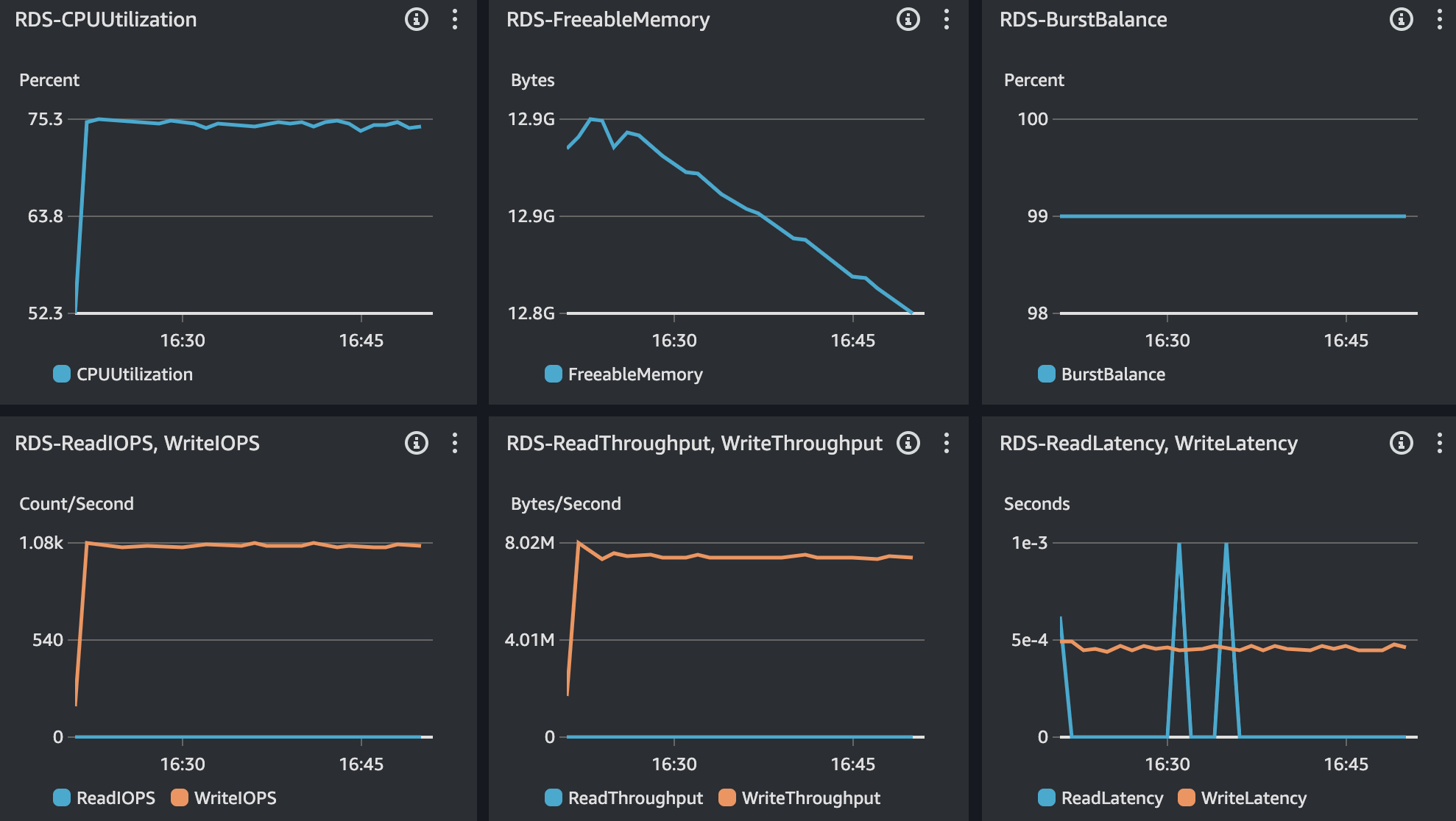
RDS - MySQL
시나리오3
테스트 결과
nGrinder
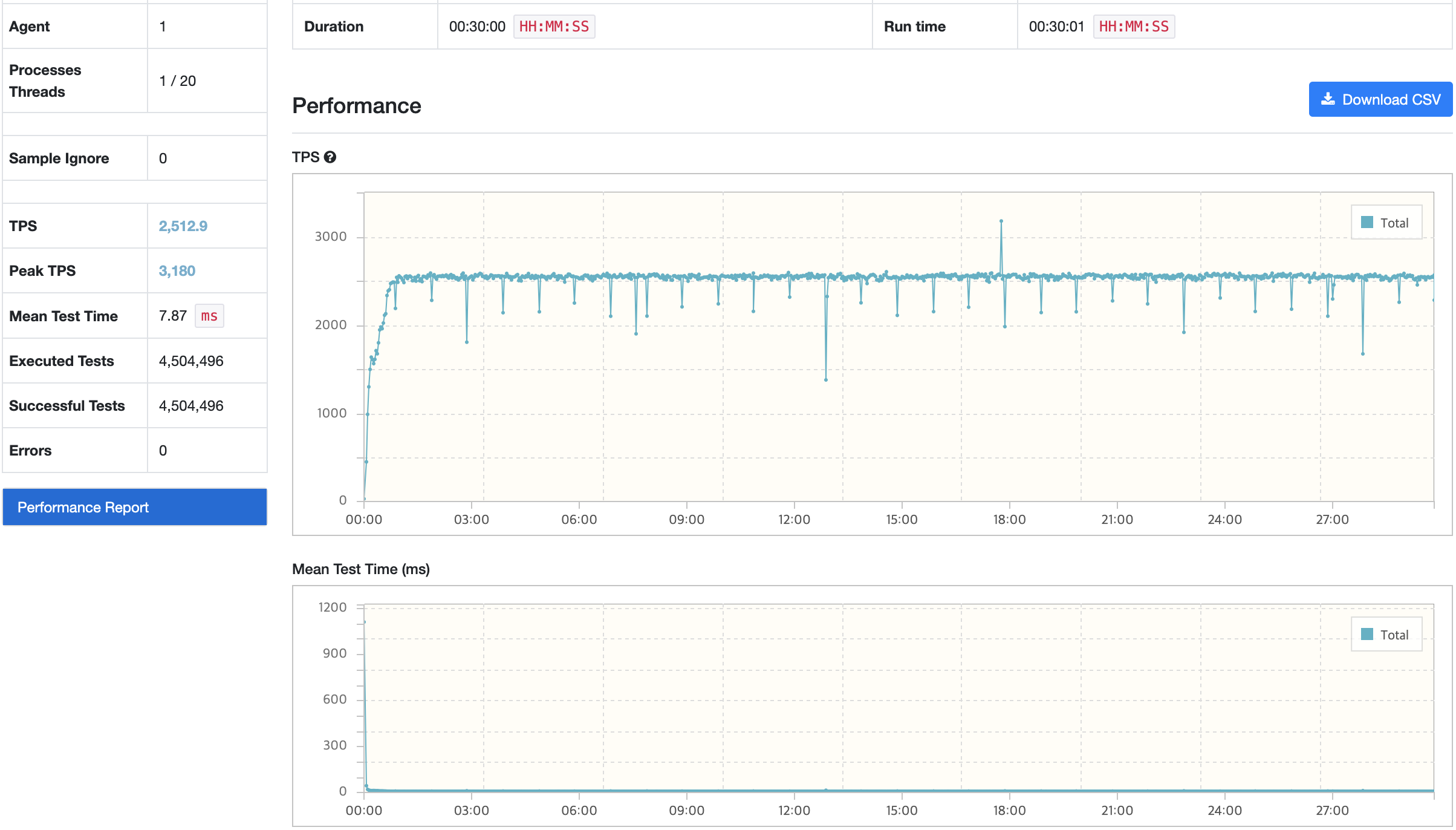
API 서버

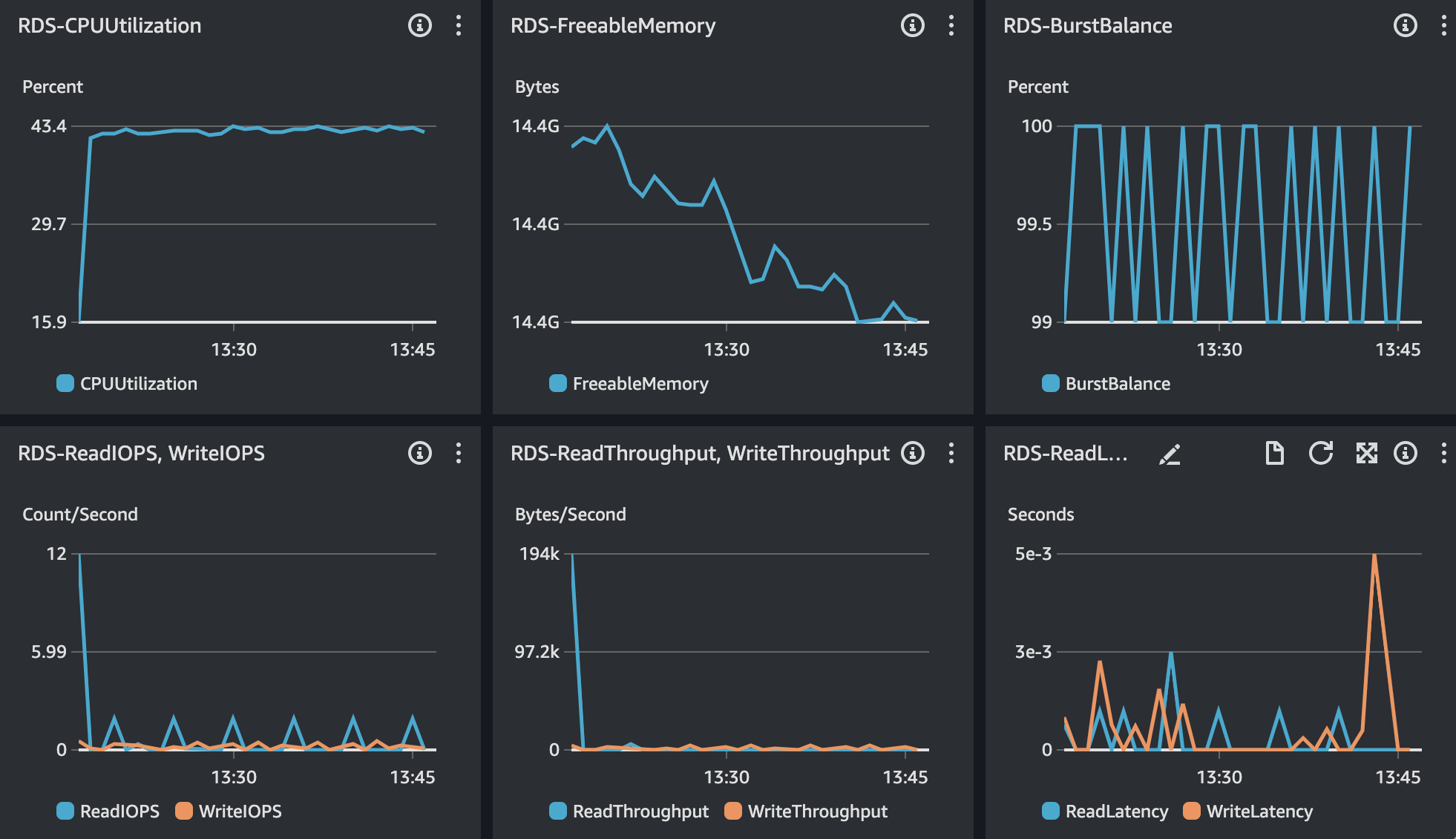
RDS - MySQL
시나리오2, 3 테스트 결과 분석
시나리오2
TPS가 주기적으로 감소하며 Response Time 또한 이에 맞게 증가하는 현상이 있다. 전반적인 리소스 사용률은 안정적이지만 API 서버가 Scale Up 되어 처리량이 안정적이게 되면서 RDS에 그만큼 부하가 발생하게 되었다. 앞선 트러블 슈팅 과정에서 발생해왔던 DB 및 쿼리 튜닝은 모두 진행한 상태이며, 결과적으로 DB 서버에 대한 Scale Up이 필요해 보인다.
시나리오3
TPS가 급격하게 감소하는 현상이 있지만, TPS 및 Response Time은 모두 목표 수치에 만족한다. 추가로 CPU Load Average 또한 과도한 사용률을 보이지 않고 있어 시나리오3에 대한 이슈는 해결되었다.
RDS Scale Up 후 시나리오2 - Peak 사용자 부하 테스트
Scale Up
| 구분 | Before | After |
|---|---|---|
| 인스턴스 유형 | db.t4g.xlarge | db.t4g.2xlarge |
| CPU | 4(2코어) | 8(4코어) |
| Memory | 16GiB | 32GiB |
| Network | 2,780Mbps | 2,780Mbps |
| 비용 | 시간당 0.406USD | 시간당 0.813USD |
테스트 결과
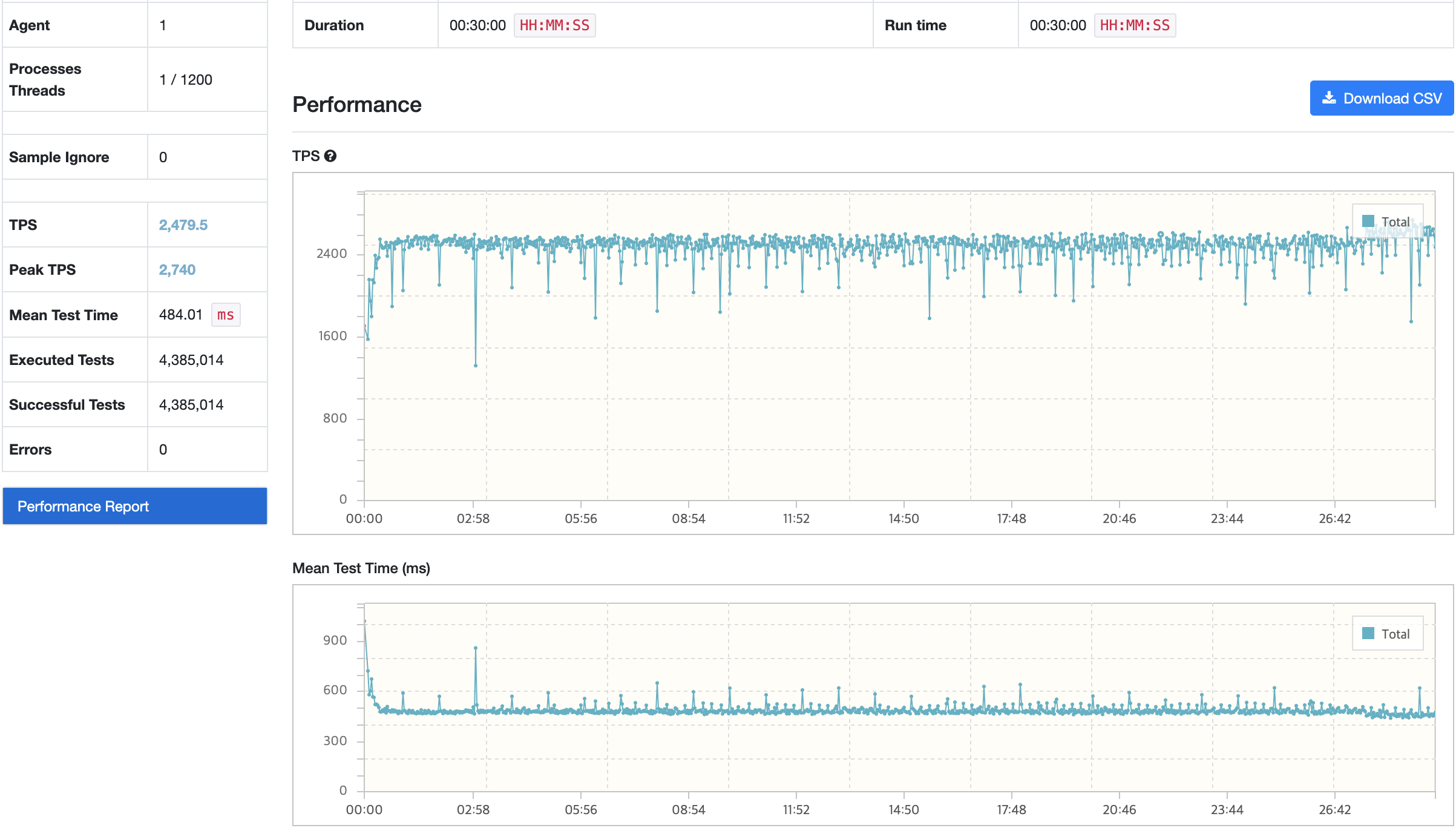
nGrinder
RDS - MySQL
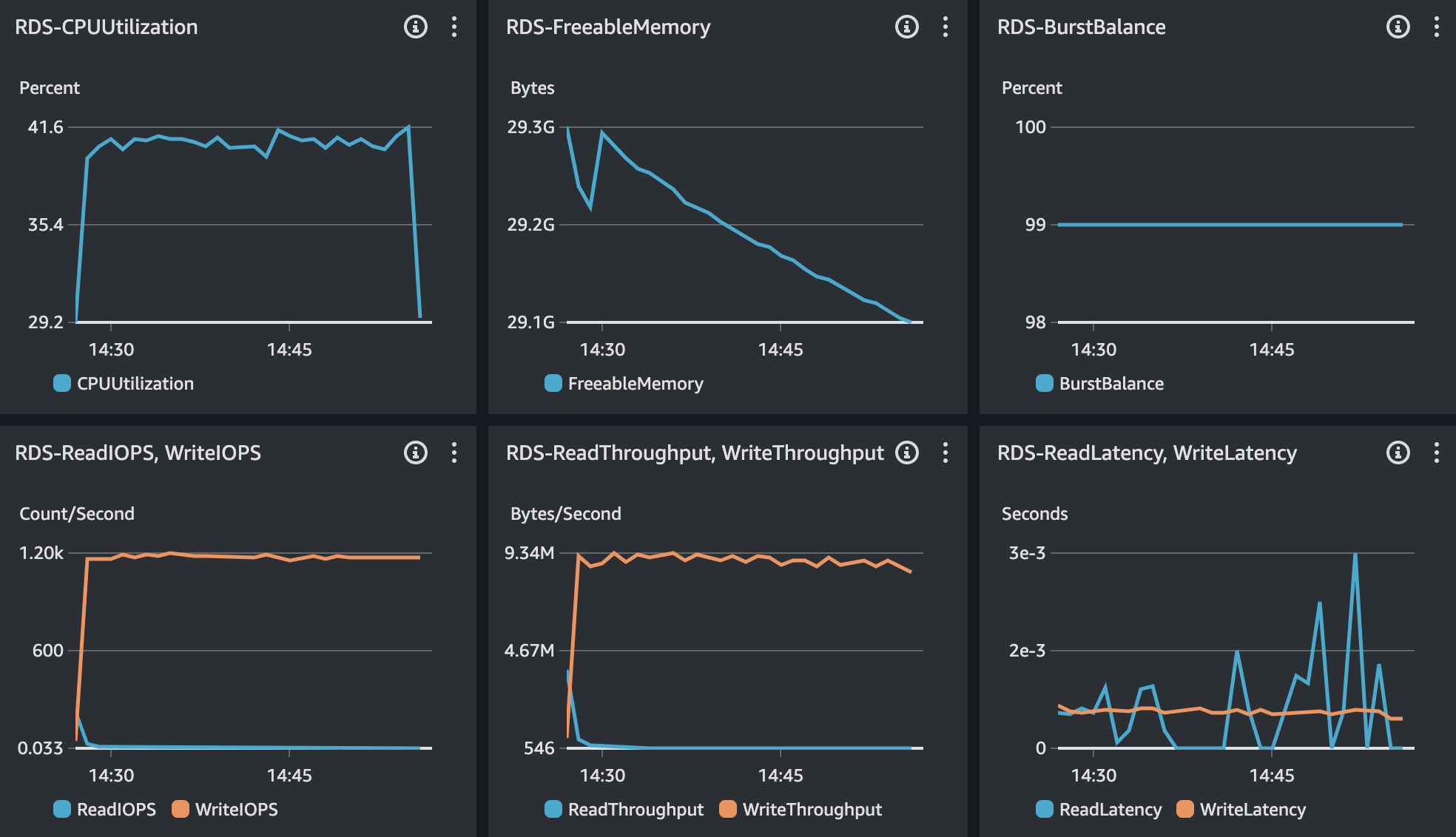
결과 분석
TPS, Response Time의 경우 기존과 동일한 수준으로 테스트 되었으며, RDS의 CPU의 경우 40% 정도로 사용률을 보이고 있어 서버 및 RDS 등 전체 인프라에서 안정적인 리소스 사용률을 보이고 있다.
TPS와 Response Time는 증감 현상이 있으나, 평균 목표 수치는 만족하고 있다. 이에 앞으로 진행할 내구성 테스트, 스트레스 테스트, GC 튜닝 과정에서 처리해보고자 한다.
마무리
시나리오1부터 3까지 부하 테스트 과정에서 서버 모니터링 및 성능 개선을 진행하면서 TPS, Response Time 등 목표 수치를 맞추기위해 성능 개선 작업을 진행했으며, 여러 리소스에 대한 부하를 개선하기서 필요에 따라 서버 Scale Up을 통해 부하 테스트를 진행했다.
처음 부하 테스트를 진행하면서 생각지도 못한 부분으로 인해 난항을 겪기도 했다.
첫 번째는, 목표하는 RPS, TPS, VUser이다. RPS를 계산할때 한번의 시나리오를 완료하는데 걸리는 시간과 TPS와 RPS가 어떤 곳에서는 같다라고하며 어떤 곳에서는 다르다라는 의미가 있어 많이 헷갈렸고 계산을 해보면서 이 수치가 맞을까? 라는 생각에 정리도 오래 걸렸었다.
두 번째는, Tomcat Worker Thread이다. 톰캣의 경우 기본 200의 작업 스레드로 설정하지만, “다 이유가 있으니 이렇게 설정했겠지?” 라는 당연한 생각에 부하 테스트를 진행할 때마다 너무 과도한 TPS가 집계되고 응답시간은 왜이렇게 낮을까?, CPU 부하는 왜이렇게 많이 걸릴까? 라는 생각을 계속하게되면서 불필요한 여러 작업(서버 Scale Up/Out, AWS 서버 리소스 사용에 대한 제한 확인 등) 시도해보았다. 그리고 시나리오1에 대한 Smoke 테스트를 진행했을 때 시나리오 스크립트를 수십번을 엎기도 했었다.
이러한 과정 끝에서 목표에 맞는 정보를 찾고 필요한 수치들을 집계했으며, 스크립트 또한 사용자라면 이 서비스를 어떻게 사용했을지 대한 기준으로 계속해서 수정하고 테스트를 진행하면서 부하 테스트를 마무리하였다.
이번 부하 테스트의 경우 30분 동안만 테스트를 진행했으며 이 테스트 시간동안에는 모든 시나리오가 안정적인 결과가 나왔다. 다음글에서는 내구성 테스트를 진행하여 좀 더 장기적으로 테스트를 했을 때 어떠한 잠재적인 이슈가 있을지 보고자한다.